标签:
a.ElasticSearch是一个基于Lucene开发的搜索服务器,具有分布式多用户的能力,ElasticSearch是用Java开发的开源项目(Apache许可条款),基于Restful Web接口,能够达到实时搜索、稳定、可靠、快速、高性能、安装使用方便,同时它的横向扩展能力非常强,不需要重启服务。
b.ElasticSearch是一个非常好用的实时分布式搜索和分析引擎,可以帮助我们快速的处理大规模数据,也可以用于全文检索,结构化搜索以及分析等。
c.目前很多网站都在使用ElasticSearch进行全文检索,例如:GitHub、StackOverflow、Wiki等。
d.ElasticSearch式建立在全文检索引擎Lucene基础上的,而Lucene是最先进、高效的开元搜索引擎框架,但是Lucene只是一个框架,要充分利用它的功能,我们需要很高的学习成本,而ElasticSearch使用Lucene作为内部引擎,在其基础上封装了功能强大的Restful API,让开发人员可以在不需要了解背后复杂的逻辑,即可实现比较高效的搜索。
e.关于Lucene我在前面写过几篇博客,并且在GitHub上开源了一个Demo,博客地址是:http://www.cnblogs.com/hanyinglong/p/5387816.html
f.ElasticSearch官网:https://www.elastic.co/products/elasticsearch/
a.工欲善其事必先利其器,通过上面简单的描述想必大家已经知道ElasticSearch是干什么的了,那么这时候我们就需要去使用它,而在用它之前则必须先将其安装,故而在这篇博客我将简单描述一下EasticSearch的安装,ElasticSearch_Head的配置,分词插件的配置。
b. ElasticSearch的安装包,下载地址:https://www.elastic.co/downloads/elasticsearch,下载最新的tar包即可。
c. ElasticSearch_Head配置包,下载地址:https://github.com/mobz/elasticsearch-head,下载最新的Zip压缩包即可。
d.分词插件,下载地址:https://github.com/medcl/elasticsearch-analysis-ik,克隆源码进行操作。
e.因Elasticsearch是基于java写的,所以它的运行环境中需要java的支持,在Linux下执行命令:java -version,检查Jar包是否安装,如果安装,则可以继续操作安装工作,否则安装java jar包,如何安装请参看博客:http://www.cnblogs.com/hanyinglong/p/5025635.html。(JDK安装7以上)
f. 本次操作需要用到的软件以及系统如下:虚拟机(Vmware)、虚拟机中安装的Centos系统、Xshell、Xftp、上面的安装包、Git、Maven,至于如何使用它们我们下面会说到。
