标签:
一起啃PRML - 1.2.4 The Gaussian distribution 高斯分布 正态分布
@copyright 转载请注明出处 http://www.cnblogs.com/chxer/
我们将用整个第二章来研究各种各样的概率分布以及它们的性质。然而,在这里介绍连续变量一种最重要的概率分布是很方便的。这种分布就是正态分布(normal distribution)或者高斯分布(Gaussian distribution)。在其余章节中(事实上在整本书中),我们将会经常用到这种分布。
正态分布是这么定义的:
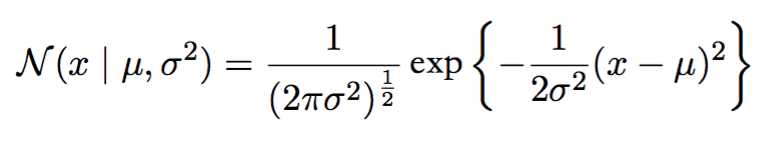
图像长成这样:
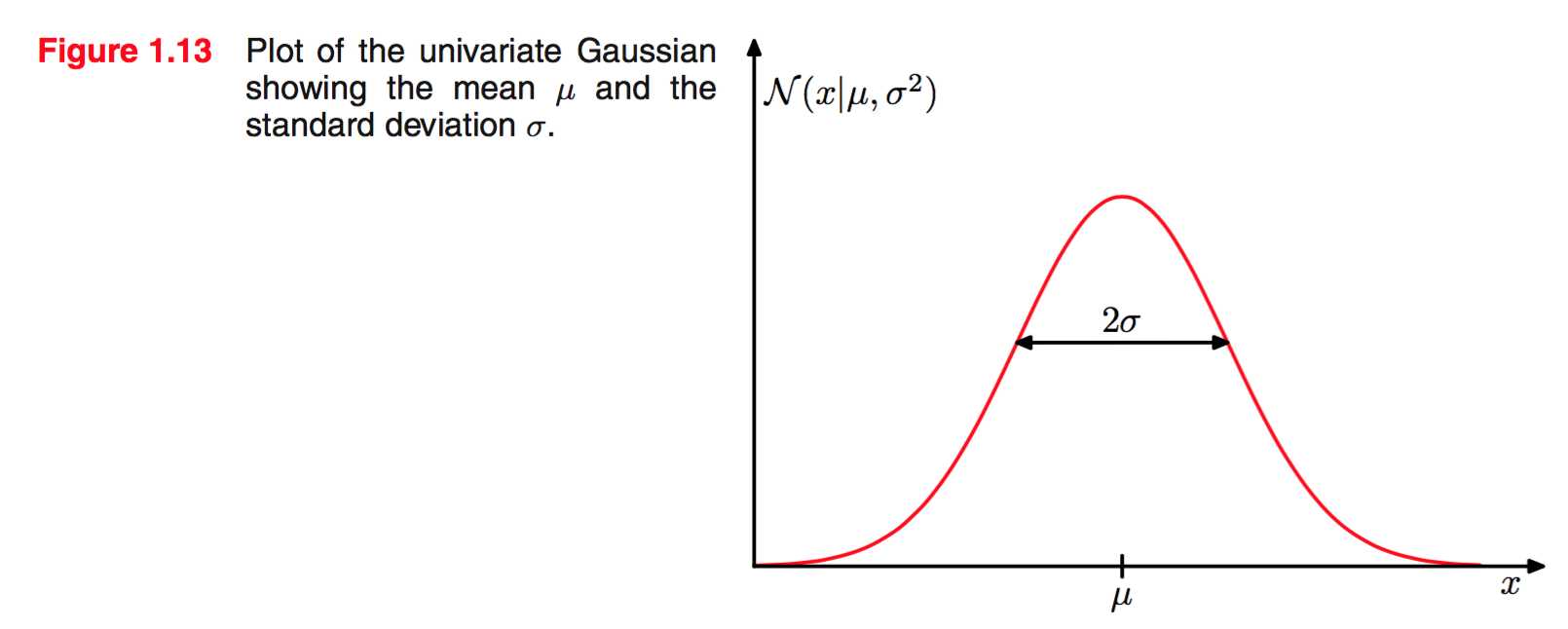
我们待会被数学折磨完后再来了解这些参数的意义。
先来看看正态分布几个性质:全正且归一
![]()
![]()
好,接下来我们来算一下正态分布的期望以及二阶矩的期望以及方差。
先从简单的一阶期望开始:
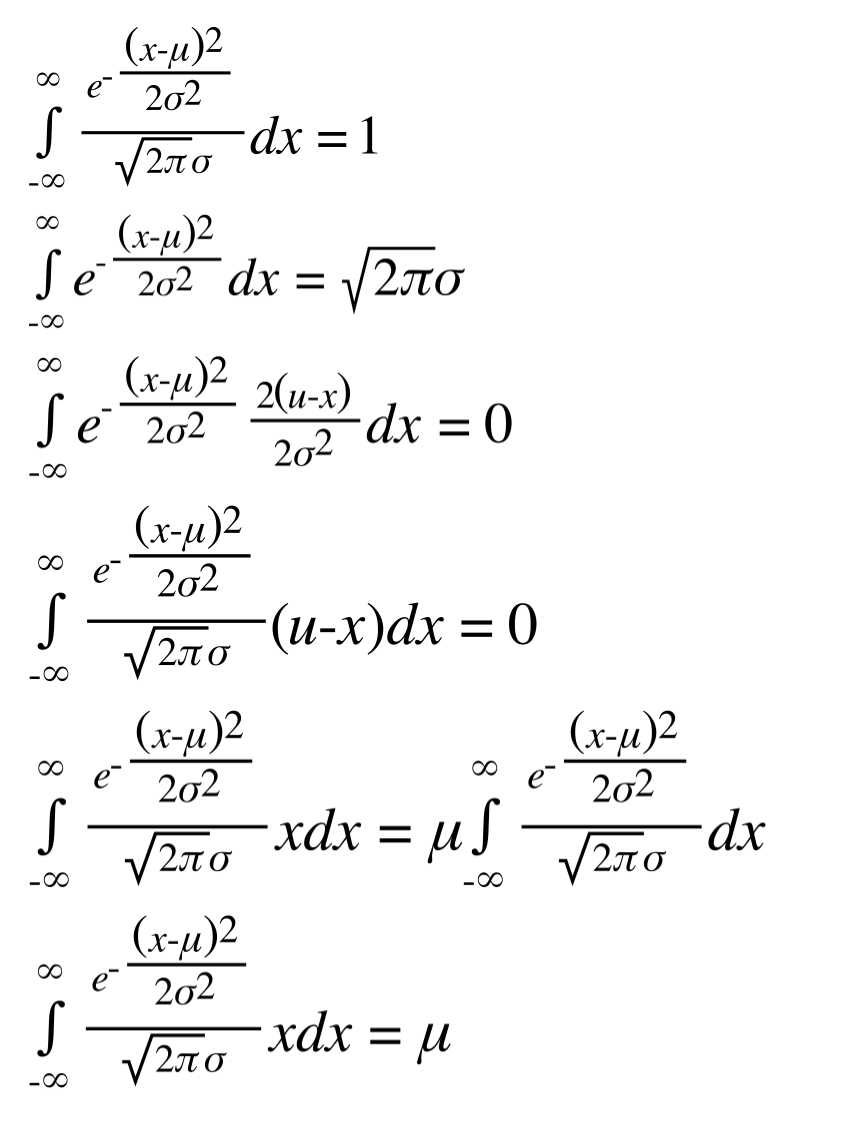
然后我们就磨出来了,喜大普奔。
