标签:
他:为什么要在Docker上搭建Spark集群啊?
我:因为……我行啊!
MR和Spark都提供了local模式,即在单机上模拟多计算节点来执行任务。但是,像我这等手贱的新手,怎么会满足于“模拟”?很容易想到在单机上运行多个虚拟机作为计算节点,可是考虑到PC的资源有限,即使能将集群运行起来,再做其他的工作已经是超负荷了。Docker是一种相比虚拟机更加轻量级的虚拟化解决方案,所以在Docker上搭建Spark集群具有可行性。
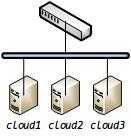
搭建一个有意义的小规模集群,我选择了3台服务器作为Spark计算节点(Worker)。集群中光有计算节点还不够,这3台服务器同时也作为分布式文件系统(HDFS)的数据节点(DataNode)。指定了哪些服务器用来计算,哪些用来存储之后,我们还需要指定来管理计算和存储的主节点。一个简单方案:我们可以让cloud1作为管理计算节点的主节点(Master),同时它也作为管理数据节点的主节点(NameNode)。
很容易看到简单方案不够完美:首先,要是cloud1作为NameNode宕机,整个分布式文件系统则无法工作。此时,我们应当采用基于HA的HDFS方案:由多个NameNode共同管理DataNode,但是只有一个NameNode处于活动(Active)状态,当活动的NameNode无法工作时,则需要其他NameNode候补。这里至少涉及2个关键技术:
再者,选用cloud1作为Master来管理计算(standalone)的方式对资源的利用率不比Yarn方式。所以,在本集群中选用cloud1做为ResourceManager,3台服务器都作为NodeManager)。
改进后的集群描述如下:
| 节点 | Zkserver | NameNode | JournalNode | ResourceManager | NodeManager |
Master |
Worker |
| cloud1 | √ | √ | √ | √ | √ | √ | √ |
| cloud2 | √ | √ | √ | × | √ | × | √ |
| cloud3 | √ | × | √ | × | √ | × | √ |
Docker有Windows/Mac/Linux版本。起初我处于对Docker的误解选择了Windows版本,Docker的核心程序必须运行在Linux上,故Windows版本的Docker实际上是利用VirtualBox运行着一个精简的Linux,然后在此Linux上运行Docker,最后在Docker上运行安装好应用的镜像。好家伙,盗梦空间!最终,我选择在CentOS上安装Linux版本的Docker。关于Docker,我们需要理解一个重要的概念:容器(Container)。容器是镜像运行的场所,可以在多个容器中运行同一个镜像。
Docker安装好之后,我们启动Docker服务:
1 systemctl start docker.service
我们可以拉一个Ubuntu镜像,基于该镜像我们搭建Spark集群:
1 docker pull ubuntu
下载好镜像到本地后,我们可以查看镜像:
1 docker images
使用run命令,创建一个容器来运行镜像:
1 docker run -it ubuntu
使用ps命令查看容器:
1 docker ps -a
使用commit命令来将容器提交为一个镜像:
1 docker commit <container id|name>
使用tag命令来为一个镜像打标签:
1 docker tag <mirror id> <tag>
使用start命令来启动一个容器:
1 docker start -a <container id|name>
在掌握了以上操作后,在Docker上搭建Spark集群的技术路线如下:
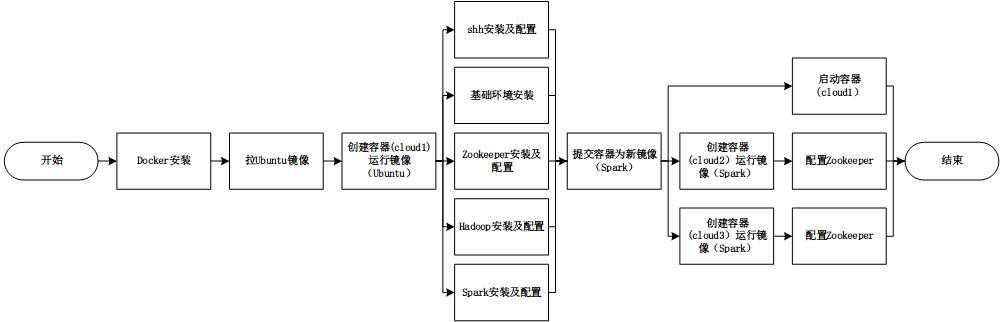
试想一下如何启动集群?手动去每个节点启动相应的服务?这显然是不合理的。HDFS,Yarn,Spark都支持单命令启动全部节点。在某个节点上执行的命令是如何发送至其他节点的呢?ssh服务帮助实现这一功能。关于ssh我们需要知道其分为服务端和客户端,服务端默认监听22号端口,客户端可与服务端建立连接,从而实现命令的传输。
docker服务启动后,可以看到宿主机上多了一块虚拟网卡(docker0),在我的机器中为172.17.0.1。启动容器后,容器的IP从172.17.0.2开始分配。我们不妨为集群分配IP地址如下:
| 域名 | IP |
| cloud1 | 172.17.0.2 |
| cloud2 | 172.17.0.3 |
| cloud3 | 172.17.0.4 |
关闭所有容器后,新建一个容器,命名为cloud1:
1 #新建容器时需要指定这个容器的域名以及hosts文件 2 #参数: 3 #name:容器名称 4 #h:域名 5 #add-host:/etc/hosts文件中的域名与IP的映射 6 docker --name cloud1 -h cloud1 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it ubuntu
