标签:
IK分词器相对于mmseg4J来说词典内容更加丰富,但是没有mmseg4J灵活,后者可以自定义自己的词语库。IK分词器的配置过程和mmseg4J一样简单,其过程如下:
1.引入IKAnalyzer.jar包到solr应用程序的WEB-INF/lib/目录下
2.打开solr的home/conf目录下的schema文件,在<types></types>内加入如下代码:
<fieldType name="text_zh" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart ="false"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart ="false"/> </analyzer> </fieldType>
3.(可选)在配置文件的<fields></fields>内加入如下代码:加入之后可以根据name来调用该分词器。如果不加入只能根据上面配置的type(即text_zh)进行搜索:
<field name="title_zh" type="text_zh" indexed="true" stored="true"/>
4.重启服务器,访问:http://localhost:8080/solr/admin/analysis.jsp,截图如下:
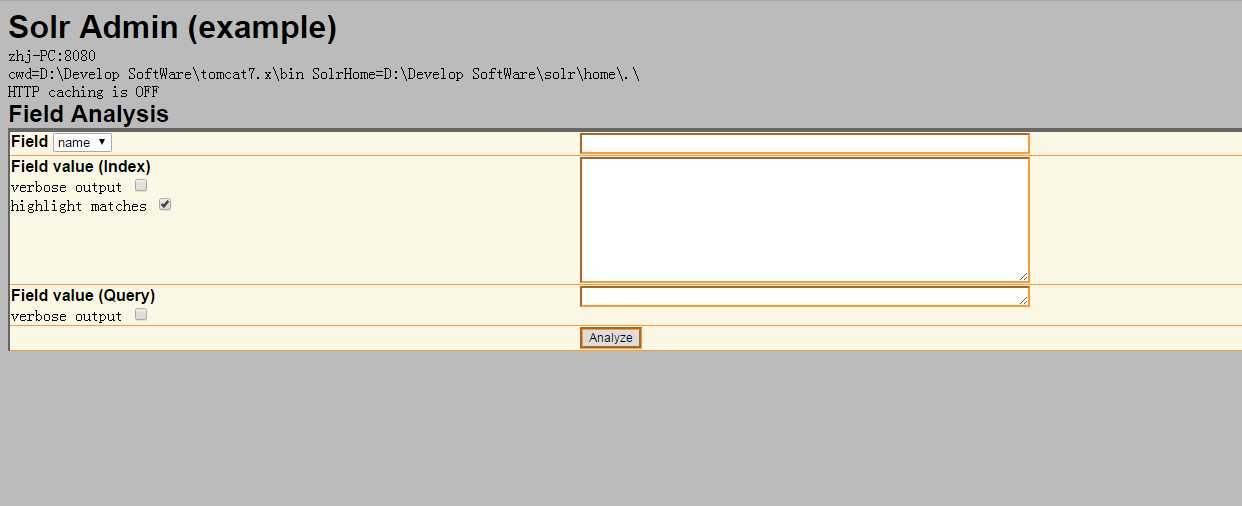
5.可以根据Field的type或者name来进行查询,在Field value中输入要分词的字段,结果如下图:
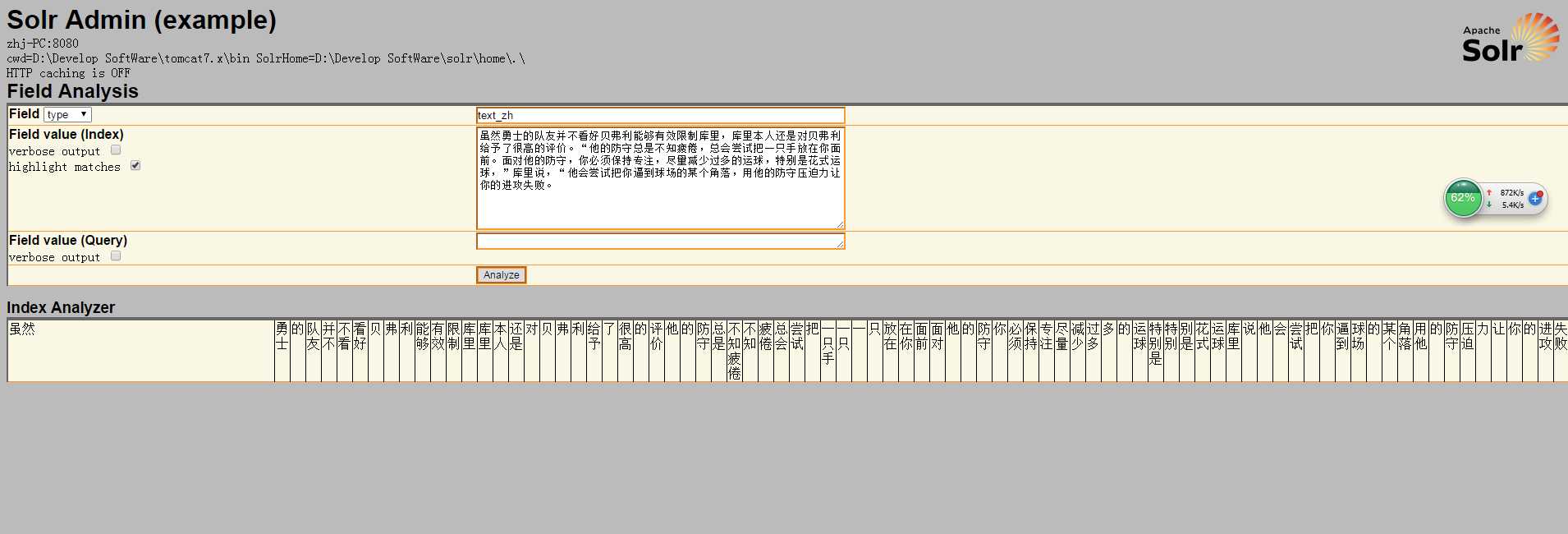
这样就完成了IK中文分词器的配置。
标签:
原文地址:http://www.cnblogs.com/huajiezh/p/5398732.html