标签:
1. softmax回归模型
softmax回归模型是logistic回归模型在多分类问题上的扩展(logistic回归解决的是二分类问题)。
对于训练集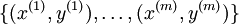 ,有。
,有。
对于给定的测试输入 ,我们相拥假设函数针对每一个类别j估算出概率值
,我们相拥假设函数针对每一个类别j估算出概率值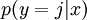 。也就是说,我们估计得每一种分类结果出现的概率。因此我们的假设函数将要输入一个
。也就是说,我们估计得每一种分类结果出现的概率。因此我们的假设函数将要输入一个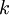 维的向量来表示这个估计得概率值。假设函数
维的向量来表示这个估计得概率值。假设函数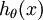 形式如下:
形式如下:
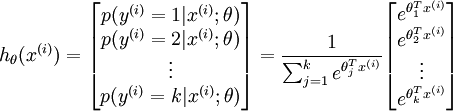
其中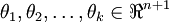 是模型的参数。
是模型的参数。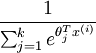 这一项对概率分布进行归一化,舍得所有概率之和为1.
这一项对概率分布进行归一化,舍得所有概率之和为1.
softmax回归的代价函数:
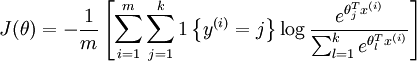
上述公式是logistic回归代价函数的推广。logistic回归代价函数可以改为:
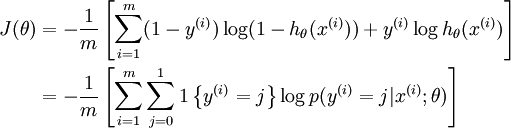
可以看到,softmax代价函数与logistic代价函数在形式上非常类似,只是在softmax损失函数中对类标记的个可能值进行了累加。注意在softmax回归中将分类为 的概率为:
的概率为:
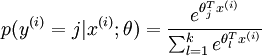
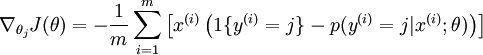 有了上面的偏导数公式以后,我们就可以将它代入到梯度下降法等算法中,来最小化
有了上面的偏导数公式以后,我们就可以将它代入到梯度下降法等算法中,来最小化 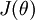 。 例如,在梯度下降法的标准实现中,每一次迭代需要进行如下更新:
。 例如,在梯度下降法的标准实现中,每一次迭代需要进行如下更新:
2. 权重衰减
在实际应用中,为了使算法实现更简单清楚,往往保留所有参数 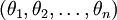 ,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
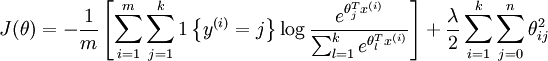
我们通过添加一个权重衰减项 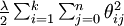 来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
有了这个权重衰减项以后 (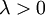 ),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度 下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度 下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
为了使用优化算法,我们需要求得这个新函数 的导数,如下:
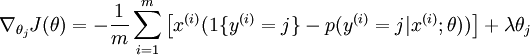
通过最小化 ,我们就能实现一个可用的 softmax 回归模型。
3. 模型选择
如果你在开发一个音乐分类的应用,需要对k种类型的音乐进行识别,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢?
这一选择取决于你的类别之间是否互斥,例如,如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数 k = 4 的softmax回归。
如果你的四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
现在我们来看一个计算视觉领域的例子,你的任务是将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。你会使用sofmax回归还是 3个logistic 回归分类器呢? (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片,你又会选择 softmax 回归还是多个 logistic 回归分类器呢?
在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。
转自:http://www.cnblogs.com/Rosanna/p/3865212.html
参考:http://deeplearning.stanford.edu/wiki/index.php/Softmax回归
标签:
原文地址:http://www.cnblogs.com/fclbky/p/5408796.html