标签:
在关键词抽取研究中,最常用的一种方法就是通过计算一篇文档中词语的TF-IDF值(term frequency-inverse document frequency),并对它们进行排序选取TopK个作为关键词,这是一种无监督的方法。另外一种方法是通过有监督的方法,通过训练学习一个分类器,将关键词抽取问题转化为对每个词语的二分类问题,从而选择出合适的关键词。
无监督和有监督各有各的优势和缺点:无监督学习,不需要人工标注,训练集合的过程,因此更加方便和快捷;然而监督学习的方法,在进行了机器学习后,分类器更具有判断多种信息对关键词影响的能力,效果更优。但在信息爆炸的网络时代,人工标注训练集是非常耗时耗力的事情,更何况网络文档的主题常常随着时间变化剧烈,为了使分类器随时能够适应网络就必须随时进行训练和标注,显然这是不现实的。因此关键词抽取的研究主要还是集中在无监督的方法。
在信息检索领域,HITS算法和PageRank算法是搜索引擎中两个最基础和最重要的算法。其基本思想都是首先利用网页之间的链接关系构建网页的网络图,通过相邻节点之间的网页的重要性,计算出某个网页的重要性。
受PageRank的启发,提出了一种基于图的排序算法TextRank,通过将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系,然后利用PageRank计算网络图中词的重要性,选取重要性TopK个词作为关键词。同理也可将最初用于网页排序的HITS算法用来抽取关键词。
input: 一篇文档 output: k个关键词
一.构建文档的词典
1. 去除停用词。
2. 消重。
3. 获得词典 vocab。
二.构建词-词之间的关联矩阵
matrix[i][j]: 表示i词与j词之间的权值。初始值为0
1. 文章已分好段落。
2. 在一段新闻中,若w1和w2共现,则matrix[w1][w2]++,matrix[w2][w1]++
三.利用词-词之间的关联矩阵构建词语之间的无向拓扑图
四.评价节点重要性
计算拓扑图中每一个节点的PageRank值和Authority值用来评价节点的重要性,最后取TopK个节点作为本篇文章的关键词。
PageRank的思想在于将一个网页级别/重要性的排序问题转化成了一个公共参与、以群体民主投票的方式求解的问题,网页之间的链接即被认为是投票行为。同时,各个站点投票的权重不同,重要的网站投票具有较大的分量,而该网站是否重要的标准还需要依照其PageRank值。
现在假设有4个网站A、B、C、D,则它们的初始PageRank都是0.25。对于B而言的话,它把自己的总价值分散投给了A和C,各占一半的PageRank,即0.125,C和D的情况同理。即一个网站投票给其它网站PageRank的值,需要除以它所链接到的网站总数。此时PageRank的计算公式为:
PR(A) = PR(B) / 2 + PR(C) / 1 + PR(D) / 3
PR(B) = PR(D) / 3
PR(C) = PR(B) / 2 + PR(D) / 3
PR(D) = 0

| PageRank | PR(A) | PR(B) | PR(C) | PD(D) |
|---|---|---|---|---|
| 初始值 | 0.25 | 0.25 | 0.25 | 0.25 |
| 第一次迭代后 | 0.4583 | 0.0833 | 0.2083 | 0 |
| 第二次迭代后 | 0.25 | 0 | 0.0417 | 0 |
| 第三次迭代后 | 0.0417 | 0 | 0 | 0 |
| 第四次迭代后 | 0 | 0 | 0 | 0 |
PageRank值计算过程的一般步骤可以概括如下:
(1)为每个网站设置一个初始的PageRank值。
(2)第一次迭代:每个网站得到一个新的PageRank。
(3)第二次迭代:用这组新的PageRank再按上述公式形成另一组新的PageRank。
上图中,顶点A由于无出度像黑洞一样吸收所有PR值,最后导致所有PR值为0。为了防止这种情况的发生,有人给出了一种解决办法:即如果一个网站没有外链,那么就假定该连通图内其余所有的网点都是它的外链,这样我们就避免了整体PageRank值被吸收的现象。

针对以上该图,建立概率转移矩阵P,P[i][j]表示从顶点i到达顶点j的概率,那么矩阵表示就是:
0 0.5 0 0.5
0 0 1 0
0 0 0 1
0 1 0 0