在容器cloud1中通过apt工具来安装ssh:
1 apt-get install ssh
往~/.bashrc中加入ssh服务启动命令:
1 /usr/sbin/sshd
客户端不能任意地与服务端建立连接,或通过密码,或通过密钥认证。在这里我们使用密钥认证,生成客户端的私钥和公钥:
1 #私钥(~/.ssh/id_rsa)由客户端持有 2 #公钥(~/.ssh/id_rsa.pub)交给服务端 3 #已认证的公钥(~/.ssh/authorized_keys)由服务端持有,只有已认证公钥的客户端才能连接至服务端 4 #参数: 5 #t:加密方式 6 #P:密码 7 ssh-keygen -t rsa -P ""
根据技术路线,由cloud1容器提交的镜像将生成cloud2容器和cloud3容器。要实现cloud1对cloud2和cloud3的ssh密钥认证连接,其实只要实现cloud1对本身的连接就可以了:
1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否能连接成功:
1 ssh root@cloud1
Java与Scala版本需要与其他软件的版本相匹配:
| 软件 | 版本 |
| Java | 1.8.0_77 |
| Scala | 2.10.6 |
| Zookeeper | 3.4.8 |
| Hadoop | 2.6.4 |
| Spark | 1.6.1 |
Java与Scala安装包下载后,均解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export JAVA_HOME=/usr/jdk1.8.0_77 2 export PATH=$PATH:$JAVA_HOME/bin 3 export SCALA_HOME=/usr/scala-2.10.6 4 export PATH=$PATH:$SCALA_HOME/bin
Zookeeper安装包下载后,解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export ZOOKEEPER_HOME=/usr/zookeeper-3.4.8 2 export PATH=$PATH:$ZOOKEEPER_HOME/bin
生成Zookeeper配置文件:
1 cp /usr/zookeeper-3.4.8/conf/zoo_sample.cfg /usr/zookeeper-3.4.8/conf/zoo.cfg
修改Zookeeper配置文件:
1 #数据存储目录修改为: 2 dataDir=/root/zookeeper/tmp 3 #在最后添加Zkserver配置信息: 4 server.1=cloud1:2888:3888 5 server.2=cloud2:2888:3888 6 server.3=cloud3:2888:3888
设置当前Zkserver信息:
1 #~/zookeeper/tmp/myid文件中保存的数字代表本机的Zkserver编号 2 #在此设置cloud1为编号为1的Zkserver,之后生成cloud2和cloud3之后还需要分别修改此文件 3 echo 1 > ~/zookeeper/tmp/myid
Hadoop安装包下载后,解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export HADOOP_HOME=/usr/hadoop-2.6.4 2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改Hadoop启动配置文件(/usr/hadoop-2.6.4/etc/hadoop/hadoop-env.sh):
1 #修改JAVA_HOME 2 export JAVA_HOME=/usr/jdk1.8.0_77
修改核心配置文件(/usr/hadoop-2.6.4/etc/hadoop/core-site.xml):
| 参数 | 说明 |
| fs.defaultFS | 默认的文件系统 |
| hadoop.tmp.dir | 临时文件目录 |
| ha.zookeeper.quorum | Zkserver信息 |
1 <property> 2 <name>fs.defaultFS</name> 3 <value>hdfs://ns1</value> 4 </property> 5 <property> 6 <name>hadoop.tmp.dir</name> 7 <value>/root/hadoop/tmp</value> 8 </property> 9 <property> 10 <name>ha.zookeeper.quorum</name> 11 <value>cloud1:2181,cloud2:2181,cloud3:2181</value> 12 </property>
