标签:
摘自:http://www.tuicool.com/articles/emQZNnN
Hadoop系统运行于一个由普通商用服务器组成的计算集群上,该服务器集群在提供大规模分布式数据存储资源的同时,也提供大规模的并行化计算资源。
在大数据处理软件系统上,随着Apache Hadoop系统开源化的发展,在最初包含HDFS、MapReduce、HBase等基本子系统的基础上,至今Hadoop平台已经演进为一个包含很多相关子系统的完整的大数据处理生态系统。(下图展示了Hadoop平台的基本组成与生态系统)
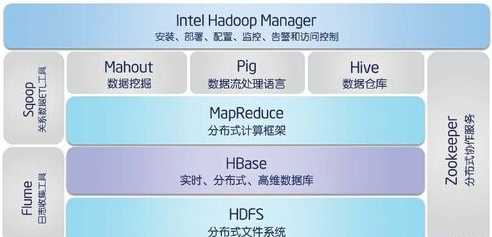
MapReduce并行计算框架是一个并行化程序执行系统。它提供了一个包含Map和Reduce两阶段的并行处理模型和过程,提供一个并行化编程模型和接口,让程序员可以方便快速地编写出大数据并行处理程序。MapReduce以键值对数据输入方式来处理数据,并能自动完成数据的划分和调度管理。在程序执行时,MapReduce并行计算框架将负责调度和分配计算资源,划分和输入输出数据,调度程序的执行,监控程序的执行状态,并负责程序执行时各计算节点的同步以及中间结果的收集整理。MapReduce框架提供了一组完整的供程序员开发MapReduce应用程序的编程接口。
HDFS(Hadoop Distributed File System)是一个类似于Google GFS的开源的分布式文件系统。它提供了一个可扩展、高可靠、高可用的大规模数据分布式存储管理系统,基于物理上分布在各个数据存储节点的本地Linux 系统的文件系统,为上层应用程序提供了一个逻辑上成为整体的大规模数据存储文件系统。与GFS类似,HDFS采用多副本(默认为3个副本)数据冗余存储机制,并提供了有效的数据出错检测和数据恢复机制,大大提高了数据存储的可靠性。
为了克服HDFS难以管理结构化/半结构化海量数据的缺点,Hadoop提供了一个大规模分布式数据库管理和查询系统HBase。HBase是一个建立在HDFS之上的分布式数据库,它是一个分布式可扩展的NoSQL数据库,提供了对结构化、半结构化甚至非结构化大数据的实时读写和随机访问能力。 HBase提供了一个基于行、列和时间戳的三维数据管理模型,HBase中每张表的记录数(行数)可以多达几十亿条甚至更多,每条记录可以拥有多达上百万的字段。
Common是一套为整个Hadoop系统提供底层支撑服务和常用工具的类库和API编程接口,这些底层服务包括Hadoop抽象文件系统 FileSystem、远程过程调用RPC、系统配置工具Configuration以及序列化机制。在0.20及以前的版本中,Common包含 HDFS、MapReduce和其他公共的项目内容;从0.21版本开始,HDFS和MapReduce被分离为独立的子项目,其余部分内容构成 Hadoop Common。
Avro是一个数据序列化系统,用于将数据结构或数据对象转换成便于数据存储和网络传输的格式。Avro提供了丰富的数据结构类型,快速可压缩的二进制数据格式,存储持久性数据的文件集,远程调用RPC和简单动态语言集成等功能。
Zookeeper是一个分布式协调服务框架,主要用于解决分布式环境中的一致性问题。Zookeeper主要用于提供分布式应用中经常需要的系统可靠性维护、数据状态同步、统一命名服务、分布式应用配置项管理等功能。Zookeeper可用来在分布式环境下维护系统运行管理中的一些数据量不大的重要状态数据,并提供监测数据状态变化的机制,以此配合其他Hadoop子系统(如HBase、Hama等)或者用户开发的应用系统,解决分布式环境下系统可靠性管理和数据状态维护等问题。
Hive是一个建立在Hadoop之上的数据仓库,用于管理存储于HDFS或HBase中的结构化/半结构化数据。它最早由Facebook开发并用于处理并分析大量的用户及日志数据,2008年Facebook将其贡献给Apache成为Hadoop开源项目。为了便于熟悉SQL的传统数据库使用者使用Hadoop系统进行数据查询分析,Hive允许直接用类似SQL的HiveQL查询语言作为编程接口编写数据查询分析程序,并提供数据仓库所需要的数据抽取转换、存储管理和查询分析功能,而HiveQL语句在底层实现时被转换为相应的MapReduce程序加以执行。
