标签:
一、 HDFS简介
1、 HDFS全称
Hadoop Distributed FileSystem,Hadoop分布式文件系统。
Hadoop有一个抽象文件系统的概念,Hadoop提供了一个抽象类org.apache.hadoop.fs.FilesSystem,HDFS是这个抽象类的一个实现。其他还有:
|
文件系统 |
URI方案 |
Java实现(org.apache.hadoop) |
|
Local |
file |
fs.LocalFileSystem |
|
HDFS |
hdfs |
hdfs.DistrbutedFilesSystem |
|
HFTP |
hftp |
hdfs.HftpFilesSystem |
|
HSFTP |
hsftp |
hdfs.HsftpFilesSystem |
|
HAR |
har |
fs.HarFileSystem |
|
KFS |
kfs |
fs.kfs.KosmosFilesSystem |
|
FTP |
ftp |
Fs.ftp.FtpFileSystem |
2、 HDFS特点:
(1) 超大文件数据集群
(2) 流式数据访问方式读取文件
(3) 对硬件要求并不是特别高,有很好的容错机制。
(4) 数据访问有一定的延迟,这是因为HDFS优化的是数据吞吐量,是要以提高延迟为代价的。
(5) HDFS无法高效存储大量小文件。因为NameNode限制了文件个数。
(6) HDFS不支持多个写入者,也不支持随机写。
二、 HDFS体系结构
3、 体系结构图
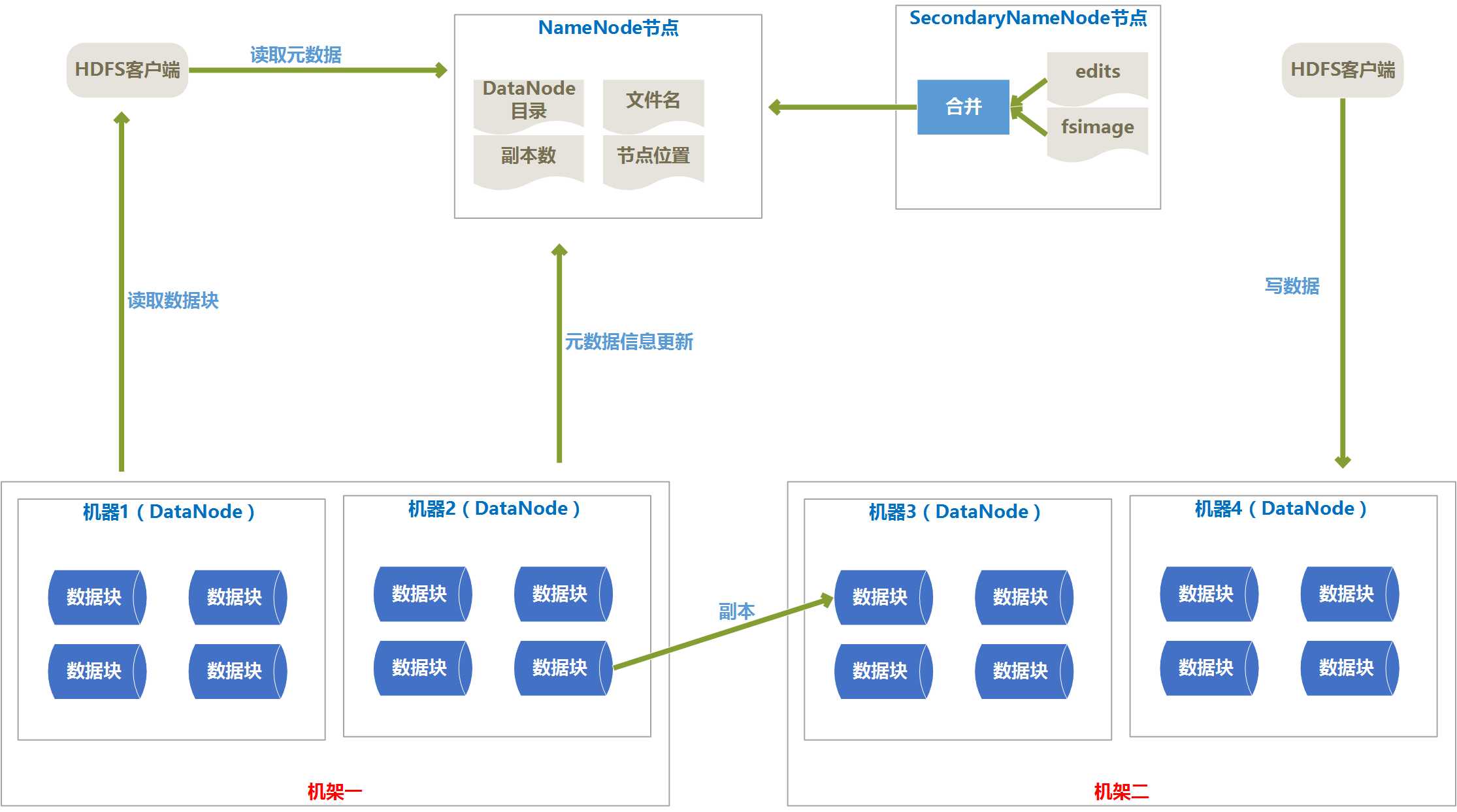
4、 体系结构介绍
(1) HDFS由Client、NameNode、DataNode、SecondaryNameNode组成。
(2) Client提供了文件系统的调用接口。
(3) NameNode由fsimage(HDFS元数据镜像文件)和editlog(HDFS文件改动日志)组成,NameNode在内存中保存着每个文件和数据块的引用关系。NameNode中的引用关系不存在硬盘中,每次都是HDFS启动时重新构造出来的。
(4) SecondaryNameNode的任务有两个:
l 定期合并fsimage和editlog,并传输给NameNode。
l 为NameNode提供热备份。
(5) 一般是一个机器上安装一个DataNode,一个DataNode上又分为很多很多数据块(block)。数据块是HDFS中最小的寻址单位,一般一个块的大小为64M,不像单机的文件系统,少于一个块大小的文件不会占用一整块的空间。
(6) 设置块比较大的原因是减少寻址开销,但是块设置的也不能过大,因为一个Map任务处理一个块的数据,如果块设置的太大,Map任务处理的数据量就会过大,会导致效率并不高。
