标签:
声明:
1)本文由我bitpeach原创撰写,禁止一切形式的转载。如有转载,侵权必究。
2)本简谈主要分为三个方面,第一是自动化协议逆向技术的基本理论,第二是当前发展趋势,第三是入门协议逆向技术的必备过程。
3)既是简谈,则文章篇幅不长,同时本文观点不一定正确,希望抛砖引玉,能得高人指点,幸为殊荣。
4)最近一个月比较忙,昨天正好写完稿子,今天就简写一些内容,避免重复,故为简谈。
协议逆向工程是指在不依赖于协议描述的情况下,通过对协议实体的网络输入/输出、系统行为和指令执行流程进行监控和分析,提取协议文法、语法和语义的过程。(潘璠博士,吴礼发教授,洪征副教授团队《协议逆向工程研究进展》)协议逆向工程这一术语,名字中带有工程,但是事实上,其中含有较多的学术理论推导和数学模型建立工作,因此本人更倾向于称之为协议逆向工程技术或协议逆向技术。
协议逆向技术不是Fuzzing,但是可以用于Fuzzing。协议逆向技术不是协议分类技术,但是可以用于协议分类新技术。发现协议逆向技术成为了各种补别人窟窿的技术,原因就在于其技术前提恶劣,工作的假设前提信息缺失匮乏,所以其通用性和推广性比一般理论模型要好,同时代价就是技术难点多,不一定能保证解析出成果来。
当前学术研究认为,协议分析技术是包含协议逆向技术的。原因在于,协议分析技术除协议逆向技术外,还包含协议识别,流量分类,协议安全测试等其他技术分支。
因为是协议规格未知,所以先验信息未知。在学术研究中,称为先验信息匮乏或损失。根据概率论,先验信息损失,只能观测到后验概率,因为无法还原字段规格的联合概率分布,从理论上来讲,永远不可能求解字段的正确位置(这一观点论断已经发表于2016年IET Communications和其他期刊上)。因此不论是从数学推导上,还是从工程实践上,都比较难,不能突破后验概率的局限性,只要是观测捕获的未知协议,就只能永远拟合逼近字段的正确位置,但是不能完备地求取字段位置,这受限于观测样本的特征多样性。(即类似于极限概念,可以无限趋近,但不能到达。)
协议逆向技术存在的意义,在于当分析对象是私有协议时,则该技术应运而生。当前存在大量的私有协议,有数据显示,未识别应用或未知流量占据统计报告所在网络 地区的30%。(数据来源,请查阅ReFlow组织和Internet2组织发布的流量统计报告。统计对象地区分别在巴西国家网络,美国 Internet2网络。)同时,一些业务需求使得协议设计者必须要保护自己的协议规格,如工控协议,物联网协议,无线数据链系统,RFID协议、自定义 蓝牙或Zigbee协议等等。
两点意义。
第一点,学术价值在目前2016年来看,仍然有一定潜力。未来4到5年确实不太好说,但是当前2016年本年度,是非常有价值。在后续章节中,会讨论当前发展趋势。
第二点,具备应用推广价值,可惜的地方在于,除了学术界著名的Netzob开源工具以外,还没有听说过旗号就叫“协议逆向技术”的开源工具。这反映了作为工具平台,理论转化率不高,还是过度依赖人工分析。
(1)报文序列分析,也叫基于网络轨迹(Network Trace)的协议逆向技术
(2)指令序列分析,也叫基于动态污点(Dynamic Taint)或程序分析(Execution Trace)的协议逆向技术
(3)主要区别,可阅读相关综述型论文,这里展示我自己绘制的学习笔记图。
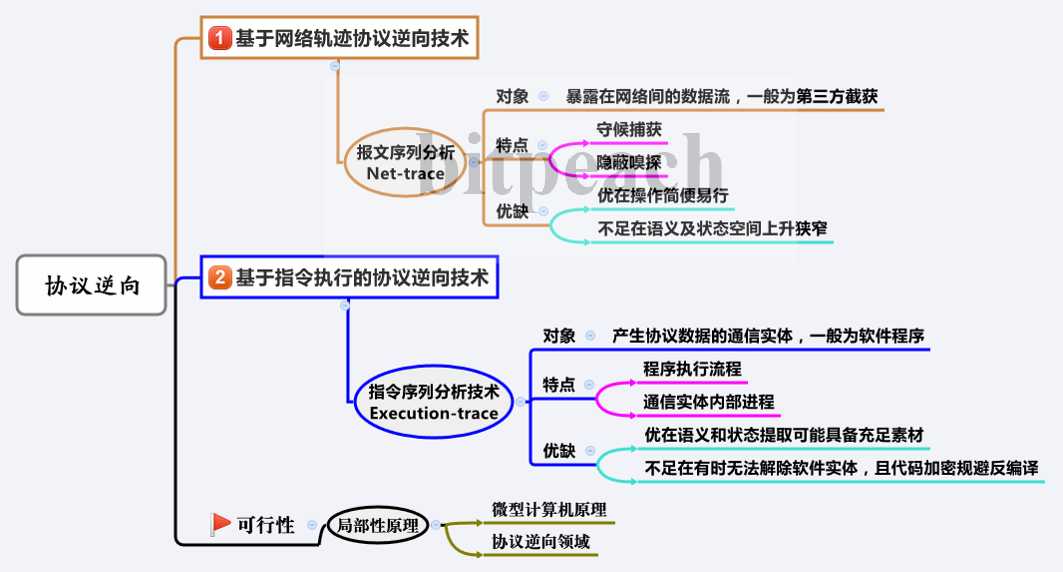
本人见识浅薄,没有完全罗列,只列举部分学者团队,且与网络轨迹相关的。请恕后生唐突冒昧。
