标签:
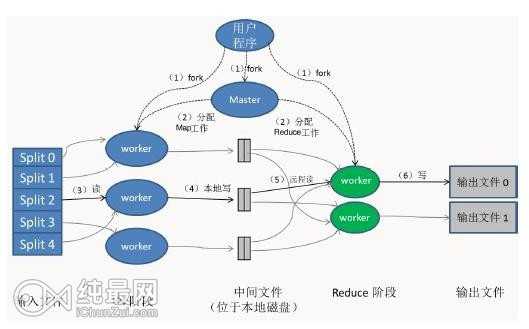
图展示了MapReduce实现中的全部流程,处理步骤如下:
1、用户程序中的MapReduce函数库首先把输入文件分成M块(每块大小默认64M),在集群上执行处理程序,见序号1
2、主控程序master分配Map任务和Reduce任务给工作执行机器worker。见序号2
3、一个分配了Map任务的worker读取并处理输入数据块。从数据片段中解析出key/value键值对,然后把其传递给Map函数,由Map函数生成并输出中间key/value键值对集合,暂缓内存中。见序号3
4、缓存中key/value键值对通过分区函数分成R个区域,之后周期性地写到本地磁盘上。同时将本地磁盘的存储位置传给master,由master负责把这些存储位置再传递给Reduce worker,见序号4
5、当Reduce worker收到master的存储位置信息后,使用RPC从Map worker所在的磁盘上读取数据。最后通过对key进行排序使得具有key值的数据聚合到一起。见序号5
6、Reduce worker程序遍历排序后的中间数据。Reduce worker程序将这个key值和相关的中间value值的集合传递给Rdeduce函数,最后,Reduce的输出被追加到所属分区的输入文件。见序号6
MapReduce的JobTracker接收到客户端提交的作业后首先要把作业初始化为Map任务和Reduce任务,然后等待调度执行。
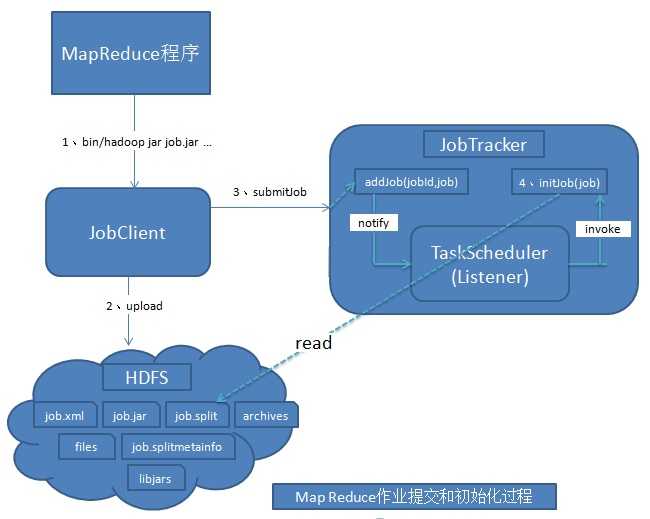
图中展示了MapReduce客户端提交作业以及初始化的流程。
作业提交过程:
1、命令行提交。调用JobClient.runJob()方法开始提交,最终通过Job对象内部JobClient对象的submitJobInternal方法来提交作业到JobTracker。
2、作业上传。在提交到JobTracker之前还需要完成相关的初始化工作(获取用户作业的JobId,创建HDFS目录,上传作业、相关依赖库,需要分发的文件等到HDFS上,获取用户输入数据的所有分片信息)。
3、产生切片文件。在作业提交后,JobClient调用InputFormat中的getSplits()方法产生用户数据的split分片信息。
4、提交作业到JobTracker。JobClient通过RPC将作业提交到JobTracker作业调度器中,首先为作业创建JobInProgress对象,用于跟踪正在运行的作业的状态和进度。其次检查用户是否具有指定队列的作业提交权限。接着检查作业配置的内存使用量是否合理。最后通过TaskScheduler初始化作业,JobTracker收到提交的作业后,会交给TaskScheduler调度器,然后按照一定的策略对作业执行初始化操作。
作业的初始化:主要是构造Map Task和Reduce Task并对他们进行初始化操作,主要是调度器调用JobTracker.initJob()方法来进行的。具体分为四个类型的任务:
Setup Task--->Map Task--->Reduce Task--->Cleanup Task
标签:
原文地址:http://www.cnblogs.com/liuzhongfeng/p/5405130.html