标签:
object Map {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
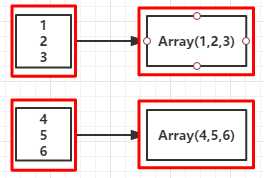
val rdd = sc.parallelize(1 to 10) //创建RDD
val map = rdd.map(_*2) //对RDD中的每个元素都乘于2
map.foreach(x => print(x+" "))
sc.stop()
}
}
2 4 6 8 10 12 14 16 18 20


//...省略sc
val rdd = sc.parallelize(1 to 5)
val fm = rdd.flatMap(x => (1 to x)).collect()
fm.foreach( x => print(x + " "))
1 1 2 1 2 3 1 2 3 4 1 2 3 4 5
Range(1) Range(1, 2) Range(1, 2, 3) Range(1, 2, 3, 4) Range(1, 2, 3, 4, 5)
(RDD依赖图)


object MapPartitions {
//定义函数
def partitionsFun(/*index : Int,*/iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = /*"["+index+"]"+*/next._1 :: woman
case _ =>
}
}
return woman.iterator
}
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("mappartitions")
val sc = new SparkContext(conf)
val l = List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female"))
val rdd = sc.parallelize(l,2)
val mp = rdd.mapPartitions(partitionsFun)
/*val mp = rdd.mapPartitionsWithIndex(partitionsFun)*/
mp.collect.foreach(x => (print(x +" "))) //将分区中的元素转换成Aarray再输出
}
}
kpop lucy
val mp = rdd.mapPartitions(x => x.filter(_._2 == "female")).map(x => x._1)

[0]kpop [1]lucy
//省略sc val rdd1 = sc.parallelize(1 to 3) val rdd2 = sc.parallelize(3 to 5) val unionRDD = rdd1.union(rdd2) unionRDD.collect.foreach(x => print(x + " ")) sc.stop
1 2 3 3 4 5
//省略sc val rdd1 = sc.parallelize(1 to 3) val rdd2 = sc.parallelize(3 to 5) val unionRDD = rdd1.intersection(rdd2) unionRDD.collect.foreach(x => print(x + " ")) sc.stop
3 4
//省略sc val list = List(1,1,2,5,2,9,6,1) val distinctRDD = sc.parallelize(list) val unionRDD = distinctRDD.distinct() unionRDD.collect.foreach(x => print(x + " "))
1 6 9 5 2
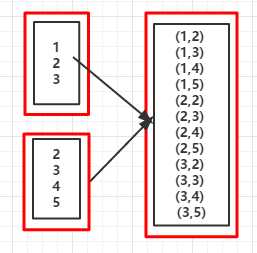
//省略 val rdd1 = sc.parallelize(1 to 3) val rdd2 = sc.parallelize(2 to 5) val cartesianRDD = rdd1.cartesian(rdd2) cartesianRDD.foreach(x => println(x + " "))
(1,2) (1,3) (1,4) (1,5) (2,2) (2,3) (2,4) (2,5) (3,2) (3,3) (3,4) (3,5)
(RDD依赖图)

//省略
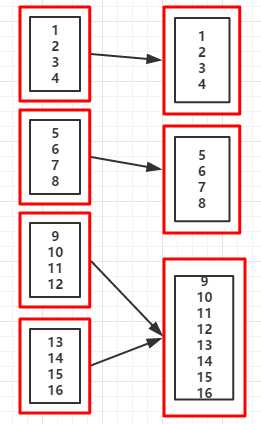
val rdd = sc.parallelize(1 to 16,4)
val coalesceRDD = rdd.coalesce(3) //当suffle的值为false时,不能增加分区数(即分区数不能从5->7)
println("重新分区后的分区个数:"+coalesceRDD.partitions.size)
重新分区后的分区个数:3 //分区后的数据集 List(1, 2, 3, 4) List(5, 6, 7, 8) List(9, 10, 11, 12, 13, 14, 15, 16)
//...省略
val rdd = sc.parallelize(1 to 16,4)
val coalesceRDD = rdd.coalesce(7,true)
println("重新分区后的分区个数:"+coalesceRDD.partitions.size)
println("RDD依赖关系:"+coalesceRDD.toDebugString)
重新分区后的分区个数:5 RDD依赖关系:(5) MapPartitionsRDD[4] at coalesce at Coalesce.scala:14 [] | CoalescedRDD[3] at coalesce at Coalesce.scala:14 [] | ShuffledRDD[2] at coalesce at Coalesce.scala:14 [] +-(4) MapPartitionsRDD[1] at coalesce at Coalesce.scala:14 [] | ParallelCollectionRDD[0] at parallelize at Coalesce.scala:13 [] //分区后的数据集 List(10, 13) List(1, 5, 11, 14) List(2, 6, 12, 15) List(3, 7, 16) List(4, 8, 9)
(RDD依赖图:coalesce(3,flase))


//省略 val rdd = sc.parallelize(1 to 16,4) val glomRDD = rdd.glom() //RDD[Array[T]] glomRDD.foreach(rdd => println(rdd.getClass.getSimpleName)) sc.stop
int[] //说明RDD中的元素被转换成数组Array[Int]


//省略sc val rdd = sc.parallelize(1 to 10) val randomSplitRDD = rdd.randomSplit(Array(1.0,2.0,7.0)) randomSplitRDD(0).foreach(x => print(x +" ")) randomSplitRDD(1).foreach(x => print(x +" ")) randomSplitRDD(2).foreach(x => print(x +" ")) sc.stop
2 4 3 8 9 1 5 6 7 10
标签:
原文地址:http://www.cnblogs.com/MOBIN/p/5373256.html