(1)Marshall A. Beddoe,McAfee研究员,现疑似为软件工程师。堪称协议逆向技术自动化研究的启蒙者和开山者。首次提出自动化算法引入到协议逆向技术中,然后提供了开源的PI项目源代码。恐怕在这位宗师之后,也没有人敢开源自己的代码吧,无私而又强大,不得不佩服这位学者。
(2)微软科学研究院,Cui Weidong。中国人,清华毕业,后在美国工作,是国际学术研究中,协议逆向技术的较早启蒙者。其著名的Discoverer技术方案,为入门经典之作。
(3)广东中山大学,余顺争教授,王变琴老师高级工程师,罗建桢博士,肖明明博士等。这些学者是协议逆向技术和流量分类领域的强者,是国内学术研究中,协议逆向技术的较早开拓者。
(4)南京,吴礼发教授,洪征副教授团队。是协议逆向技术传统强队,国内较早的开拓者,其相关学术研究较多,基本每年都会有,2015年也没有例外。
(5)法国高等电子学院,Georges Bossert团队负责人。Netzob开源的设计者,曾在社交网络上,与之做过短暂交流,钦佩他的工具理念和算法设计,同时讨论了二进制协议逆向技术研究的新兴议题。
(6)华中科技大学,李伟明教授团队。在2010年之2013年期间,做了大量的协议逆向技术工作,主要目的是做模糊(Fuzzing)测试。目前可能已经转移了研究领域。
(7)四川核物理研究院,去年和今年发表了几篇文献,研究想法和研究思路都比较好。不知道是否会继续从事研究,如果还继续从事研究的话,那么是非常好的一件事,为协议逆向技术研究推动,贡献一份力量。很羡慕这种研究出产量高的新晋团队,实力强,人数多。
(8)郑州,舒辉老师,罗军勇老师,陈性元老师,韩继红老师。这些前辈均在国内一类期刊上,发表过相关研究。唯一遗憾的是,这些前辈可能会转移研究领域,或团队延续性中断。
(9)如有遗漏,欢迎交流。冒昧唐突,请恕原谅。
(1)可能工控安全企业会涉足吧,个人不太懂,就不议论了。
(2)帖子一枚,本人不懂Fuzzing,但是PI项目本身不是Fuzzing,却可以运用至Fuzzing里面,原因是多序列算法可以对域结构进行标记。地址:百度安全论坛,http://anquan.baidu.com/bbs/forum.php?mod=viewthread&tid=408345
(3)其他:略
仅探讨基于网络轨迹的协议逆向技术研究
(1)本科硕士博士的学位论文
截止2015年,部分尤其值得钦佩的论文,包括王一鹏等人的学位论文,非常具有学术价值,理论推导也不错。
(2)国内外期刊会议等短论文
针对上述知名团队,论文水平质量较高。呈现的特点是:a)2015年开始,在协议状态机等领域,突破进展较快较多较好。b)2015年开始,发现了协 议逆向技术与流量分类的共性问题,提出面向协议逆向技术的协议分类方法研究,成为一个分支。原因很简单,因为未知协议的分类方法很难,是无监督的,不能进 行有监督或半监督。c)2016开始,旗帜鲜明地提出二进制协议逆向技术的新兴议题。虽然二进制协议逆向不是个新问题,但是是一个新议题,尚无相关学者提出专门方法解析它。
(3)参考文献和对应工作的梳理关系图,仅供参考,不能作为严格证明材料。Attention!注意,图中甚至可能出现谬误,请自行甄别。由于时效性,没有给出更新的文献了。

(4)参考文献和对应历史时间的梳理关系图,仅供参考,不能作为严格证明材料。Attention!注意,图中甚至可能出现谬误,请自行甄别。由于时效性,没有给出更新的文献了。
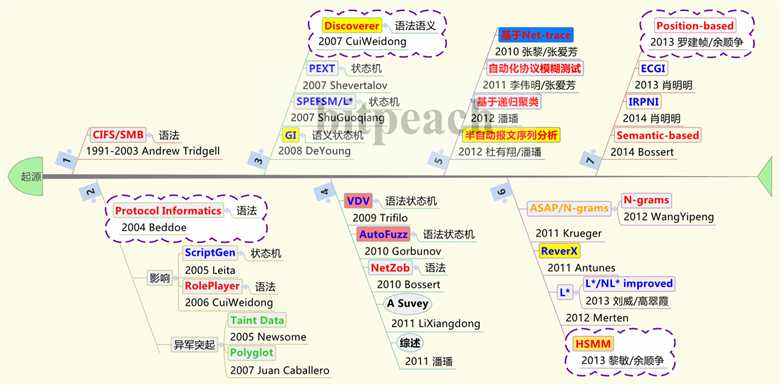
(1)2011年,潘璠博士等人,协议逆向工程研究进展。是我的启蒙读物,深为感激敬佩,引领晚辈走向此路