(7) DataNode会通过心跳定时向NameNode发送所存储的文件块信息。
(8) HDFS的副本存放规则
默认的副本系数是3,一个副本存在本地机架的本机器上,第二个副本存储在本地机架的其他机器上,第三个副本存在其他机架的一个节点上。
这样减少了写操作的网络数据传输,提高了写操作的效率;另一方面,机架的错误率远比节点的错误率低,所以不影响数据的可靠性。
三、HDFS读写过程
1、 数据读取流程图
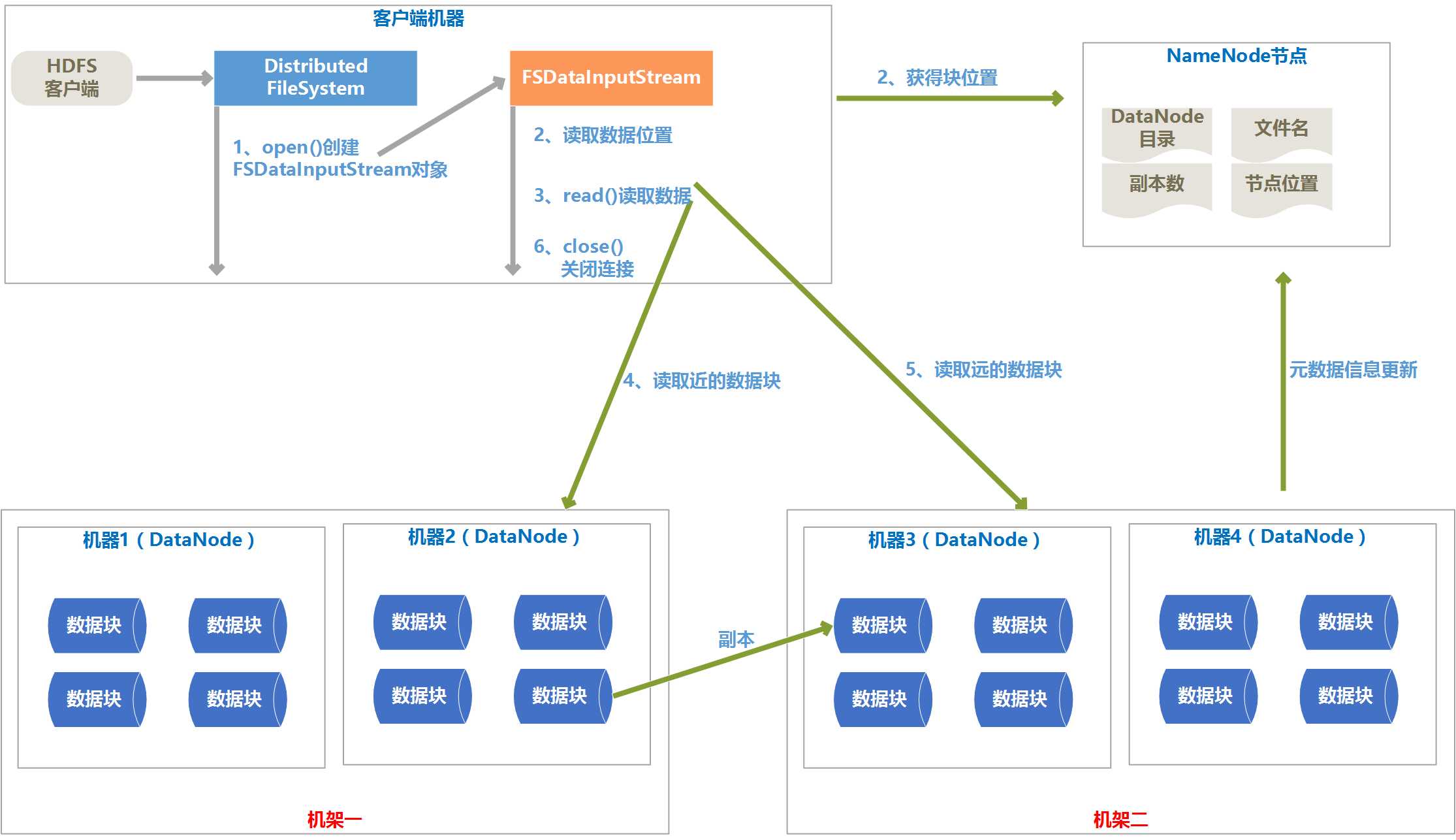
2、 读取过程说明
(1) HDFS客户端调用DistributedFileSystem类的open()方法,通过RPC协议请求NameNode来确定说请求的文件所在位置,找出最近的DataNode节点的地址。
(2) DistributedFileSystem会返回一个FSDataInputStream输入流对象给客户端。
(3) 客户端会在FSDatatInputStream上调用read()函数,按照每个DataNode的距离从近到远依次读取。
(4) 读取完每个DataNode后,在FSDataInputStream上调用close()函数。
(5) 如果读取出现故障,就会读取数据块的副本,同时向NameNode报告这个消息。
3、 文件的写入流程图
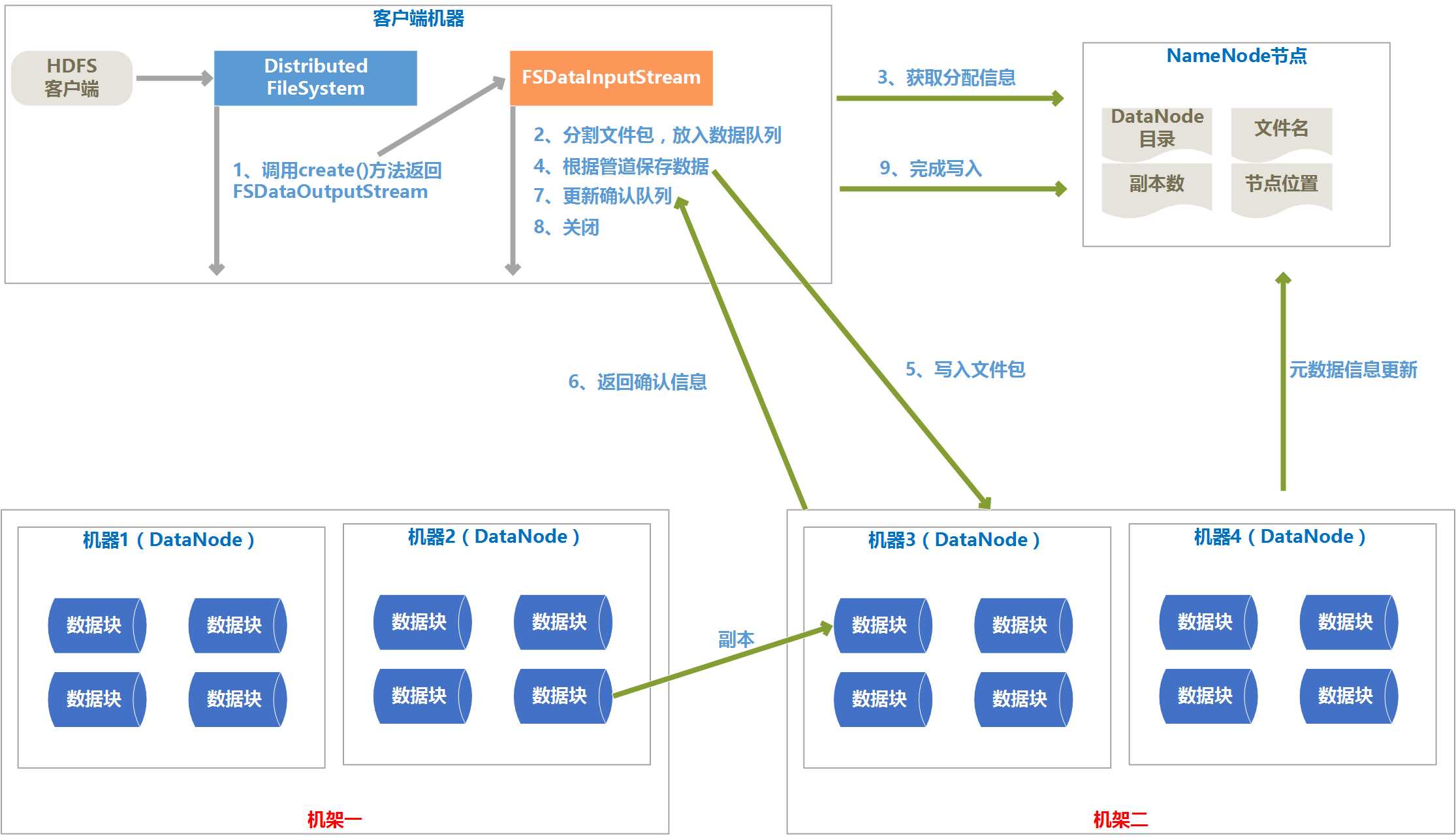
4、 写入流程说明
(1) 客户端调用DistributedFileSystem对象的create()方法,通过RPC协议调用NameNode,在命名空间创建一个新文件,此时还没有关联的DataNode与之关联。
(2) create()方法会返回一个FSDataOutputStream对象给客户端用来写入数据。
(3) 写入数据前,会将文件分割成包,放入一个“数据队列”中。
(4) NameNode为文件包分配合适的DateNode存放副本,返回一个DataNode的管道。
(5) 根据管道依次保存文件包在各个DataNode上。
(6) 各个DataNode保存好文件包后,会返回确认信息,确认消息保存在确认队列里,当管道中所有的DataNode都返回成功的的确认信息后,就会从确认队列里删除。
(7) 管道中所有的DataNode都保存完成后,调用FileSystem对象的close()关闭数据流。
四、Hadoop的页面接口
1、 界面地址
可以通过http://NameNodeIP:50070访问HDFS的Web界面了。
五、HDFS的Java API
1、 使用URL读取数据
