标签:
推荐慕课网视频:http://www.imooc.com/video/10055
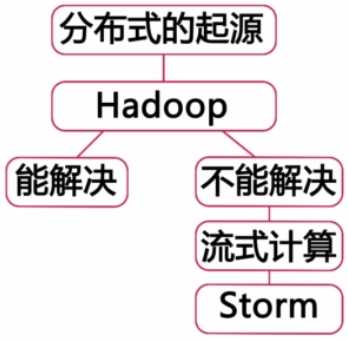
====Storm的起源。
Storm是开源的、分布式、流式计算系统
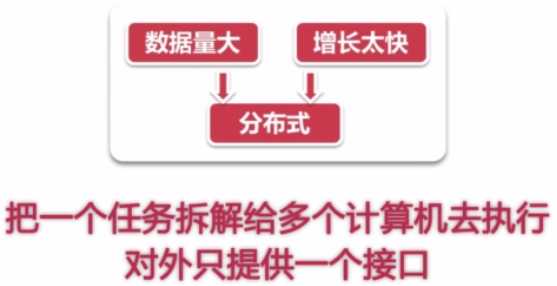
什么是分布式呢?就是将一个任务拆解给多个计算机去执行,让许多机器共通完成同一个任务,
把这个多机的细节给屏蔽,对外提供同一个接口、同一个服务,这样的系统就是分布式系统。
在多年以前并没有非常范用的分布式系统,即使存在,也都是限定在指定的领域,
当然,也有人尝试从中提取出共通的部分,发明一个通用的分布式系统,但是都没有很好的结果。
后来,Google发表了3篇论文,提出了分布式计算的模型,在分布式系统上有了一个质的突破。

有一位大牛看了这3篇论文之后,深受启发,然后就发明了Hadoop系统。

然后,基于Hadoop的改造系统就如雨后春笋一般,接二连三的出现了。
以至于,Hadoop已经不是一套软件,而是一整套生态系统了。
于是,人们谈到分布式,就必谈Hadoop了。

但是,Hadoop并不是万能的,它只能处理适合进行批量计算的需求。对于,非批量的计算就不能够满足要求了。
很多时候,我们只能先收集一段时间数据,等数据收集到一定规模之后,我们才开始MapReduce处理。
有这么一个故事:
-------------------
路人甲是在一家媒体公司A工作,他的主要工作内容很简单,就是在一些搜索引擎上做广告,
众所周知,搜索引擎上的广告是竞价排名的,谁土豪谁就排前面,出钱少的就只能排在后面。
公司A的竞争对手都比较土豪,所以呢,公司A的广告就一直排在后面,也没什么好的办法。
后来,路人甲想出了一个馊主意,就是用程序不断的去点击竞争对手的广告,让对手的广告费
很快的花费调,这样公司A就可以廉价的将广告排在前面了。
搜索引擎公司试图识别出这些恶意点击屏来保护商家,将这些恶意点击扣除的费用返还给商家。
一般来说呢,如果利用MapReduce,一般情况下,都需要收集一段时间数据,然后根据这些
数据来算出哪些点击是恶意的,本身收集数据就已经很耗费时间了,再等计算完毕之后,
土豪商家的广告费也基本上不剩什么了。
所以呢,我们希望在点击发生的时候就算出来该点击是否是作弊行为,及时不能马上判断出,
也应该尽早的计算出来。
-------------------
为了解决上面这个故事的需求,分布式流式计算系统就产生了,比较知名的有:
•【Yahoo】S4
•【IBM】StreamBase
•【Amazon】Kinesis
•【Spark】Streaming
•【Google】Millwheel
•【Apache】Storm(目前业界中最知名、流程)
批量计算(以Hadoop为代表)与流式计算的区别有哪些呢?

###################
目前已经有人在做一些前瞻性的项目,这些人试图将批量计算和流式计算进行整合
试图使用同一套API,即搞定流式计算,又搞定批量计算。
使一段代码不要任何改动,就可以同时执行在批量计算和流式计算两种系统之上。
这种系统目前比较有名的有:
【Twitter】Summing Bird
【Google】CloudDataflow
两个接口都已经开源了。等以后有机会一定要提前接触一下。
###################
====Storm组件
Storm采用的是主从结构,就是使用一台主节点来管理整个集群的运行状态。
这个主节点被称为:Nimbus,从节点用来维护每台机器的状态,被称为:Supervisor
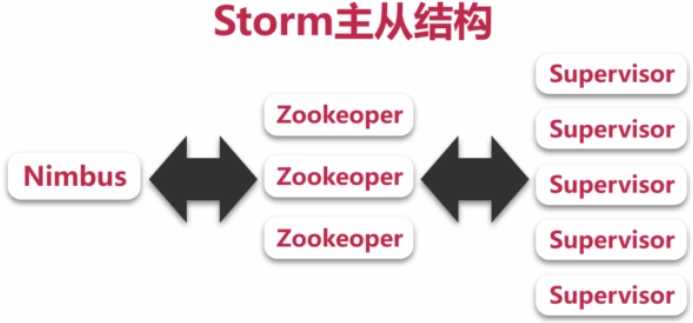
为什么采取主从结构呢?主从结构比较简单,不需要进行主节点仲裁等工作。