(2)2013年,张钊等人,协议规范研究综述。思路清晰,概念总结到位。状态机的综述整理也比较新颖。
(3)2015年,吴礼发教授等人,协议状态机推断综述。专门谈状态机的,总结和梳理十分详实,阅读此文,如饥似渴,钦佩之至。
(4)2015年,刘渊等人,基于网络数据的协议逆向工程研究进展。在面向协议逆向技术的协议分类研究上,有较好的论述,将报文分类引入到协议逆向问题中来,是好思路,也是符合实际应用需求的。
(5)2015年,John Narayan等人,协议逆向工程工具综述,纯正英文文献。逻辑图表关系比较形象,作为硕士研究生入门读物,又锻炼自己的英语,是个不错的选择。:-)
(6)以上不完全列举,如有遗漏,请恕失误。
仅探讨基于网络轨迹的协议逆向技术研究
(1)面向协议逆向技术的协议分类研究
从事协议逆向技术,最致命的是前端,真实网络环境下,未知私有的协议数据到手后,可是是一团乱麻,不知道哪些是同一类的私有协议。只有牵头牵出一类私有协议的数据,才好做下一步工作。原本这一工作不属于协议逆向,但是在实际需求上产生了这一问题,因此衍生了报文分类研究。协议分类研究很早也开始了,但是不同于协议逆向问题中的协议分类,原因有很多,只谈一条最重要的,因为是无监督的分类问题,还不好评估准确程度。
(2)字段格式提取研究
在字段格式提取研究上,比较有意思的一件事。相关基于网络轨迹的研究,呈现两个特点:a)常见做文本字段的解析;b)评估方法用的是召回率这种协议分类指标,同时研究的人少。截止2015年,每年最多一篇是专门针对字段格式提取这一技术目的的研究讨论。大多研究者的思路是关键字段提取,而不是字段格式提取。两者不等价。原因是对于协议的分类或解析,有时候选取一到两个字段,就可以区别,没有必要做到字段格式的份上。相当于从百米的起始跑道,推进到百米终点,大多研究在起点位置徘徊,研究字段域结构提取,字段指纹,字段特征提取,说到最后仍然是精度不高的特征,评估时选用识别率,而不是用Discoverer中的字段区域精确评估指标。反映了,字段格式提取的工作难以突破,难度较高,在这一领域的强者,是广东中山大学,余顺争教授和罗建桢博士的研究,数学功底推导和算法设计思路均十分新颖。
(3)语义推断研究
在这一领域上,基于网络轨迹的研究稀少,原因是技术难点比字段格式提取还多。语义推断,有时候依赖于字段格式提取。当字段格式提取不顺畅的时候,语义推断也很难做下去。然而,有时候,语义推断不需要提取字段格式。这反映了两种不同的研究思路,一种是引入语义信息的先验猜测,一种是以字段格式提取为基础的语义探索。两个先后关系和上下关系不同。截止2015年,仅2010年和2014年的两三篇文献,专门探讨semantic information外,恐怕也再没见到。这一方面是后续本人研究极其感兴趣的地方。
(4)状态机推演研究
在这一领域上,广东中山大学余顺争教授和南京吴礼发教授等团队是传统强队,也有部分术语称为状态机推断研究。一般分为初始状态标注构建和状态机化简,部分研究往往涉及到协议分类研究。所以面向协议逆向技术的协议分类研究可以划入到这一研究中来,不过目前还没有讨论两者关系,期待有人能够讨论。
仅探讨基于网络轨迹的协议逆向技术研究
(1)未知协议发现
当前公开学术文献较少使用这一术语,EI收录的相关研究领域中几乎没有人使用,所以这一术语需要谨慎讨论。原因是听到若干次技术讨论,使用协议发现这一术语。问题是怎么定义协议发现,怎样的协议能叫被发现,具体公式含义尚不明确。并非是指这一术语错误,而是说,当将这一概念表述清晰,可能会引发一系列的优秀灵感。如借助异常检测理论,对未知协议发现,下形式化表达或准确数学公式的定义。还存在一种可能性,协议发现到最后,实际已经有一个术语可以概括它了。种种猜测都需要后续探索研究。
