标签:
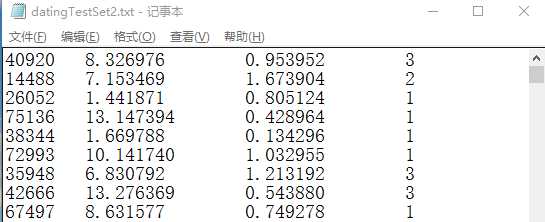
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # ==========================# 读入文本记录,转换为NumPy,便于其他函数使用# 输入:文本记录的路径# ==========================def file2matrix(filename): fr = open(filename) arrayOLines = fr.readlines() numberOfLines = len(arrayOLines) returnMat = zeros((numberOfLines, 3)) classLabelVector = [] index = 0 for line in arrayOLines: line = line.strip() # 删除字符串首尾的空白符(包括'\n', '\r', '\t', ' ') listFromLines = line.split("\t") returnMat[index, :] = listFromLines[0:3] classLabelVector.append(int(listFromLines[-1])) index += 1 return returnMat, classLabelVector |
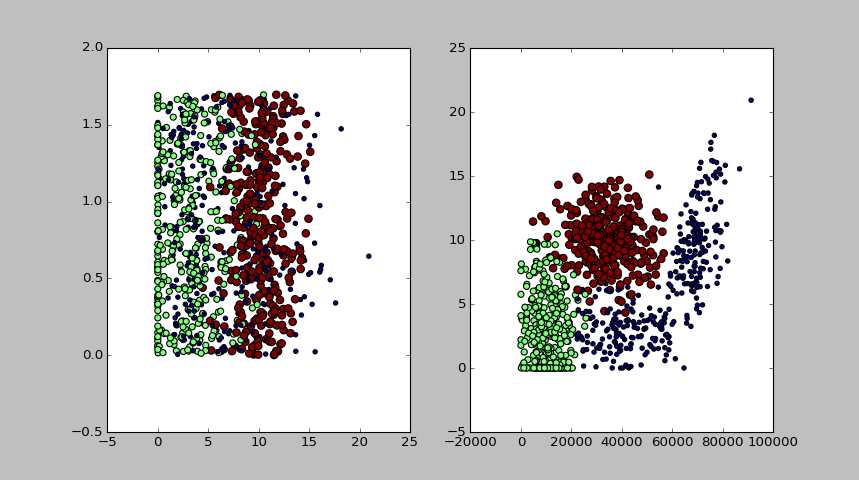
1 2 3 4 5 6 7 8 9 10 | def plotSca(datingDataMat, datingLabels): import matplotlib.pyplot as plt fig = plt.figure() ax1 = fig.add_subplot(121) # 玩网游所消耗的时间比(横轴)与每年消耗的冰淇淋公升数(纵轴)的散点图 ax1.scatter(datingDataMat[:,1], datingDataMat[:, 2], 15.0*array(datingLabels), 5.0*array(datingLabels)) ax2 = fig.add_subplot(122) # 每年获得的飞行常客里程数(横轴)与 玩网游所消耗的时间比(纵轴)的散点图 ax2.scatter(datingDataMat[:,0], datingDataMat[:, 1], 15.0*array(datingLabels), 5.0*array(datingLabels)) plt.show() |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # =====================================# 如果不同特征值量级相差太大,# 而他们在模型中占的权重又并不比其他特征大,# 这个时候就需要对特征值进行归一化,# 也就是将取值范围处理为0到1或者-1到1之间# 本函数就是对数据集归一化特征值# dataset: 输入数据集# =====================================def autoNorm(dataset): minVals = dataset.min(0) maxVals = dataset.max(0) ranges = maxVals - minVals normDataset = zeros(shape(dataset)) m = dataset.shape[0] normDataset = dataset - tile(minVals, (m, 1)) normDataset = normDataset/tile(ranges, (m, 1)) # 矩阵中对应数值相除 return normDataset, ranges, minVals |
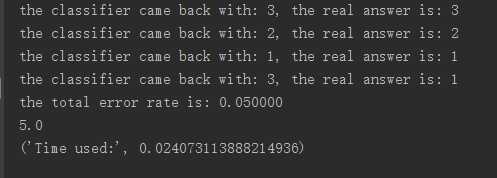
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | '''分类器针对约会网站的测试代码'''def datingClassTest(): hoRatio = 0.10 # 数据集中用于测试的比例 filePath = "E:\ml\machinelearninginaction\Ch02\datingTestSet2.txt" datingDataMat, datingLabels = file2matrix(filePath) # plotSca(datingDataMat, datingLabels) normMat, ranges, minVals = autoNorm(datingDataMat) m = normMat.shape[0] numTestVecs = int(hoRatio*m) errcounter = 0.0 for i in range(numTestVecs): classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3) print "the classifier came back with: %d, the real answer is: %d" % \ (classifierResult, datingLabels[i]) if (classifierResult !=datingLabels[i]): errcounter +=1.0 print "the total error rate is: %f" % (errcounter/float(numTestVecs)) print errcounter |
标签:
原文地址:http://www.cnblogs.com/mooba/p/5412592.html