标签:
Sphinx是一个全文检索引擎。
遇到一个类似这样的需求:用户可以通过文章标题和文章搜索到一片文章的内容,而文章的标题和文章的内容分别保存在不同的库,而且是跨机房的。
A、直接在数据库实现跨库LIKE查询
优点:简单操作
缺点:效率较低,会造成较大的网络开销
B、结合Sphinx中文分词搜索引擎
优点:效率较高,具有较高的扩展性
缺点:不负责数据存储
使用Sphinx搜索引擎对数据做索引,数据一次性加载进来,然后做了所以之后保存在内存。这样用户进行搜索的时候就只需要在Sphinx服务器上检索数据即可。而且,Sphinx没有MySQL的伴随机磁盘I/O的缺陷,性能更佳。
1、快速、高效、可扩展和核心的全文检索
2、高效地使用WHERE子句和LIMIT字句
当在多个WHERE条件做SELECT查询时,索引选择性较差或者根本没有索引支持的字段,性能较差。sphinx可以对关键字做索引。区别是,MySQL中,是内部引擎决定使用索引还是全扫描,而sphinx是让你自己选择使用哪一种访问方法。因为sphinx是把数据保存到RAM中,所以sphinx不会做太多的I/O操作。而mysql有一种叫半随机I/O磁盘读,把记录一行一行地读到排序缓冲区里,然后再进行排序,最后丢弃其中的绝大多数行。所以sphinx使用了更少的内存和磁盘I/O。
3、优化GROUP BY查询
在sphinx中的排序和分组都是用固定的内存,它的效率比类似数据集全部可以放在RAM的MySQL查询要稍微高些。
4、并行地产生结果集
sphinx可以让你从相同数据中同时产生几份结果,同样是使用固定量的内存。作为对比,传统SQL方法要么运行两个查询,要么对每个搜索结果集创建一个临时表。而sphinx用一个multi-query机制来完成这项任务。不是一个接一个地发起查询,而是把几个查询做成一个批处理,然后在一个请求里提交。
5、向上扩展和向外扩展
6、聚合分片数据
适合用在将数据分布在不同物理MySQL服务器间的情况。
例子:有一个1TB大小的表,其中有10亿篇文章,通过用户ID分片到10个MySQL服务器上,在单个用户的查询下当然很快,如果需要实现一个归档分页功能,展示某个用户的所有朋友发表的文章。那么就要同事访问多台MySQL服务器了。这样会很慢。而sphinx只需要创建几个实例,在每个表里映射出经常访问的文章属性,然后就可以进行分页查询了,总共就三行代码的配置。
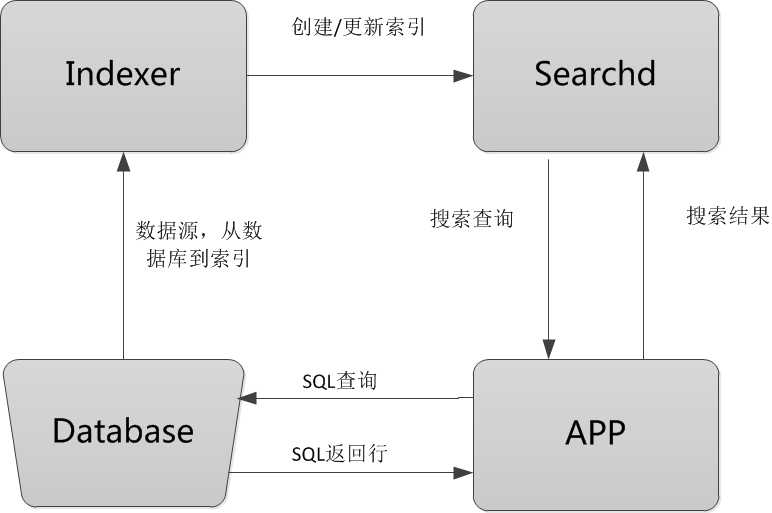
Database:数据源,是Sphinx做索引的数据来源。因为Sphinx是无关存储引擎、数据库的,所以数据源可以是MySQL、PostgreSQL、XML等数据。
Indexer:索引程序,从数据源中获取数据,并将数据生成全文索引。可以根据需求,定期运行Indexer达到定时更新索引的需求。
Searchd:Searchd直接与客户端程序进行对话,并使用Indexer程序构建好的索引来快速地处理搜索查询。
APP:客户端程序。接收来自用户输入的搜索字符串,发送查询给Searchd程序并显示返回结果。
Sphinx的整个工作流程就是Indexer程序到数据库里面提取数据,对数据进行分词,然后根据生成的分词生成单个或多个索引,并将它们传递给searchd程序。然后客户端可以通过API调用进行搜索。
标签:
原文地址:http://www.cnblogs.com/h-hq/p/5402420.html