标签:
SparkStreaming 源码分析 一节中从源码角度,描述了Streaming执行时代码的调用过程。下边就接收转化阶段过程再简单分析一下,为分析backpressure作准备。
SparkStreaming的全过程分为两个阶段:数据接收转化阶段和Job产生与执行阶段。两个阶段通过数据接收转化阶段产生的Block联系在一起。下图是依据对基于Recevier的数据接收源转化部分源码分析所做。
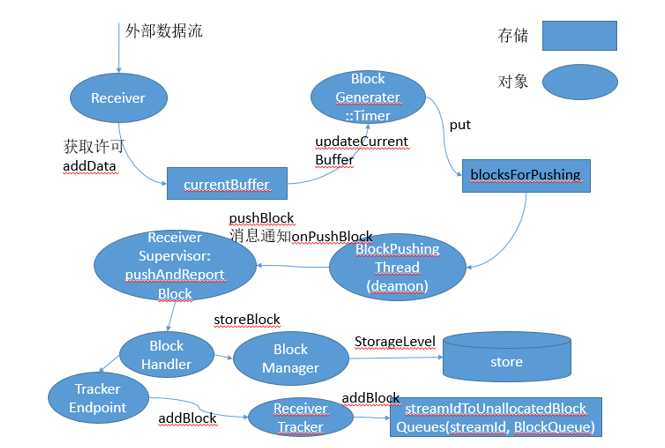
数据接收转化过程可以分为如下几个关键步骤:
Receiver接收外部数据流,其将接收的数据流交由BlockGenerator存储在ArrayBuffer中,在存储之前会先获取许可(由“spark.streaming.receiver.maxRate”指定,spark 1.5之后由backpressure进行自动计算,代表可以存取的最大速率,每存储一条数据获取一个许可,若未获取到许可接收将阻塞)。
BlockGenerater中定义一Timer,其依据设置的Interval定时将ArrayBuffer中的数据取出,包装成Block,并将Block存放入blocksForPushing中(阻塞队列ArrayBlockingQueue),并将ArrayBuffer清空。
BlockGenerater中的blockPushingThread线程从阻塞队列中取出取出block信息,并以onPushBlock的方式将消息通过监听器(listener)发送给ReceiverSupervisor.
ReceiverSupervisor收到消息后,将对消息中携带数据进行处理,其会通过调用BlockManager对数据进行存储,并将存储结果信息向ReceiverTracker汇报
ReceiverTracker收到消息后,将信息存储在未分配Block队列(streamidToUnallocatedBlock)中,等待JobGenerator生成Job时将其指定给RDD。
标签:
原文地址:http://www.cnblogs.com/barrenlake/p/5349921.html