标签:
下面的代码可以实现以字节为单位复制文件的功能,适合复制非文本类型的文件,为了更清楚的观测运行速率,我加入了程序计时器,代码如下:

1 import java.io.FileInputStream;
2 import java.io.FileOutputStream;
3 import java.io.IOException;
4
5 public class Yuan {
6 /**
7 * @param args
8 */
9 public static void main(String[] args) {
10 long startMili=System.currentTimeMillis();
11 try {
12 FileInputStream fis = new FileInputStream ("a.mp3");
13 FileOutputStream fos = new FileOutputStream ("temp.mp3");
14 int read = fis.read();
15 while ( read != -1 ) {
16 fos.write(read);
17 read = fis.read();
18 }
19 fis.close();
20 fos.close();
21 } catch (IOException e) {
22 e.printStackTrace();
23 }
24 long endMili=System.currentTimeMillis();
25 System.out.println("总耗时为:"+(endMili-startMili)+"毫秒");
26 }
27 }
运行效果:
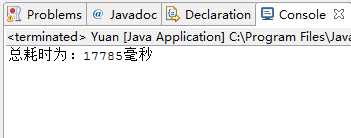
但是,这段代码在复制如mp3等大文件时,运行效率很低,课后我对以上代码进行了改进:
1 import java.io.FileInputStream;
2 import java.io.FileOutputStream;
3 import java.io.IOException;
4
5 public class Copys {
6 /**
7 * @param args
8 */
9 public static void main(String[] args) {
10 long startMili=System.currentTimeMillis();
11 try {
12 FileInputStream fis = new FileInputStream ("a.mp3");
13 FileOutputStream fos = new FileOutputStream ("temp.mp3");
14 byte[] bys = new byte[1024];
15 int len = 0;
16 while ((len = fis.read(bys)) != -1) {
17 fos.write(bys, 0, len);
18 }
19 fis.close();
20 fos.close();
21 } catch (IOException e) {
22 e.printStackTrace();
23 }
24 long endMili=System.currentTimeMillis();
25 System.out.println("总耗时为:"+(endMili-startMili)+"毫秒");
26 }
27 }
注:红色代码为改进前后的代码对比
运行效果:
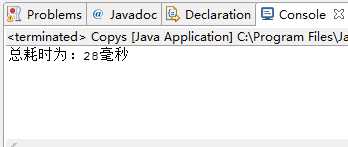
总结:
1. 字节流拷贝文件步骤如下:
①.构造文件字节输入输出流
②.创建一个字节数组,用来指定每次复制的字节大小
③.输入流从源文件读取字节,输出流将字节写入文件
2. fis.read(bys)的作用是从源文件最多读取bys.length字节的数据送给bys数组,返回的是读入的字节总数。
本例中bys.length的长度指定为1024000,当最后一次不足1024000,例如只剩下5000字节时,返回的就是5000,此时所有字节读取完毕。下一次读入时由于已到达文件末尾,返回-1。
fos.write(bys, 0, len)意思是将byte数组从偏移量0开始的n个字节写入文件输出流。
3. 程序结束后要关闭输入输出流。
标签:
原文地址:http://www.cnblogs.com/lwlll123/p/5376911.html