标签:
(1) XPath Axes(坐标轴)
XML 实例文档
我们将在下面的例子中使用此 XML 文档:
1 <?xml version="1.0" encoding="ISO-8859-1"?> 2 3 <bookstore> 4 5 <book> 6 <title lang="eng">Harry Potter</title> 7 <price>29.99</price> 8 </book> 9 10 <book> 11 <title lang="eng">Learning XML</title> 12 <price>39.95</price> 13 </book> 14 15 </bookstore>
XPath 轴
轴可定义相对于当前节点的节点集。
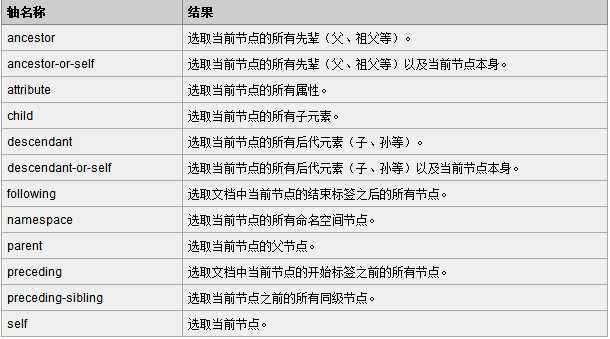
位置路径表达式
位置路径可以是绝对的,也可以是相对的。
绝对路径起始于正斜杠( / ),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:
绝对位置路径 /step/step/......
相对位置路径 /step/step/......
每个步均根据当前节点集之中的节点来进行计算。
步(step)包括:
* 轴(axis)
定义所选节点与当前节点之间的树关系
*节点测试(node-test)
识别某个轴内部的节点
*零个或者更多谓语(predicate)
更深入地提炼所选的节点集
步的语法:轴名称::节点测试[谓语]
实例
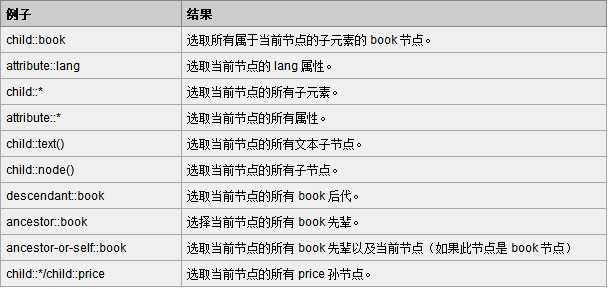
(2)XPath 运算符
XPath 表达式可返回节点集、字符串、逻辑值以及数字。
XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
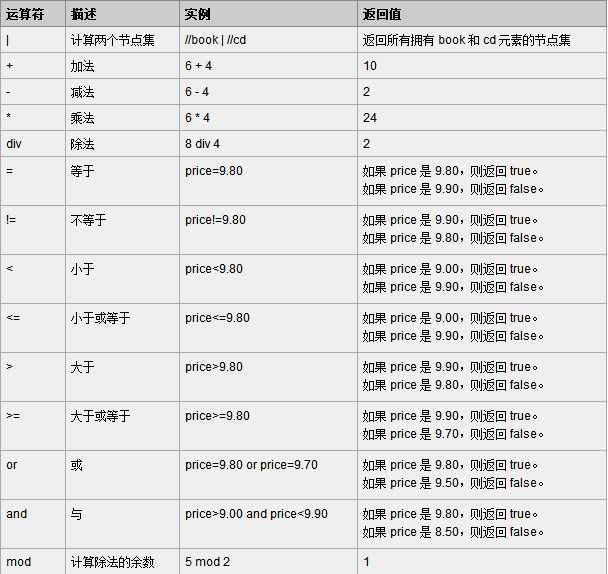
(3)XPath实例
XML实例文档
我们将在下面的例子中使用这个 XML 文档:
"books.xml" :
1 <?xml version="1.0" encoding="ISO-8859-1"?> 2 3 <bookstore> 4 5 <book category="COOKING"> 6 <title lang="en">Everyday Italian</title> 7 <author>Giada De Laurentiis</author> 8 <year>2005</year> 9 <price>30.00</price> 10 </book> 11 12 <book category="CHILDREN"> 13 <title lang="en">Harry Potter</title> 14 <author>J K. Rowling</author> 15 <year>2005</year> 16 <price>29.99</price> 17 </book> 18 19 <book category="WEB"> 20 <title lang="en">XQuery Kick Start</title> 21 <author>James McGovern</author> 22 <author>Per Bothner</author> 23 <author>Kurt Cagle</author> 24 <author>James Linn</author> 25 <author>Vaidyanathan Nagarajan</author> 26 <year>2003</year> 27 <price>49.99</price> 28 </book> 29 30 <book category="WEB"> 31 <title lang="en">Learning XML</title> 32 <author>Erik T. Ray</author> 33 <year>2003</year> 34 <price>39.95</price> 35 </book> 36 37 </bookstore>
加载 XML 文档
所有现代浏览器都支持使用 XMLHttpRequest 来加载 XML 文档的方法。
针对大多数现代浏览器的代码:
var xmlhttp=new XMLHttpRequest()
针对古老的微软浏览器(IE 5 和 6)的代码:
var xmlhttp=new ActiveXObject("Microsoft.XMLHTTP")
选取节点
不幸的是,Internet Explorer 和其他处理 XPath 的方式不同。