a.通过上面简单的准备工作之后,现在已经拥有了可以安装和发布的环境,如果没有,请参考上面的说明,自行查询安装。
b.使用XShell连接Centos,连接成功后使用命令跳转到local下面创建属于自己的文件夹kencery,在此文件夹下创建elasticsearch文件夹,命令如下;
b.1 (1):cd usr/local/ (2):mkdir kencery (3):cd kencery/ (4):mkdir elasticsearch (5):cd elasticsearch/
c. 然后使用Xftp将在准备安装文件中下载的Elasticsearch包复制到elasticsearch文件夹西面,如图所示:

d. 将上传的的elasticsearch-2.3.1.tar.gz包解压,解压之后命名为:elasticsearch,至于安装包里面含有上面内容,请自行使用命令ls -l查看。
d.1 tar -zxvf elasticsearch-2.3.1.tar.gz
d.2 mv elasticsearch-2.3.1 elasticsearch
e. 进入elasticsearch文件后运行脚本启动,命令如下:
e.1 cd elasticsearch
e.2 调用启动命令:./bin/elasticsearch(如果以root用户启动,正常情况下这里会报错)。
f.在root账户下面调用启动命令出错的解决方案
f.1 当使用root账户调用启动命令出现错误信息,错误提示信息如下:
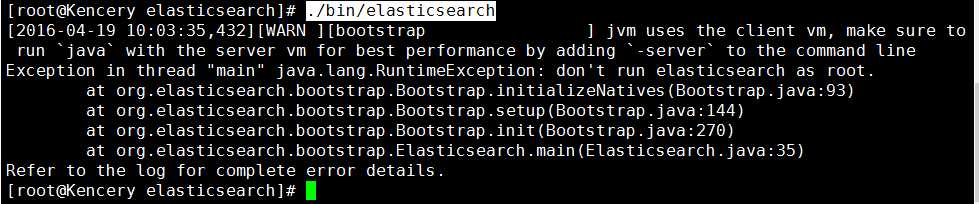
f.2 为什么会这样呢?这是因为处于系统安装考虑的设置,由于Elasticsearch可以接收用户输入的脚本并且执行,为了系统安全考虑,不允许root账号启动,所以建议给Elasticsearch单独创建一个用户来运行Elasticsearch。
f.3 创建elasticsearch用户组以及elasticsearch用户,命令如下:
groupadd elasticsearch
useradd elasticsearch(用户名) -g elasticsearch(组名) -p elasticsearch(密码)
f.4 更改Elasticsearch文件夹以及内部文件的所属用户以及组为elasticsearch,修改完成之后如图所示:
chown -R elasticsearch:elasticsearch elasticsearch

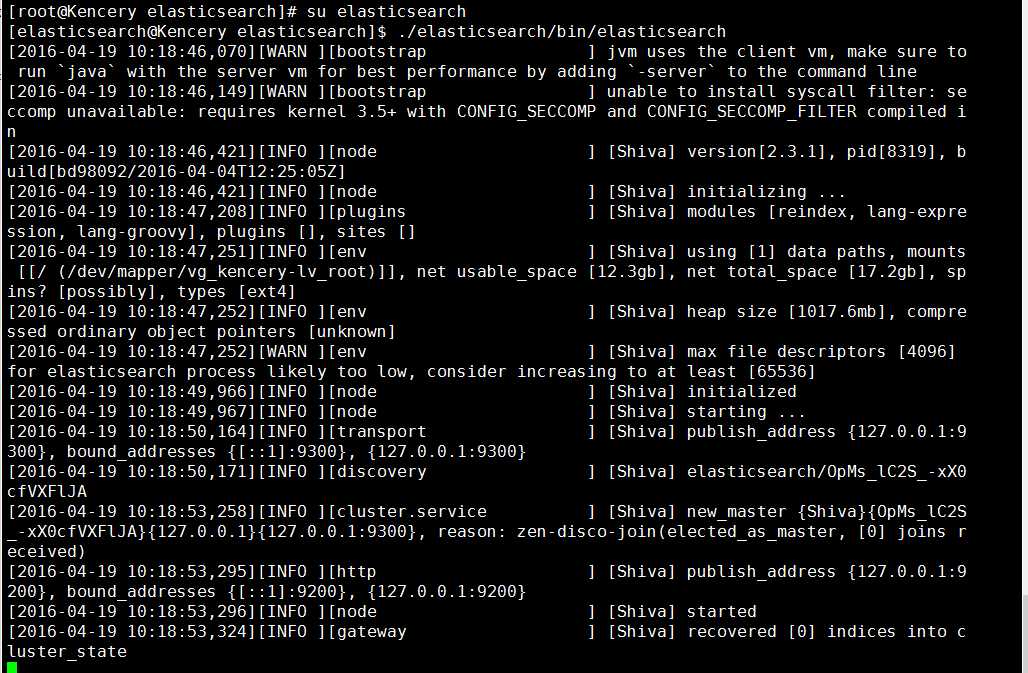
f.5 切换到elasticsearch用户下,再次执行启动命令,如图所示,则说明启动成功
g.Elasticsearch后端启动命令为:./bin/elasticsearch -d
h.安装完成后使用IP访问
h.1 当安装完成之后我们当然希望他在其他局域网内通过IP可以访问,可是执行:http://192.168.37.137:9200/,始终不能连接成功,而且centos下用localhost、127.0.0.1都能够连接成功。
