标签:
通过上一篇知道,预测语法分析不能处理左递归的文法(比如对stmt分析,则遇到多个以stmt开头的产生式,这使得向前看符号无法匹配一个分支,而右递归则是可以使用预测分析法处理)。
抽象语法:每个内部结点代表一个运算符,该结点的子结点表示这个运算符的分量。比如表达式 9 -5 + 2,其抽象语法树为
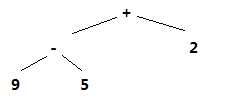
将前面介绍的使用终结符和非终结符表示的语法分析树称为具体语法树,相应的文法为具体语法。这里介绍的为抽象语法树。
考虑前文介绍的一个文法:
expr -> expr1 + term {print(‘+‘)}
expr -> expr1 - term {print(‘-‘)}
expr -> term
term -> 0 {print(‘0‘)}
term -> 1 {print(‘1‘)}
...
term -> 9 {print(‘9‘)}
这个文法包含了左递归,消除方法很简单,转为右递归即可,即产生式 A -> Aα | Aβ | γ 转换为
A -> γR
R -> αR | βR | ε
如果包含内嵌动作,则翻译方案为
expr -> term rest
rest -> + term { print(‘+‘) } rest
| - term { print(‘-‘) } rest
| ε
term -> 0 { print(‘0‘) }
| 1 { print(‘1‘) }
...
| 9 {print(‘9‘) }
注意保持语义动作的顺序,这里动作{print(‘+‘)}和{print(‘-‘)}都处于term和rest中间。
如果这个动作放在rest后面,翻译就不正确了,比如对于表达式 9 - 5 + 2,9为一个term,此时执行动作{print(‘9‘)},然后 “-” 匹配rest的第二个产生式,然后是5,这个term执行动作{print(‘5‘)},然后又是rest非终结符,此时5后面遇到“+”,匹配rest的第一个产生式,然后遇到字符 2,执行{print(‘2‘)},然后需要匹配rest,由于2后面没有字符了,故匹配rest的第三个产生式,没有任何动作,此时返回到rest的第一个产生式,然后执行rest后面的动作{print(‘+‘)},然后再返回到rest的第二个产生式,执行动作{print(‘-‘)},最终翻译结果为 952+-,显然与正确答案95-2+不一致。
用伪代码表示翻译过程,
void expr() {
term(); rest();
}
void rest() {
if (lookahead == ‘+‘) {
match(‘+‘); term(); print(‘+‘); rest();
}
else if (lookahead == ‘-‘) {
match(‘-‘); term(); print(‘-‘); rest();
}
else {}
}
void term() {
if (IsNumber(lookahead)) {
t = lookahead; match(lookahead); print(t);
}
else report ("语法错误“);
}
上面伪代码中的rest()函数中,当向前看符号为‘+‘或‘-‘时,对rest()的调用是尾递归调用,此时rest的代码可以改写为
void rest() {
while(true) {
if(lookahead == ‘+‘) {
match(‘+‘); term(); print(‘+‘); continue;
}
else if(lookahead == ‘-‘) {
match(‘-‘); term(); print(‘-‘); continue;
}
break;
}
}
完整的程序为
/* A simple translator written in C#
*/
using System;
using System.IO;
namespace CompileDemo
{
class Parser
{
static int lookahead;
public Parser()
{
lookahead = Console.Read();
}
public void expr()
{
term();
while(true)
{
if (lookahead == ‘+‘)
{
match(‘+‘);
term();
Console.Write(‘+‘);
}
else if (lookahead == ‘-‘)
{
match(‘-‘);
term();
Console.Write(‘-‘);
}
else
return;
}
}
void term()
{
if (char.IsDigit((char)lookahead))
{
Console.Write((char)lookahead);
match(lookahead);
}
else
throw new Exception("syntax error");
}
void match(int t)
{
if (lookahead == t)
lookahead = Console.Read();
else
throw new Exception("syntax error");
}
}
class Program
{
static void Main(string[] args)
{
Console.Write("please input an expression composed with numbers and operating chars...\n");
var parser = new Parser();
parser.expr();
Console.Write(‘\n‘);
}
}
}
测试结果为

假设允许表达式中出现数字、标识符和“空白”符,以扩展上一节介绍的表达式翻译器。扩展后的翻译方案如下
expr -> expr + term {print(‘+‘) }
| expr - term { print(‘-‘) }
| term