修改HDFS配置文件(/usr/hadoop-2.6.4/etc/hadoop/hdfs-site.xml):
| 参数 | 说明 |
| dfs.nameservices | 名称服务,在基于HA的HDFS中,用名称服务来表示当前活动的NameNode |
| dfs.ha.namenodes.<nameservie> | 配置名称服务下有哪些NameNode |
| dfs.namenode.rpc-address.<nameservice>.<namenode> | 配置NameNode远程调用地址 |
| dfs.namenode.http-address.<nameservice>.<namenode> | 配置NameNode浏览器访问地址 |
| dfs.namenode.shared.edits.dir | 配置名称服务对应的JournalNode |
| dfs.journalnode.edits.dir | JournalNode存储数据的路径 |
1 <property> 2 <name>dfs.nameservices</name> 3 <value>ns1</value> 4 </property> 5 <property> 6 <name>dfs.ha.namenodes.ns1</name> 7 <value>nn1,nn2</value> 8 </property> 9 <property> 10 <name>dfs.namenode.rpc-address.ns1.nn1</name> 11 <value>cloud1:9000</value> 12 </property> 13 <property> 14 <name>dfs.namenode.http-address.ns1.nn1</name> 15 <value>cloud1:50070</value> 16 </property> 17 <property> 18 <name>dfs.namenode.rpc-address.ns1.nn2</name> 19 <value>cloud2:9000</value> 20 </property> 21 <property> 22 <name>dfs.namenode.http-address.ns1.nn2</name> 23 <value>cloud2:50070</value> 24 </property> 25 <property> 26 <name>dfs.namenode.shared.edits.dir</name> 27 <value>qjournal://cloud1:8485;cloud2:8485;cloud3:8485/ns1</value> 28 </property> 29 <property> 30 <name>dfs.journalnode.edits.dir</name> 31 <value>/root/hadoop/journal</value> 32 </property> 33 <property> 34 <name>dfs.ha.automatic-failover.enabled</name> 35 <value>true</value> 36 </property> 37 <property> 38 <name>dfs.client.failover.proxy.provider.ns1</name> 39 <value> 40 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider 41 </value> 42 </property> 43 <property> 44 <name>dfs.ha.fencing.methods</name> 45 <value> 46 sshfence 47 shell(/bin/true) 48 </value> 49 </property> 50 <property> 51 <name>dfs.ha.fencing.ssh.private-key-files</name> 52 <value>/root/.ssh/id_rsa</value> 53 </property> 54 <property> 55 <name>dfs.ha.fencing.ssh.connect-timeout</name> 56 <value>30000</value> 57 </property>
修改Yarn的配置文件(/usr/hadoop-2.6.4/etc/hadoop/yarn-site.xml):
| 参数 | 说明 |
| yarn.resourcemanager.hostname | RescourceManager的地址,NodeManager的地址在slaves文件中定义 |
1 <property> 2 <name>yarn.resourcemanager.hostname</name> 3 <value>cloud1</value> 4 </property> 5 <property> 6 <name>yarn.nodemanager.aux-services</name> 7 <value>mapreduce_shuffle</value> 8 </property>