1 //用URL接口读取HDFS中文件 2 static { 3 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory() ); 4 } 5 public String GetHDFSByURL(String url) throws MalformedURLException,IOException 6 { 7 String str=""; 8 InputStream in =null; 9 OutputStream out=null; 10 try { 11 in=new URL(url).openStream(); 12 //IOUtils.copyBytes(in,out,4096,false); 13 str=out.toString(); 14 } 15 finally { 16 IOUtils.closeStream(in); 17 IOUtils.closeStream(out); 18 } 19 return str; 20 }
2、 FileSystem API读取数据
//ReadFile
//url:"/user/hadoop/data/write.txt"
public String ReadFile(String url)throws IOException
{
String fileContent="";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(url);
if(fs.exists(path)){
FSDataInputStream is = fs.open(path);
FileStatus status = fs.getFileStatus(path);
byte[] buffer = new byte[Integer.parseInt(String.valueOf(status.getLen()))];
is.readFully(0, buffer);
is.close();
fs.close();
fileContent=buffer.toString();
}
return fileContent;
}
3、 FileSystem API创建目录
//创建HDFS目录
//dirpath: "/user/hadoop/data/20130709"
public void MakeDir(String dirpath) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(dirpath);
fs.create(path);
fs.close();
}
4、 FileSystem API写数据
//HDFS写文件