从前面的结构图中我们还可以看出,采取主从结构之后,Nimbus是一个单点,
但是,我们知道分布式领域里,大家都比较讨厌自己的系统设计中存在单点,
因为单点如果发生故障,很有可能影响到整个集群的可用性。
所以,如果一个系统设计中如果存在单点,一般情况下这个单点的作业必然比较轻,
挂了之后,短时间之内也不影响真个系统的运行,并且一般情况下都是没有状态的,
宕机之后至需要重启就能够恢复并正确处理。
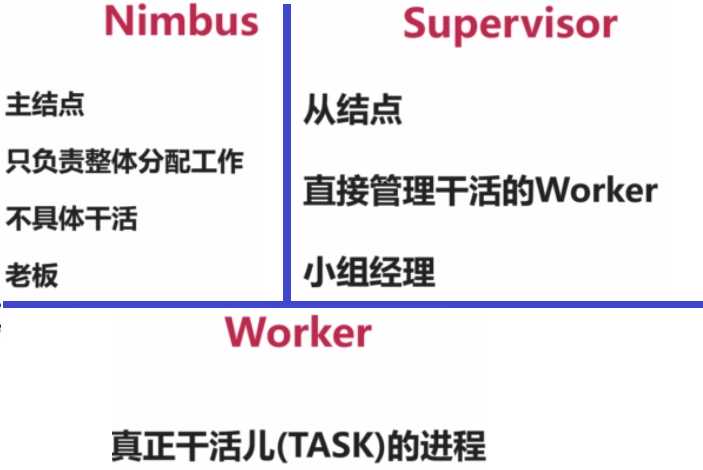
Nimbus的角色是只负责一些管理性的工作,它并不关心Worker之间的数据是如何传输的,
它的一些主要状态都存在分布式协调服务(Zookeeper)中,内存里面的东西都是可以丢失的,
如果它挂掉,只要没有运算节点发生故障,那么整个作业还是能够正常的进行数据处理的。
Nimbus重启之后,就可以正确处理真个系统的事务了。
Supervisor的角色是听Nimbus的话,来启动并监控真正进行计算的Worker的进程,
如果Worker有异常,那么久帮助Worker重启一下,它也不负责数据计算和数据传输,
真正的数据计算和输出,都是由Worker来进行。
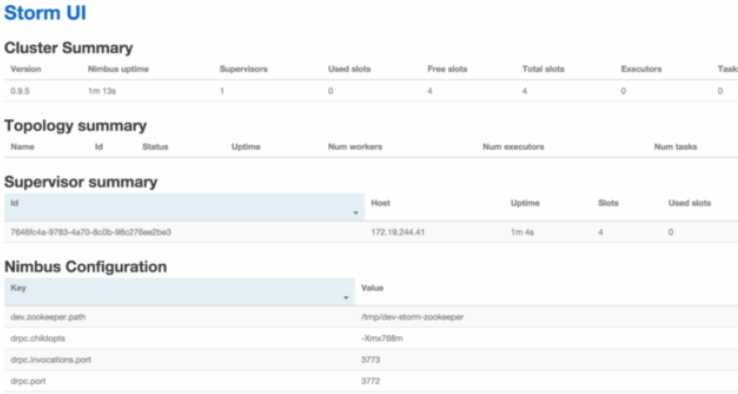
====Storm UI
为了方便用户管理集群,查看集群运行状态,提供了一个基于Web的UI来监控整个Storm集群
它本身不是集群运行的必须部分,它的启动停止都不影响Storm的正常运行。
====Storm作业提交运行流程
(1)用户使用Storm的API来编写Storm Topology。
(2)使用Storm的Client将Topology提交给Nimbus。
Nimbus收到之后,会将把这些Topology分配给足够的Supervisor。
(3)Supervisor收到这些Topoligy之后,Nimbus会指派一些Task给这些Supervisor。
(4)Nimvus会指示Supervisor为这些Task生成一些Worker。
(5)Worker来执行这些Task来完成计算任务。
====Storm本地模式搭建
(更新中)
标签:
原文地址:http://www.cnblogs.com/quchunhui/p/5370191.html