标签:
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
object MapValues {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
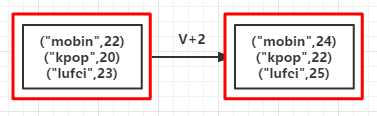
val list = List(("mobin",22),("kpop",20),("lufei",23))
val rdd = sc.parallelize(list)
val mapValuesRDD = rdd.mapValues(_+2)
mapValuesRDD.foreach(println)
}
}
(mobin,24) (kpop,22) (lufei,25)

//省略
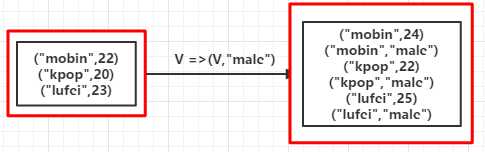
val list = List(("mobin",22),("kpop",20),("lufei",23)) val rdd = sc.parallelize(list) val mapValuesRDD = rdd.flatMapValues(x => Seq(x,"male")) mapValuesRDD.foreach(println)
(mobin,22) (mobin,male) (kpop,20) (kpop,male) (lufei,23) (lufei,male)
(mobin,List(22, male)) (kpop,List(20, male)) (lufei,List(23, male))

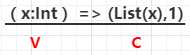





object CombineByKey {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("combinByKey")
val sc = new SparkContext(conf)
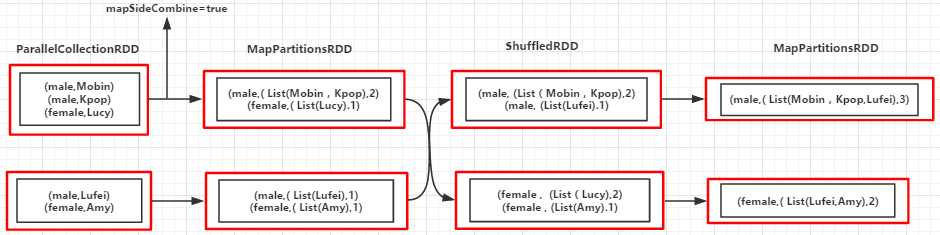
val people = List(("male", "Mobin"), ("male", "Kpop"), ("female", "Lucy"), ("male", "Lufei"), ("female", "Amy"))
val rdd = sc.parallelize(people)
val combinByKeyRDD = rdd.combineByKey(
(x: String) => (List(x), 1),
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1),
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2))
combinByKeyRDD.foreach(println)
sc.stop()
}
}
(male,(List(Lufei, Kpop, Mobin),3)) (female,(List(Amy, Lucy),2))
Partition1: K="male" --> ("male","Mobin") --> createCombiner("Mobin") => peo1 = ( List("Mobin") , 1 ) K="male" --> ("male","Kpop") --> mergeValue(peo1,"Kpop") => peo2 = ( "Kpop" :: peo1_1 , 1 + 1 ) //Key相同调用mergeValue函数对值进行合并 K="female" --> ("female","Lucy") --> createCombiner("Lucy") => peo3 = ( List("Lucy") , 1 ) Partition2: K="male" --> ("male","Lufei") --> createCombiner("Lufei") => peo4 = ( List("Lufei") , 1 ) K="female" --> ("female","Amy") --> createCombiner("Amy") => peo5 = ( List("Amy") , 1 ) Merger Partition: K="male" --> mergeCombiners(peo2,peo4) => (List(Lufei,Kpop,Mobin)) K="female" --> mergeCombiners(peo3,peo5) => (List(Amy,Lucy))

//省略
val people = List(("Mobin", 2), ("Mobin", 1), ("Lucy", 2), ("Amy", 1), ("Lucy", 3))
val rdd = sc.parallelize(people)
val foldByKeyRDD = rdd.foldByKey(2)(_+_)
foldByKeyRDD.foreach(println)
(Amy,2) (Mobin,4) (Lucy,6)
//省略
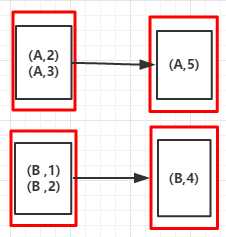
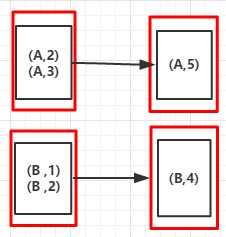
val arr = List(("A",3),("A",2),("B",1),("B",3))
val rdd = sc.parallelize(arr)
val reduceByKeyRDD = rdd.reduceByKey(_ +_)
reduceByKeyRDD.foreach(println)
sc.stop
(A,5) (A,4)