在我们的例子中,包含适用于大多数主流浏览器的代码。
Internet Explorer 使用 selectNodes() 方法从 XML 文档中的选取节点:
xmlDoc.selectNodes(xpath);
Firefox、Chrome、Opera 以及 Safari 使用 evaluate() 方法从 XML 文档中选取节点:
xmlDoc.evaluate(xpath, xmlDoc, null, XPathResult.ANY_TYPE,null);
选取所有 title
下面的例子选取所有 title 节点:
/bookstore/book/title
1 2 <html> 3 <body> 4 <script type="text/javascript"> 5 function loadXMLDoc(dname) 6 { 7 if (window.XMLHttpRequest) 8 { 9 xhttp=new XMLHttpRequest(); 10 } 11 else 12 { 13 xhttp=new ActiveXObject("Microsoft.XMLHTTP"); 14 } 15 xhttp.open("GET",dname,false); 16 xhttp.send(""); 17 return xhttp.responseXML; 18 } 19 20 xml=loadXMLDoc("../example/xmle/books.xml"); 21 path="/bookstore/book/title" 22 // code for IE 23 if (window.ActiveXObject) 24 { 25 var nodes=xml.selectNodes(path); 26 27 for (i=0;i<nodes.length;i++) 28 { 29 document.write(nodes[i].childNodes[0].nodeValue); 30 document.write("<br />"); 31 } 32 } 33 // code for Mozilla, Firefox, Opera, etc. 34 else if (document.implementation && document.implementation.createDocument) 35 { 36 var nodes=xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null); 37 var result=nodes.iterateNext(); 38 39 while (result) 40 { 41 document.write(result.childNodes[0].nodeValue); 42 document.write("<br />"); 43 result=nodes.iterateNext(); 44 } 45 } 46 </script> 47 48 </body> 49 </html>
Harry Potter
Everyday Italian
Learning XML
XQuery Kick Start
选取第一个 book 的 title
下面的例子选取 bookstore 元素下面的第一个 book 节点的 title:
/bookstore/book[1]/title
这里有一个问题。上面的例子在 IE 和其他浏览器中输出不同的结果。
IE5 以及更高版本将 [0] 视为第一个节点,而根据 W3C 的标准,应该是 [1]。
为了解决 IE5+ 中 [0] 和 [1] 的问题,可以为 XPath 设置语言选择(SelectionLanguage)。
下面的例子选取 bookstore 元素下面的第一个 book 节点的 title:
xml.setProperty("SelectionLanguage","XPath");
xml.selectNodes("/bookstore/book[1]/title");
选取所有价格
下面的例子选取 price 节点中的所有文本:
/bookstore/book/price/text()
选取价格高于 35 的 price 节点
下面的例子选取价格高于 35 的所有 price 节点:
/bookstore/book[price>35]/price
选取价格高于 35 的 title 节点
下面的例子选取价格高于 35 的所有 title 节点:
/bookstore/book[price>35]/title
标签:
原文地址:http://www.cnblogs.com/MenAngel/p/5348488.html