标签:
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
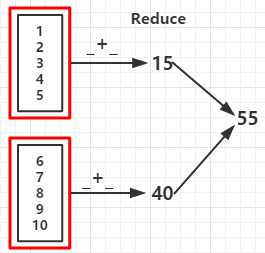
val rdd = sc.parallelize(1 to 10,2)
val reduceRDD = rdd.reduce(_ + _)
val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53
val countRDD = rdd.count()
val firstRDD = rdd.first()
val takeRDD = rdd.take(5) //输出前个元素
val topRDD = rdd.top(3) //从高到底输出前三个元素
val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素
println("func +: "+reduceRDD)
println("func -: "+reduceRDD1)
println("count: "+countRDD)
println("first: "+firstRDD)
println("take:")
takeRDD.foreach(x => print(x +" "))
println("\ntop:")
topRDD.foreach(x => print(x +" "))
println("\ntakeOrdered:")
takeOrderedRDD.foreach(x => print(x +" "))
sc.stop
}
func +: 55 func -: 15 //如果分区数据为1结果为 -53 count: 10 first: 1 take: 1 2 3 4 5 top: 10 9 8 takeOrdered: 1 2 3

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("KVFunc")
val sc = new SparkContext(conf)
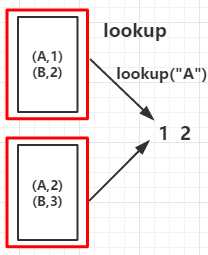
val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))
val rdd = sc.parallelize(arr,2)
val countByKeyRDD = rdd.countByKey()
val collectAsMapRDD = rdd.collectAsMap()
println("countByKey:")
countByKeyRDD.foreach(print)
println("\ncollectAsMap:")
collectAsMapRDD.foreach(print)
sc.stop
}
countByKey: (B,2)(A,2) collectAsMap: (A,2)(B,3)

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
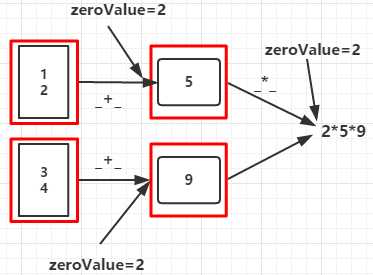
val rdd = sc.parallelize(List(1,2,3,4),2)
val aggregateRDD = rdd.aggregate(2)(_+_,_ * _)
println(aggregateRDD)
sc.stop
}
90

def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local").setAppName("Fold")
val sc = new SparkContext(conf)
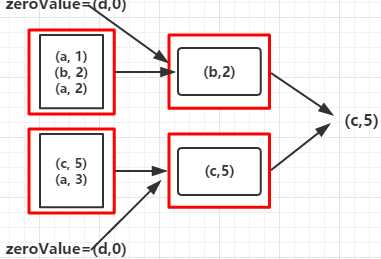
val rdd = sc.parallelize(Array(("a", 1), ("b", 2), ("a", 2), ("c", 5), ("a", 3)), 2)
val foldRDD = rdd.fold(("d", 0))((val1, val2) => { if (val1._2 >= val2._2) val1 else val2
})
println(foldRDD)
}
c,5

标签:
原文地址:http://www.cnblogs.com/MOBIN/p/5414490.html