标签:
一个成熟的大型网站(如淘宝、京东等)的系统架构需要考虑诸多复杂的因素,因为像淘宝这种大型网站数据量比一般的网站要大的多,所以在设计架构方面也要复杂的多,既要考虑成本因素也要考虑访问速度安全性等。这里我简单的对淘宝的网站系统架构进行一个简单的分析。
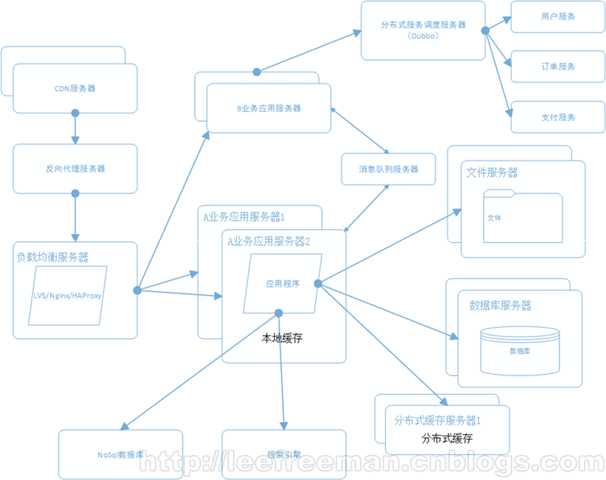
淘宝作为一个大型购物网站,其数据量是很大的,所以不像一般网站,淘宝需要用各种方法来保证服务器的正常运行以及用户购买时的良好体验。主要由以下方式:1.应用、数据、文件分离 2.利用缓存改善网站性能 3.使用CDN和反向代理提高访问速度 4.使用分布式文件系统
5.将应用服务器进行业务拆分
首先随着作为大型购物网站,一台服务器已经肯定满足性能需求,所以将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。
由于功能复杂,用户访问路径长,淘宝选择对这些数据进行缓存以提高用户的访问速度。缓存实现常见的方式是本地缓存、分布式缓存。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快。同时提供均衡负载服务器来分担主要服务器的压力。
使用CDN和反向代理提高网站性能。由于淘宝的服务器不能分布在国内的每个地方,所以不同地区的用户访问需要通过互联路由器经过不同长度的路径来访问服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。
在这里简单介绍一下CDN的原理。CDN的全称Content Delivery Network,即内容分发网络。CDN是一个经策略性部署的整体系统,从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均而产生的用户访问网站响应速度慢的根本原因。CDN目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,解决 Internet 网络拥塞状况,提高用户访问网站的响应速度。CDN是一种组合技术,其中包括源站、缓存服务器、智能DNS几个重要部分。
随着业务进一步扩展,这时我们需要将应用程序进行业务拆分。每个业务应用负责相对独立的业务运作(所以需要开辟多个服务对不同业务进行划分)。业务之间通过消息进行通信或者同享数据库来实现。所以在负载服务器上链接一个B业务服务器在对其业务进行分布式划分(如用户,订单,支付等),然后B级业务服务器通过消息队列服务器来与A业务服务区进行实时通信已经共享数据。 诸如此类的A,B服务器有许多,相互之间都可以进行共享数据。
下面简单介绍一下淘宝的数据库架构。对于淘宝来说,最重要的就是数据库的架构。
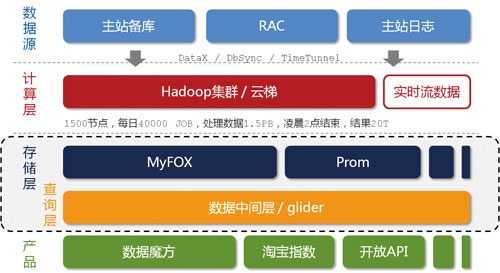
按照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层(如上图所示),分别是数据源、计算层、存储层、查询层和产品层。位于架构顶端的是我们的数据来源层,这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索等行为日志等。在数据源层实时产生的数据,通过淘宝自主研发的数据传输组件准实时地传输到一个Hadoop集群上,这个集群称之为“云梯”,是计算层的主要组成部分。不得不提的是,一些对实效性要求很高的数据,例如针对搜索词的统计数据,我们希望能尽快推送到数据产品前端。这种需求再采用“云梯”来计算效率将是比较低的。为此我们做了流式数据的实时计算平台,称之为“银河”。“银河”也是一个分布式系统,它接收来自前端的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
我们针对前端产品设计了专门的存储层。在这一层,我们有基于MySQL的分布式关系型数据库集群MyFOX和基于HBase的NoSQL存储集群Prom。存储层异构模块的增多,对前端产品的使用带来了挑战。为此,我们设计了通用的数据中间层glider来屏蔽这个影响。glider以HTTP协议对外提供restful方式的接口。数据产品可以通过一个唯一的URL获取到它想要的数据。
总体来说淘宝网站的架构十分复杂,因为淘宝这种大型购物网站的数据量比一般网站要大的多,而且涉及到巨额的财产交易,所以网络的安全性,稳定性自然是必须要保证的。而且尽量要降低运行成本,提高用户体验。如此多的要求对于一个团队来说确实十分困难,但是淘宝的技术团队通过各种技术手段很好的解决了这些问题。总体来说无论是淘宝的网站架构还是它的数据库架构都是同行业的标杆。
标签:
原文地址:http://www.cnblogs.com/lym0816/p/5372693.html