(2)字段格式提取方面
提出了二进制协议字段的新议题。因为在常见的网络环境中,如果是文本字段,直接翻译ASCII或猜测编码集,即可获得一些有用信息,再根据有用信息的利用,逐步解析剥离。但是对于二进制协议,这是常见的形态,工控领域,无线通信领域,卫星网络领域,链路传输领域,僵尸网络领域,观察到的协议数据如果协议规格不知道,大多呈现的是二进制数据状态,不知道哪儿和哪儿是字段边界,用ASCII一译码,译不出来,说明二进制协议字段的问题是个比文本协议字段解析更复杂的问题。
同时在2015年之2016年期间,有很多同行对字段格式提取的统计方法思路,做了探索。可以说是百花齐放,这是很好的一个事情,大家一起研究,一起探索,让这个领域活下去。笔者有点悲观的原因已经写在前文中了。
(3)报文分类方面
协议逆向工程的报文分类问题,一般有三方面子问题(略),也是当前本人团队下一步要做的理论探索和实际进展工作。
(4)协议逆向和协议“正向”
很多学者都在做协议逆向,可是做协议“正向”的不多。这个“正向”不是按规格解析的意思,而是从正向上分析协议设计者在设计协议的思路,从正向上分析协议在组合时的先验分布,当前2015年有一位韩国人发表了相关研究,已知工控协议的规格,分析工控协议特点。这里不赘述了,也是本人课题组下一步要做的实际进展工作。
(1)综述类文献:已经在上面的小节中罗列了。
(2)具体技术文献:按照综述类文献,一篇篇读吧。想做以程序分析为入口的,就读指令分析序列部分。想做以Pcap包捕获数据为分析对象的,就读基于网络轨迹的协议逆向技术研究。
(3)如果是学术研究者,不是工业界者。可以考虑修这几门课:数据挖掘与机器学习,数据挖掘与统计学习,自然语言处理,生物信息学,时间序列分析,模式识别,统计学习,人工智能等。
(1)Netzob,看看前辈的平台工具,可以提高自己的眼界。
(2)编程实践工具:只是推荐而已,根据自己情况用。比较推荐Python,R,Matlab,C等。做项目用C及其变种,做学术用Python,R,Matlab。因为有些库工具比较好用,利于学术快速出成果和性能分析。
昨晚,论文成型,达成了第一版草案,至少已经不用发愁了,感慨万千。
早年时,求学游历,就已经学习过反者道之动,弱者道之用的网络信息安全对抗的哲学规律,让我对信息安全理论受用无比,受益匪浅。
古人云:文章千古事,得失寸心知。曾经腹中经纶明珠多颗,以为蒙尘,一度想束之高阁。
如今,应感谢自己生命中的恩人和贵人,尤其是感激指点我的恩师。
首先,让自己阴差阳错地走向了研究方向,尽管当年选择这个方向的时候,有一段很诙谐的经历。
然后,又一路有惊无险地度过学术研究的各种考核难关和人生生活难关。
最后,到了今天这个地方,自己都不敢想象自己会达到这样的地步,我简直是傻人有傻福,命中得遇贵人,或许就是电影里的“Stupid is as stupid does.”,十分珍惜这样的缘分命运。
读到过这样的典记,
公孙丑曰:“道则高矣,美矣,宜若登天然,似不可及也;何不使彼为可几及而日孳孳也?”
孟子曰:“大匠不为拙工改废绳墨,羿不为拙射变其彀率。君子引而不发,跃如也。中道而立,能者从之。”
引而不发,跃如也。中道而立,能者从之。这样的人生境界恐怕唯有恩师才能达到吧,愿继往后来者应倍加珍惜。
终于意识到,还有3个月,即使战战兢兢,如临深渊,如履薄冰,但是很快,又要走到一个人生路口的风雨转折点,让人悲欣交集。
就此搁笔,不知所云。
标签:
原文地址:http://www.cnblogs.com/bitpeach/p/5370918.html