我们所给定的初始向量是:(0.25 0.25 0.25 0.25),做第一次迭代,就相当于用初始向量乘以上面的矩阵。第二次迭代就相当于第一次迭代的结果再乘以上面的矩阵……设转移概率矩阵为P,若存在正整数N,使得P^N>0(每个元素大于0),这种链被称作正则链,它存在唯一的极限状态概率,并且与初始状态无关。
假设{A, B, C}为马氏链,其转移概率矩阵如下所示:
0.7 0.1 0.2
0.1 0.8 0.1
0.05 0.05 0.9
因为该马氏链是不可约的非周期的有限状态,平稳分布存在,则我们要求其平衡分布为:
X = 0.7X + 0.1Y + 0.05Z
Y = 0.1X + 0.8Y + 0.05Z
Z = 0.2X + 0.1Y + 0.9Z
X + Y + Z = 1
解得上述方程组的平稳分布为:X = 0.1765,Y = 0.2353,Z = 0.5882。
把PageRank收敛性问题转化为了求马尔可夫链的平稳分布的问题,那么我们就可以从马氏链的角度来分析问题。因此,对于PageRank的收敛性问题的证明也就迎刃而解了,只需要证明马氏链在什么情况下才会出现平稳分布即可。
所谓“Authority”页面,是指与某个领域或者某个话题相关的高质量网页,比如搜索引擎领域,Google和百度首页即该领域的高质量网页,比如视频领域,优酷和土豆首页即该领域的高质量网页。
所谓“Hub”页面,指的是包含了很多指向高质量“Authority”页面链接的网页,比如hao123首页可以认为是一个典型的高质量“Hub”网页。
假设1:一个好的“Authority”页面会被很多好的“Hub”页面指向;
假设2:一个好的“Hub”页面会指向很多好的“Authority”页面;
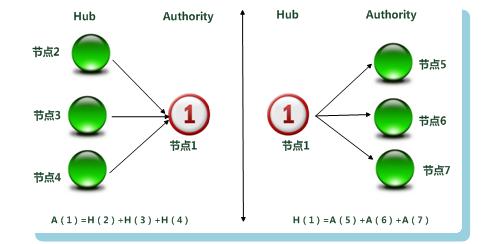
具体算法:可利用上面提到的两个基本假设,以及相互增强关系等原则进行多轮迭代计算,每轮迭代计算更新每个页面的两个权值,直到权值稳定不再发生明显的变化为止。
在网页排名中,HITS算法是与用户输入的查询请求密切相关的,即HITS算法在使用之前必须构建一个根集合,由于本次项目集中研究HITS算法在文档网络的运用价值,所以在此不详细说明。
具体流程
一、a(i), h(i)分别表示结点i的Authority Score 和 Hub值(中心度)
二、在初始情况下,在没有更多可利用信息前,每个页面的这两个权值都是相同的,可以都设置为1,即:a(i)=1, h(i)=1
三、每次迭代计算Hub权值和Authority权值:
网页 a (i)在此轮迭代中的Authority权值即为所有指向网页 a (i)页面的Hub权值之和:
a (i) = Σ h (i) ;
网页 a (i)的Hub分值即为所指向的页面的Authority权值之和:
h (i) = Σ a (i) 。
对a (i)、h (i)进行规范化处理:
将所有网页的中心度都除以最高中心度以将其标准化:
a (i) = a (i)/|a(i)| ;
将所有网页的权威度都除以最高权威度以将其标准化:
h (i) = h (i)/ |h(i)| :
四、收敛
上一轮迭代计算中的权值和本轮迭代之后权值的差异,如果发现总体来说权值没有明显变化,说明系统已进入稳定状态,则可以结束计算,即a ( u),h(v)收敛 。
新闻报道:
原标题:陈君文一行到长沙县调研两型住宅产业化工作
红网长沙县站3月17日讯(星沙时报记者 廖真怡)昨日,湖南省人大常委会副主任陈君文率队来到长沙县,就两型住宅产业化工作开展实地调研。长沙县人大常委会主任李建章,副主任彭军其,副县长李开兴陪同调研。
在福临镇泉源村集中安置房项目现场,调研组一行参观了该示范点去年底新建完成的轻钢结构房屋。据介绍,轻钢结构房屋是以冷弯薄壁型钢为结构体系的绿色建筑,具备抗震防火、保温隔热、节能环保等诸多特点。一栋250平方米的轻钢结构房屋建成耗时不到两个月,村民只需花费约六十万元即可入住。
近年来,长沙县加快推进两型住宅产业化工作,逐步将保障性住房、棚户区改造、学校、医院等政府投资类建设项目纳入两型住宅产业化实施。目前,已启动福临镇泉源村、影珠山村住宅产业化的试点工作,建成4栋冷弯薄壁轻钢房屋,均选择了农民集中居住点进行统一规划设计,集中运用住宅产业化技术建设。
陈君文强调,轻钢结构房屋集环保、节能、高效等优点于一体,符合绿色发展理念,在农村住房改造中值得大力推广。政府要出台相关政策加以扶持,示范点则要积极发挥带头引领作用,通过政府、市场两手抓,推动项目又好又快发展。
利用textRank抽取关键词
轻钢 0.01902440798
房屋 0.01902440798
长沙县 0.0139585118277
两型 0.0139585118277