h.2 这时候我们就需要修改配置文件了,首先使用ifconfig查询你的linux的IP是多少,得到IP。
h.3 跳转到Elasticsearch的config配置文件下,使用vim打开elasticsearch.yml,找到里面的"network.host",将其改为你刚才查询得到的IP,保存。
cd elasticsearch/config/
vim elasticsearch.yml
h.4 重启ElasticSearch,然后使用http://192.168.37.137:9200/访问,如果连接不成功则需要考虑是不是端口的原因,配置端口,重启防火墙即可。
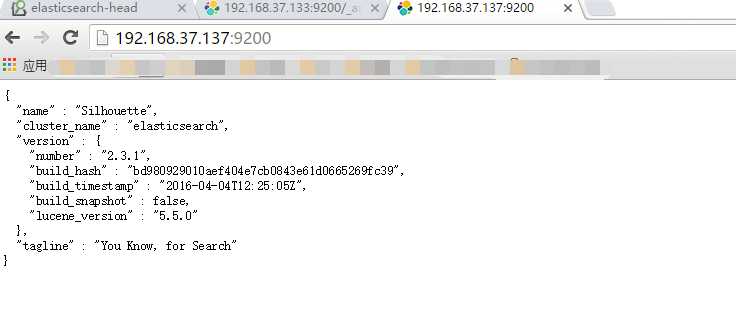
h.5 使用http://192.168.37.137:9200/访问,访问结果如图所示:,则说明ElasticSearch安装成功。‘
h.6 Elasticsearch安装完成之后,希望能有一个可视化的环境来操作它,那么下来配置:Elasticsearch Head
a.Elasticsearch Head是集群管理、数据可视化、增删改查、查询语句可视化工具,它的安装方式有两种,一种是使用命令安装,一种是下载包安装。
b.命令安装
b.1 cd /usr/local/kencery/elasticsearch/elasticsearch
b.2 ./bin/plugin -install mobz/elasticsearch-head(*)
提示错误,错误信息是:ERROR: unknown command [-install]. Use [-h] option to list available commands,这是因为Elasticsearch在2.0以上的版本将-install变成了install。
b.3 故而执行命令 ./bin/plugin install mobz/elasticsearch-head即可。
b.4 详细信息请看:https://github.com/mobz/elasticsearch-head下面的README.md文件。
c.下载包安装
c.1 在准备下载包的时候我们已经将包下载到电脑本地了,所以讲下载下来的包(elasticsearch-head-master)解压elasticsearch-head-master文件夹。
c.2 在Elasticsearch的安装的plugin下创建目录head
cd /usr/local/kencery/elasticsearch/elasticsearch/plugins/
mkdir head
c.3 跳转到head文件夹下,将刚才解压的elasticsearch-head-master文件夹下的所有文件拷贝到head目录下,如图所示:

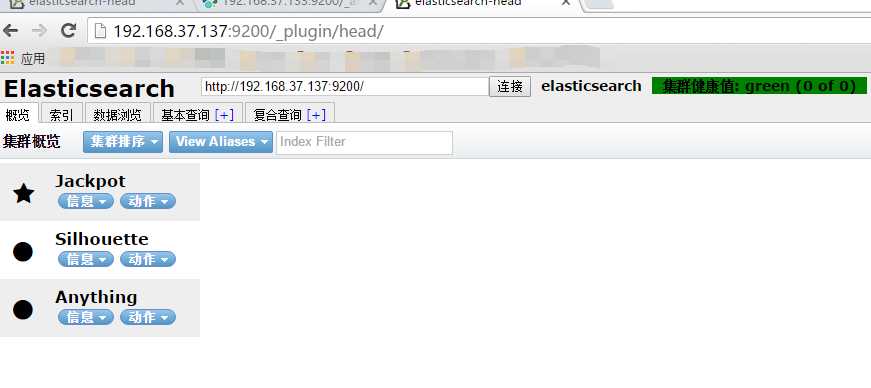
c.4 重新启动ElasticSearch,使用http://192.168.37.137:9200/_plugin/head/访问浏览器,如图所示,则说明安装成功。
d.安全问题