term -> term * factor { print(‘*‘) }
| term / factor { print(‘/‘) }
| factor
factor -> (expr)
| num { print (num.value) }
| id { print(id.lexeme) }
我们对终结符附上属性,如num.value,表示num的值(整数值),而id.lexeme表示终结符id的词素(字符串)。
在输入流中出现一个数位序列时,词法分析器将向语法分析器传送一个词法单元,这个词法单元包含终结符(比如num)以及根据这些数位计算得到的整形属性值,比如输入 31+28+59 被转换为
<num,31><+><num,28><+><num,59>
运算符+没有属性。实现数位序列转换为数值属性的伪代码为
if (peek holds a digit) {
v = 0;
do {
v = v*10 + integer value of digit peek;
peek = next input character;
}while(peek holds a digit);
return token<num, v>;
假设将标识符用id终结符表示,则输入如下时,count = count + increment; 语法分析器处理的是终结符序列 id = id + id; 用一个属性保存id的词素,则这个终结符序列写成元组形式为
<id,"count"><=><id,"count"><+><id,"increment"><;>
关键字可作为一种特殊的标识符,为了跟用户输入的标识符区分,通常是将关键字作为保留字,只有不与任何保留字相同的标识符才是用户标识符。区分关键字和标识符的伪代码如下
假设使用类Hashtable将一个字符串表实现为一个散列表。
if(peek holds a alphebet) {
while (IsAlphaOrDigit(c = IO.Read()))
buffer.Add(c); // read a character into buffer
string s = buffer.ToString();
w =words.get(s);
if(w != null) return w; // reserved word or cached user id
else {
words.Add(s, <id, s>);
return <id, s>;
}
}
这段代码中,保留字是最开始的时候初始化到words中,以后每次读取到新的用户输入标识符,则进行缓存。
完整的代码如下
/* A lexer written in C#
*/
class Lexer
{
public int line = 1;
private char peek = ‘ ‘;
private Hashtable words = new Hashtable();
void reserve(Word w)
{
words.Add(w.lexeme, w);
}
public Lexer()
{
reserve(new Word(Tag.TRUE, "true"));
reserve(new Word(Tag.FALSE, "false"));
}
public Token Scan()
{
for(;;peek = (char)Console.Read())
{
if (peek == ‘ ‘ || peek == ‘\t‘)
continue;
else if (peek == ‘\n‘)
line++;
else
break;
}
if(char.IsDigit(peek))
{
int v = 0;
do
{
v = 10 * v + peek - ‘1‘ + 1;
peek = (char)Console.Read();
} while (char.IsDigit(peek));
return new Num(v);
}
if(char.IsLetter(peek))
{
StringBuilder sb = new StringBuilder();
do
{
sb.Append(peek);
peek = (char)Console.Read();
} while (char.IsLetterOrDigit(peek));
string s = sb.ToString();
Word w = null;
if (words.Contains(s))
w = (Word)words[s];
if (w != null) // reserved word or cached ID
return w;
w = new Word(Tag.ID, s);
words.Add(s, w);
return w;
}
Token t = new Token(peek);
peek = ‘ ‘;
return t;
}
}
class Token
{
public readonly int tag;
public Token(int t)
{
tag = t;
}
}
class Tag
{
public readonly static int NUM = 256, ID = 257, TRUE = 258, FALSE = 259;
}
class Num : Token
{
public readonly int value;
public Num(int v) : base(Tag.NUM)
{
value = v;
}
}
class Word : Token
{
public readonly string lexeme;
public Word(int t, string s) : base(t)
{
lexeme = s;
}
}
每个块有自己的符号表。对一个嵌套的块,外层块不能访问内层块的符号表。
比如声明代码片段:
(global var) int w;
...
int x; int y; // block 1
int w; bool y; int z; // block 2
...w, y, z, x...
w, x, y...