二阶矩似乎道理是一样的。以后再补上吧。
![]()
那么我们就把方差求出来了:
![]()
现在我们就知道每一个参数的意义了:
μ,被叫做均值(mean),以及σ2,被叫做方差(variance)。方差的平方 根,由σ给定,被叫做标准(standard deviation)。方差的倒数,记作β = 1 ,被叫做精度。
分布的最大值是众数。对于正态分布来说,众数是等于均值的。
我们也对D维向量x的正态分布感兴趣(不包括我),它是这么定义的:
![]()
现在假定我们有一个观测的数据集x = (x1, . . . , xN )T ,表示标量变量x的N次观测。注意, 我们使用一个字体不同的x来和向量变量(x1, . . . , xD)T 作区分,后者记作x。我们假定各次观 测是独立地从高分布中抽取的,分布的均值μ和方差σ2未知,我们想根据数据集来确定这 参数。独立地从相同的数据中抽取的数据点被称为独立同分布(independent and identically distributed),通常缩写成i.i.d.。我们已看到两个独立事件的联合概率可以由各个事件的边缘概率的乘积得到。由于我们的数据集x是独立同布的,因此给定μ和σ2,我们可以给出数据集的概率:
![]()
我们就得到了正态分布的似然函数。我们取对数就可以得到对数似然函数:
![]()
我们分别关于两个参数最大化对数似然函数,就得到了样本均值和样本方差:
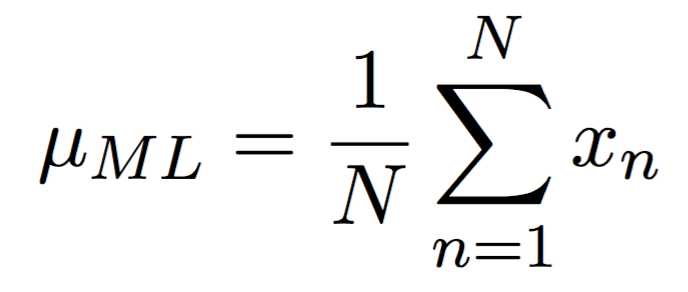
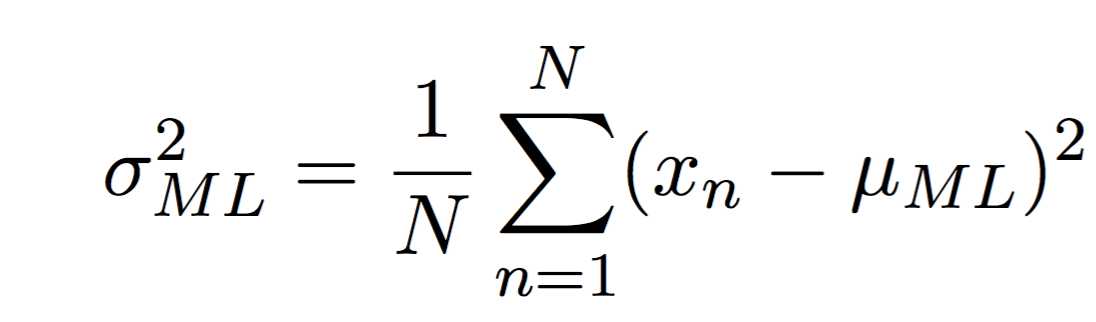
事实上,我们发现样本均值应该是无偏的,也就是有:
![]()
对于样本方差,我们则需要考量。

当数据点的数量N增大时,最大似然解的偏移会变得不太严重,并且在极 限N → ∞的情况下,方差的最大似然解与产生数据的分布的真实方差相等。在实际应用中,只要N 的值不太小,那么偏移的现象不是个大问题。然而,在本书中,我们感兴趣的是带有很多参数的复杂模型。这些模型中,最大似然的偏移问题会更加严重。实际上,我们会看到,最大似然的偏移问题是我们在多项式曲线拟合问题中遇到的过拟合问题的核心。
一起啃PRML - 1.2.4 The Gaussian distribution 高斯分布 正态分布
标签:
原文地址:http://www.cnblogs.com/chxer/p/5351734.html