//fileurl:"/user/hadoop/data/write.txt"
public void WriteFile(String fileurl,String fileContent)throws IOException
{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(fileurl);
FSDataOutputStream out = fs.create(path);
out.writeUTF(fileContent);
fs.close();
}
5、 FileSystem API删除文件
//删除文件
//fileurl :"/user/hadoop/data/word.txt"
public void DeleteFile(String fileurl)throws IOException
{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(fileurl);
fs.delete(path,true);
fs.close();
}
6、 查询元数据
//查询文件的元数据
public void ShowFileStatus(String fileUrl) throws IOException
{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file=new Path(fileUrl);
FileStatus stat=fs.getFileStatus(file);
System.out.println("文件路径:"+stat.getPath());
System.out.println("是否是目录:"+stat.isDirectory());
System.out.println("是否是文件:"+stat.isFile());
System.out.println("块的大小:"+stat.getBlockSize());
System.out.println("文件所有者:"+stat.getOwner()+":"+stat.getGroup());
System.out.println("文件权限:"+stat.getPermission());
System.out.println("文件长度:"+stat.getLen());
System.out.println("备份数:"+stat.getReplication());
System.out.println("修改时间:"+stat.getModificationTime());
}
标签:
原文地址:http://www.cnblogs.com/chybin/p/5361994.html