则符号表链为
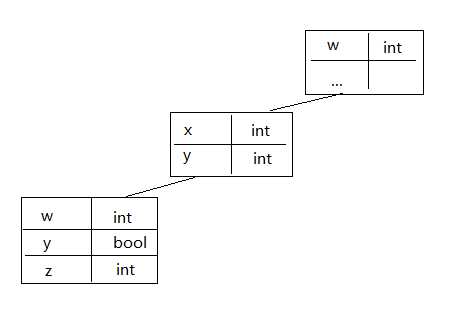
我们用一个类Env表示语句块的环境,其中有一个成员prev指向这个块的直接外层块的Env环境,并且提供了从当前块的环境中添加符号到符号表的方法,以及从当前符号表向外层块的符号表遍历直到找到字符串对应的符号。
class Env
{
private Hashtable table;
protected Env prev;
public Env(Env p)
{
table = new Hashtable();
prev = p;
}
public void Put(string s, Symbol symbol)
{
table.Add(s, symbol);
}
public Symbol Get(string s)
{
// traverse from inner to outer
for(Env e = this; e!= null; e=e.prev)
{
if (e.table.Contains(s))
return (Symbol)(e.table[s]);
}
return null;
}
}
class Symbol
{
public string type { get; set; }
}
那这个Env类如何使用呢?
program -> {top = null;}
block
block -> ‘{‘ {saved = top;
top = new Env(top);
print("{"); }
decls stmts ‘}‘ {top = saved;
print("}"); }
decls -> decls decl
| ε
decl -> type id; {s = new Symbol();
s.type = type.lexeme;
top.Put(id.lexeme, s);}
stmts -> stmts stmt
| ε
stmt -> block
| factor; { print(";");}
factor -> id { s = top.Get(id.lexeme);
print(id.lexeme);
print(":");
print(s.type); }
这个翻译方案,在进入和离开块时分别创建和释放符号表。变量top表示一个符号表链的最顶层符号表。
前面介绍了抽象语法树,即由运算符作为结点,其子结点为这个运算符的分量。比如 9 - 5。再比如一个while语句
while (expr) stmt
其中while为一个运算符,看作一个结点,其两个子结点为表达式expr和语句stmt。
可以让所有非终结符都有一个属性n,作为语法树的一个结点,将结点实现为Node类对象。对Node类可以有两个直接子类,Expr和Stmt,分别表示表达式和语句。于是,while构造的伪代码如下
new while(x, y)
考虑如下的伪代码,用于表达式和语句的抽象语法树构造
program -> block {return block.n}
block -> ‘{‘ stmts ‘}‘ {return block.n = stmts.n;}
stmts -> stmts1 stmt {stmts.n = new Seq(stmts1.n, stmt.n);}
| ε { stmts.n = null; }
stmt -> expr; {stmt.n = new Eval(expr.n);}
| if(expr) stmt1 {stmt.n = new If(expr.n, stmt1.n);}
| while(expr)stmt1 {stmt.n = new While(expr.n, stmt1.n;}
| do stmt1 while(expr);
{stmt.n = new Do(stmt1.n, expr.n);}
| block {stmt.n = block.n}
expr -> rel = expr1 {expr.n = new Assign(‘=‘, rel.n, expr1.n);} // right associative
| rel { expr.n = rel.n;}
rel -> rel1 < add { expr.n = new Rel(‘<‘, rel1.n, add.n);}
| rel1 <= add { expr.n = new Rel(‘≤‘, rel1.n, add.n);}
| add {rel.n = add.n;}
add -> add1 + term {add.n = new Op(‘+‘, add1.n, term.n);}
| term { add.n = term.n;}
term -> term1*factor {term.n = new Op(‘*‘, term1.n, factor.n);}
| factor {term.n = factor.n;}
factor -> (expr) { factor.n = expr.n;}
| num { factor.n = new Num(num.value);}
赋值表达式的左部和右部含义不一样,如 i = i + 1; 表达式左部是用来存放该值的存储位置,右部描述了一个整数值。静态检查要求赋值表达式左部是一个左值(存储位置)。
类型检查,比如
if(expr) stmt
期望表达式expr是boolean型。
又比如对关系运算符rel(例如<)来说,其两个运算分量必须具有相同类型,且rel运算结果为boolean型。用属性type表示表达式的类型,rel的运算分量为E1和E2,rel关系表达式为E,那么类型检查的代码如下
if(E1.type == E2.type) E.type = boolean;
else error;
对语句 if expr then stmt1 的翻译,
对 exrp求值并保存到x中
if False x goto after
stmt1的代码
after: ...