//省略
val arr = List(("A",1),("B",2),("A",2),("B",3))
val rdd = sc.parallelize(arr)
val groupByKeyRDD = rdd.groupByKey()
groupByKeyRDD.foreach(println)
sc.stop
(B,CompactBuffer(2, 3)) (A,CompactBuffer(1, 2))
//省略sc
val arr = List(("A",1),("B",2),("A",2),("B",3))
val rdd = sc.parallelize(arr)
val sortByKeyRDD = rdd.sortByKey()
sortByKeyRDD.foreach(println)
sc.stop
(A,1) (A,2) (B,2) (B,3)
//省略
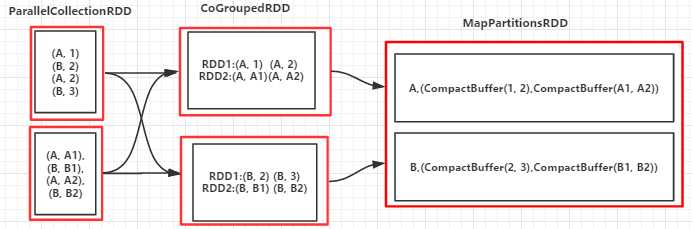
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd1 = sc.parallelize(arr, 3)
val rdd2 = sc.parallelize(arr1, 3)
val groupByKeyRDD = rdd1.cogroup(rdd2)
groupByKeyRDD.foreach(println)
sc.stop
(B,(CompactBuffer(2, 3),CompactBuffer(B1, B2))) (A,(CompactBuffer(1, 2),CompactBuffer(A1, A2)))

//省略
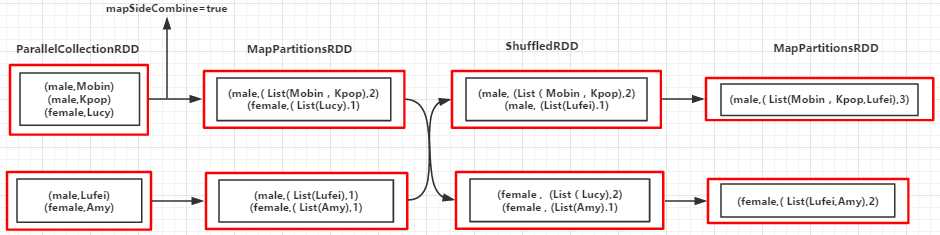
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val groupByKeyRDD = rdd.join(rdd1)
groupByKeyRDD.foreach(println)
(B,(2,B1)) (B,(2,B2)) (B,(3,B1)) (B,(3,B2)) (A,(1,A1)) (A,(1,A2)) (A,(2,A1)) (A,(2,A2)

//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3),("C",1))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val leftOutJoinRDD = rdd.leftOuterJoin(rdd1)
leftOutJoinRDD .foreach(println)
sc.stop
(B,(2,Some(B1))) (B,(2,Some(B2))) (B,(3,Some(B1))) (B,(3,Some(B2))) (C,(1,None)) (A,(1,Some(A1))) (A,(1,Some(A2))) (A,(2,Some(A1))) (A,(2,Some(A2)))
//省略
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"),("C","C1"))
val rdd = sc.parallelize(arr, 3)
val rdd1 = sc.parallelize(arr1, 3)
val rightOutJoinRDD = rdd.rightOuterJoin(rdd1)
rightOutJoinRDD.foreach(println)
sc.stop
(B,(Some(2),B1)) (B,(Some(2),B2)) (B,(Some(3),B1)) (B,(Some(3),B2)) (C,(None,C1)) (A,(Some(1),A1)) (A,(Some(1),A2)) (A,(Some(2),A1)) (A,(Some(2),A2))
标签:
原文地址:http://www.cnblogs.com/MOBIN/p/5384543.html