修改指定DataNode和NodeManager的配置文件(/usr/hadoop-2.6.4/etc/hadoop/slaves):
1 cloud1 2 cloud2 3 cloud3
Spark安装包下载后,解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export SPARK_HOME=/usr/spark-1.6.1-bin-hadoop2.6 2 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
Spark启动配置文件:
1 cp /usr/spark-1.6.1-bin-hadoop2.6/conf/spark-env.sh.template /usr/spark-1.6.1-bin-hadoop2.6/conf/spark-env.sh
修改Spark启动配置文件(/usr/spark-1.6.1-bin-hadoop2.6/conf/spark-env.sh):
| 参数 | 说明 |
| SPARK_MASTER_IP | Master的地址,Worker的地址在slaves文件中定义 |
1 export SPARK_MASTER_IP=cloud1 2 export SPARK_WORKER_MEMORY=128m 3 export JAVA_HOME=/usr/jdk1.8.0_77 4 export SCALA_HOME=/usr/scala-2.10.6 5 export SPARK_HOME=/usr/spark-1.6.1-hadoop2.6 6 export HADOOP_CONF_DIR=/usr/hadoop-2.6.4/etc/hadoop 7 export SPARK_LIBRARY_PATH=$$SPARK_HOME/lib 8 export SCALA_LIBRARY_PATH=$SPARK_LIBRARY_PATH 9 export SPARK_WORKER_CORES=1 10 export SPARK_WORKER_INSTANCES=1 11 export SPARK_MASTER_PORT=7077
修改指定Worker的配置文件(/usr/spark-1.6.1-bin-hadoop2.6/conf/slaves):
1 cloud1 2 cloud2 3 cloud3
在宿主机上提交cloud1容器为新的镜像,并打其标签为Spark:
1 #提交cloud1容器,命令返回新镜像的编号 2 docker commit cloud1 3 #为新镜像打标签为Spark 4 docker tag <mirror id> Spark
基于Spark镜像创建cloud2和cloud3容器:
1 docker --name cloud2 -h cloud2 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it Spark 2 docker --name cloud3 -h cloud3 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it Spark
还记得之前提到的cloud2和cloud3的当前Zkserver还未配置吗?分别在cloud2和cloud3容器中修改Zookeeper配置:
1 #在cloud2执行 2 echo 2 > ~/zookeeper/tmp/myid 3 #在cloud3执行 4 echo 3 > ~/zookeeper/tmp/myid
在所有节点启动Zkserver(Zkserver并不是用ssh启动的,呵呵):
1 zkServer.sh start
在所有节点查看Zkserver运行状态:
1 #显示连接不到Zkserver的错误,可稍后查看 2 #Master表示主Zkserver,Follower表示从Zkserver 3 Zkserver.sh status
初始化其中一个NameNode,就选cloud1吧:
1 #格式化zkfc 2 hdfs zkfc -formatZK 3 #格式化NameNode 4 hdfs namenode -format
在cloud1启动HDFS,Yarn,Spark:
1 #启动NameNode,DataNode,zkfc,JournalNode 2 start-dfs.sh 3 #启动ResouceManager,NodeManager 4 start-yarn.sh 5 #启动Master,Worker 6 start-all.sh
使用jps命令查看各节点服务运行情况:
1 jps
还可以登录web管理台来查看运行状况:
| 服务 | 地址 |
| HDFS | cloud1:50070 |
| Yarn | cloud1:8088 |
| Spark | cloud1:8080 |
标签:
原文地址:http://www.cnblogs.com/jasonfreak/p/5391190.html