住宅 0.0139585118277
产业化 0.0139585118277
工作 0.0139585118277
福临 0.0136226056716
泉源 0.0136226056716
薄壁 0.0136226056716
耗时:0.0591039657593s
利用jieba包中内置基于tf-idf提取关键词
轻钢 0.386129934778
长沙县 0.309113581381
产业化 0.267338155519
两型 0.265661500064
住宅 0.234284985021
陈君文 0.199246125048
房屋 0.183773798317
泉源 0.136569330439
结构 0.13419387805
示范点 0.124362527232
耗时:0.00664782524109s
新闻报道:
原标题:美国宣布对朝鲜新的制裁措施
据新华社电 美国政府16日宣布对朝鲜实施新的制裁措施。
美国白宫的一份新闻公告说,总统奥巴马当天发布行政令,旨在冻结朝鲜政府和朝鲜劳动党资产,禁止与朝鲜的特定交易。
美国财政部随后发布新闻公告,对朝鲜17个政府官员和机构以及20艘船只实施制裁。
新制裁针对朝鲜的能源、矿业、金融服务和交通业,禁止对朝鲜的商品、服务、技术出口以及在朝鲜进行新的投资。
白宫的新闻公告说,美国将继续对朝鲜施压,令其付出“代价”,直至朝鲜最终履行国际责任和义务。
联合国安理会3月2日一致通过第2270号决议,针对朝鲜核、导计划规定一系列制裁措施,重申支持重启六方会谈及通过和平方式实现半岛无核化。
利用textRank抽取关键词
朝鲜 0.0324132510978
制裁 0.0239090726699
公告 0.0206482233926
新闻 0.0165485844427
禁止 0.0164814054247
措施 0.0158486641078
实施 0.0138236030274
美国 0.0133183833419
朝鲜劳动党 0.012182643101
资产 0.012182643101
耗时: 0.0261380672455s
利用jieba包中内置基于tf-idf提取关键词
朝鲜 0.645829143617
制裁 0.427122149321
公告 0.161725613834
措施 0.161613619075
禁止 0.133688805542
针对 0.118448597479
20 0.11720360297
17 0.11720360297
16 0.11720360297
2270 0.11720360297
耗时: 0.00232791900635s
本次实验主要针对新浪网中近100条新闻作为实验的测试集,通过人工统计,对比评价基于图的关键词提取法(textRank)以及基于tf-idf的关键词的抽取法。其中选取了最具代表性2篇新闻作为本次的实验的实验样本。
实验一的关键词提取效果中,textRank和tf-idf均能较好提取出关键词,二个算法之间的关键词提取效果也并没有太大的差异。然而二者之间的耗时却有着明显的差异。由于textRank算法中涉及到网络图的构建以及多轮迭代,所以性能上普遍比tf-idf要低上一截。(jieba包中已包含了常见词语的idf词语,因此不需要大量文档进行学习)
实验二的关键词的提取效果中就有着明显差异,由于jieba包内置的tf-idf关键词提取算法,并不存在实时标注和学习的过程,在面对不同的主题的新闻时,关键词的提取效果就有些差异。如实验二中,textRank所抓取的10个关键词都较符合新闻的主题,而tf-idf所提取的就有少些无实际意义的词作为关键词。
总结,基于图的关键词的提取中算法,较于传统的tf-idf关键词提取效果有一定的提高。然而在本次实验室中的100多个测试集中,粗略统计,大多数新闻的关键词的提取中,tf-idf的关键词提取效果与textRank相比,并无多大差异。因此我觉得在实际应用中,还需要综合各种情况选取合适的算法。
https://link.zhihu.com/?target=http%3A//nlp.csai.tsinghua.edu.cn/%7Elzy/publications/phd_thesis.pdf
http://blog.csdn.net/MONKEY_D_MENG/article/details/6554518
http://blog.csdn.net/hguisu/article/details/8013489
标签:
原文地址:http://blog.csdn.net/hareric/article/details/51164632