Pig是一个用来处理大规模数据集的平台,由Yahoo!贡献给Apache成为开源项目。它简化了使用Hadoop进行数据分析处理的难度,提供一个面向领域的高层抽象语言Pig Latin,通过该语言,程序员可以将复杂的数据分析任务实现为Pig操作上的数据流脚本,这些脚本最终执行时将被系统自动转换为MapReduce任务链,在Hadoop上加以执行。Yahoo!有大量的MapReduce作业是通过Pig实现的。
Cassandra是一套分布式的K-V型的数据库系统,最初由Facebook开发,用于存储邮箱等比较简单的格式化数据,后Facebook将 Cassandra贡献出来成为Hadoop开源项目。Cassandra以Amazon专有的完全分布式Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型,提供了一套高度可扩展、最终一致、分布式的结构化键值存储系统。它结合了Dynamo的分布技术和Google的 Bigtable数据模型,更好地满足了海量数据存储的需求。同时,Cassandra变更垂直扩展为水平扩展,相比其他典型的键值数据存储模型,Cassandra提供了更为丰富的功能。
Chukwa是一个由Yahoo!贡献的开源的数据收集系统,主要用于日志的收集和数据的监控,并与MapReduce协同处理数据。Chukwa 是一个基于Hadoop的大规模集群监控系统,继承了Hadoop系统的可靠性,具有良好的适应性和扩展性。它使用HDFS来存储数据,使用 MapReduce来处理数据,同时还提供灵活强大的辅助工具用以分析、显示、监视数据结果。
Hama是一个基于BSP并行计算模型(Bulk Synchronous Parallel,大同步并行模型)的计算框架,主要提供一套支撑框架和工具,支持大规模科学计算或者具有复杂数据关联性的图计算。Hama类似 Google公司开发的Pregel,Google利用Pregel来实现图遍历(BFS)、最短路径(SSSP)、PageRank等计算。Hama可以与Hadoop的HDSF进行完美的整合,利用HDFS对需要运行的任务和数据进行持久化存储。由于BSP在并行化计算模型上的灵活性,Hama框架可在大规模科学计算和图计算方面得到较多应用,完成矩阵计算、排序计算、PageRank、BFS等不同的大数据计算和处理任务。
Mahout来源于Apache Lucene子项目,其主要目标是创建并提供经典的机器学习和数据挖掘并行化算法类库,以便减轻需要使用这些算法进行数据分析挖掘的程序员的编程负担,不需要自己再去实现这些算法。Mahout现在已经包含了聚类、分类、推荐引擎、频繁项集挖掘等广泛使用的机器学习和数据挖掘算法。此外,它还提供了包含数据输入输出工具,以及与其他数据存储管理系统进行数据集成的工具和构架。
Sqoop是SQL-to-Hadoop的缩写,是一个在关系数据库与Hadoop平台间进行快速批量数据交换的工具。它可以将一个关系数据库中的数据批量导入Hadoop的HDFS、HBase、Hive中,也可以反过来将Hadoop平台中的数据导入关系数据库中。Sqoop充分利用了 Hadoop MapReduce的并行化优点,整个数据交换过程基于MapReduce实现并行化的快速处理。
Flume是由Cloudera开发维护的一个分布式、高可靠、高可用、适合复杂环境下大规模日志数据采集的系统。它将数据从产生、传输、处理、输出的过程抽象为数据流,并允许在数据源中定义数据发送方,从而支持收集基于各种不同传输协议的数据,并提供对日志数据进行简单的数据过滤、格式转换等处理能力。输出时,Flume可支持将日志数据写往用户定制的输出目标。
标签:
原文地址:http://www.cnblogs.com/my--blog-/p/5372163.html