下面给出类If的伪代码,类If继承Stmt类,Stmt类中有一个gen函数用于生成三地址代码。
class If : Stmt
{
Expr E; Stmt S;
public If(Expr x, Stmt y)
{
E = x; S = y; after = newlabel();
}
public void gen()
{
Expr n = E.rvalue(); // calculate right value of expression E
emit("ifFalse " + n.ToString() + " goto " + after);
S.gen();
emit(after + ":");
}
}
If类中,E, S分别表示if语句的表达式expr以及语句stmt。在源程序的整个抽象语法树构建完毕时,函数gen在此抽象语法树的根结点处被调用。
我们采用一种简单的方法翻译表达式,为一个表达式的语法树种每个运算符结点都生成一个三地址指令,不需要为标识符和常量生成代码,而将它们作为地址出现在指令中。
一个结点x的类为Expr,其运算符为op,并将运算结果值存放在由编译器生成的临时名字(如t)中。故 i - j + k被翻译成
t1 = i - j
t2 = t1 + k
对包含数组访问的情况如 2* a[i],翻译为
t1 = a [i]
t2 = 2 * t1
前面介绍了函数rvalue,用于获取一个表达式的右值,此外用于获取左值的函数为lvalue,它们的伪代码如下
Expr lvalue(x: Expr)
{
if(x is a Id node) return x;
else if(x is a Access(y,z) node, and y is a Id node)
{
return new Access(y, rvalue(z));
}
else error;
}
从代码中看出,如果x是一个标识符结点,则直接返回x,如果x是一个数组访问,比如a[i],x结点则形如Access(y,z),其中Access是Expr的子类,y为被访问的数组名,z表示索引。左值函数比较简单不再赘述。
下面来看右值函数伪代码:
Expr rvalue(x: Expr)
{
if(x is a Id or Constant node)
return x;
else if (x is a Op(op, y, z) or Rel(op, y, z) node)
{
t = temperary name;
generate instruction strings of t = rvalue(y) op rvalue(z);
return a new node of t;
}
else if(x is a Access(y,z) node)
{
t = temperary name;
call lvalue(x), and return a Access(y, z‘) node;
generate instruction strings of Access(y, z‘);
return a new node of t;
}
else if (x is a Assign(y, z) node)
{
z‘ = rvalue(z);
generate instruction strings of lvalue(y) = z‘
return z‘;
}
}
分析,x的右值由以下一种情况的返回值确定:
1)如果表达式x是一个标识符或者一个常量,则直接返回x,如 5,则返回5, a, 则返回a;
2)如果表达式x是一个Op运算符(+、-、*、/等)或者Rel运算符(<, >, ==, <=, >=, !=等),则创建一个临时名字t,并对两个运算分量y,z分别求右值,然后用op运算符计算,将运算结果赋给t,返回t;
3)如果表达式x是一个数组访问,则创建一个临时名字t,对数组访问表达式x求其左值返回一个Access(y,z‘)结点,求x左值,是因为x是Access(y, z),而z是一个表达式,需要对z求右值,然后临时名字t被赋予整个数组访问的右值,返回t;
4)如果表达式x是一个赋值运算,则对z求右值得到z‘,对y求左值,并被赋予z‘值,最后返回z’。
例子:
a[i] = 2*a[j-k]
对这个表达式使用rvalue函数,将生成
t3 = j - k
t2 = a[t3]
t1 = 2*t2
a[i] = t1
注:
本系列文章完全参考编译原理龙书教材。
标签:
原文地址:http://www.cnblogs.com/sjjsxl/p/5403281.html