如图就可以看出,该插件可以对数据进行任何增删改查,所以不建议在正式环境中使用它,如果使用,也必须限制规定的IP能够使用。
a. IK Analyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包,最初的时候,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件,从3.0版本之后,IK逐渐成为面向java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化
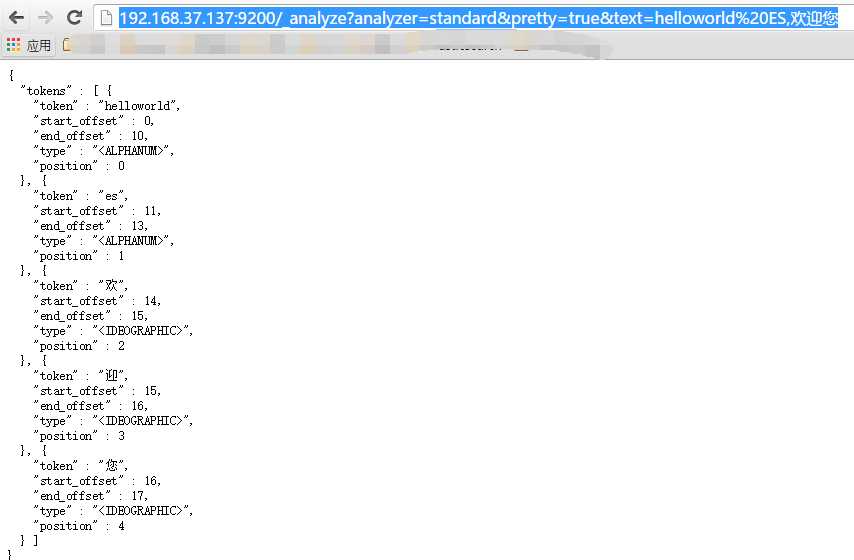
b. 当安装完Elasticsearch之后,默认已经含有一个分词法,就是standard,这个分词法对英文的支持还可以,但是对中文的支持非常差劲,如图所示:
http://192.168.37.137:9200/_analyze?analyzer=standard&pretty=true&text=helloworld,%E6%AC%A2%E8%BF%8E%E6%82%A8
c.安装IK分词法。
c.1 首先通过Git将源码下载下来,打开git客户端输入命令:git clone https://github.com/medcl/elasticsearch-analysis-ik,如果没有安装git,则直接下载zip包。
c.2 下载之后进入到下载的文件夹下,如图所示:
c.3 因为其源码使用的maven开发,故而使用maven编译项目,如果没有安装maven,参考博客安装:http://www.cnblogs.com/hanyinglong/p/5030907.html,命令提示符以管理员的身份运行,如图所示:
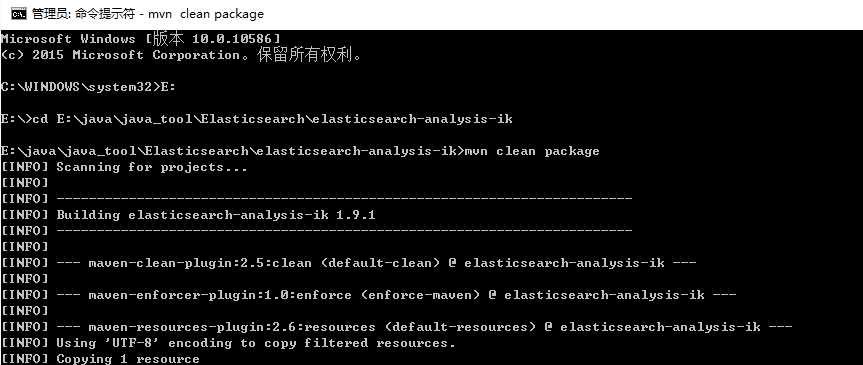
编译成功在下面会提示Succes。
c.4 打开编译后的target\releases,解压压缩包,然后进入解压的压缩包里面可以看到几个jar包和配置文件。
d.在Elasticsearch的安装的plugin下创建文件夹ik
cd /usr/local/kencery/elasticsearch/elasticsearch/plugins/
mkdir ik
e. 跳转到ik文件夹下,将c.4中所说的文件拷贝到ik文件夹下,如图所示:

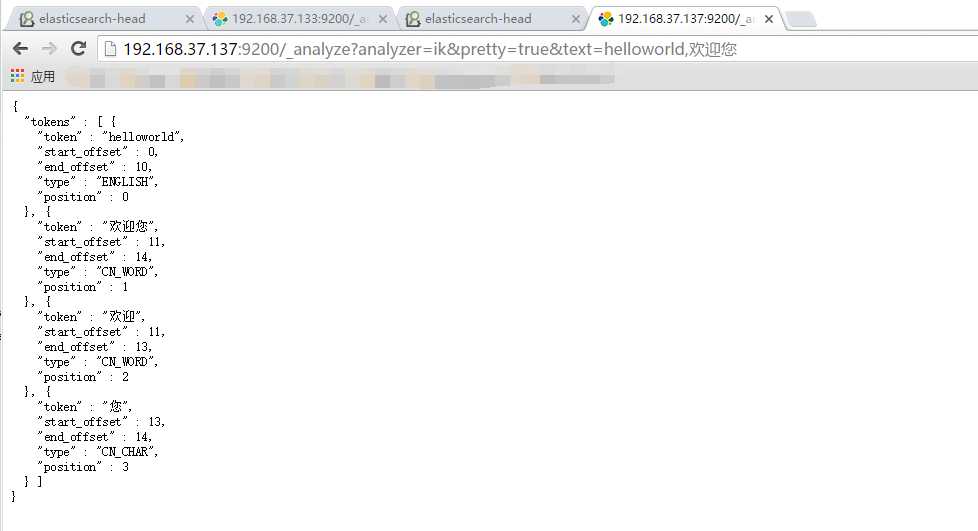
f. 重新启动ElasticSearch,使用http://192.168.37.137:9200/_analyze?analyzer=ik&pretty=true&text=helloworld,%E6%AC%A2%E8%BF%8E%E6%82%A8访问浏览器,如果分词,则说明配置成功。
每天一点点,都是进步
如果文章哪里存在问题,欢迎大家指出来,我会在第一时间修改。
Elasticsearch初步使用(安装、Head配置、分词器配置)
标签:
原文地址:http://www.cnblogs.com/hanyinglong/p/5409003.html