标签:
文件是 MapReduce 任务数据的初始存储地。正常情况下,输入文件一般是存储在 HDFS 里面。这些文件的格式可以是任意的:我们可以使用基于行的日志文件, 也可以使用二进制格式,多行输入记录或者其它一些格式。这些文件一般会很大,达到数十GB,甚至更大。那么 MapReduce 是如何读取这些数据的呢?下面我们来学习 InputFormat 接口
1、InputFormat接口
InputFormat接口决定了输入文件如何被 Hadoop分块(split up)与接受。InputFormat 能够从一个 job 中得到一个 split 集合(InputSplit[]),然后再为这个 split 集合配上一个合适的 RecordReader(getRecordReader)来读取每个split中的数据。 下面我们来看一下 InputFormat 接口由哪些抽象方法组成
2、InputFormat的抽象类方法
InputFormat 包含两个抽象方法,如下所示
1 public abstract class InputFormat< K, V> {
2
3 public abstract List<InputSplit> getSplits(JobContext context) throws IOException,InterruptedException;
4
5 public abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context) throws IOException,InterruptedException;
7 }
1)getSplits(JobContext context) 方 法负责将一个大数据逻辑分成许多片。比如数据库表有 100 条数据,按照主键ID升序存储。 假设每20条分成一片,这个List的大小就是5,然后每个InputSplit记录两个参数,第一个为这个分片的起始 ID,第二个为这个分片数据的大小,这里是20.很明显 InputSplit 并没有真正存储数据。只是提供了一个如何将数据分片的方法。
2)createRecordReader(InputSplit split,TaskAttemptContext context)方 法根据 InputSplit 定义的方法,返回一个能够读取分片记录的 RecordReader。getSplit 用来获取由输入文件计算出来的 InputSplit, 后面会看到计算 InputSplit 时,会考虑输入文件是否可分割、文件存储时分块的大小和文件大小等因素;而createRecordReader() 提供了前面说的 RecordReader 的实现, 将Key-Value 对从 InputSplit 中正确读出来,比如LineRecordReader,它是以偏移值为Key,每行的数据为 Value,这使所有 createRecordReader() 返回 LineRecordReader 的 InputFormat 都是以偏移值为Key,每行数据为 Value 的形式读取输入分片的。
其实很多时候并不需要我们实现 InputFormat 来读取数据,Hadoop 自带有很多数据输入格式,已经实现了 InputFormat接口
3、InputFormat接口实现类
InputFormat 接口实现类有很多,其层次结构如下图所示
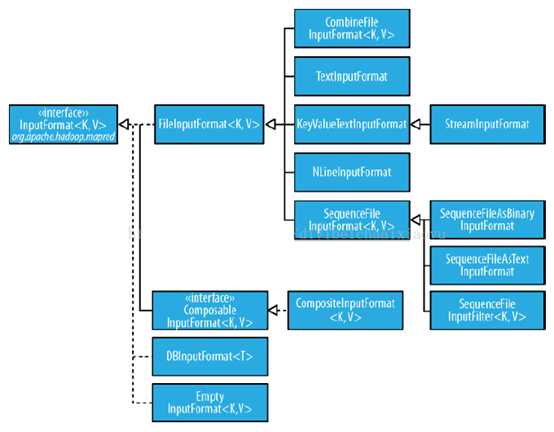
1、FileInputFormat
FileInputFormat是所有使用文件作为其数据源的 InputFormat 实现的基类,它的主要作用是指出作业的输入文件位置。因为作业的输入被设定为一组路径, 这对指定作业输入提供了很强的灵活性。FileInputFormat 提供了四种静态方法来设定 Job 的输入路径:

1 public static void addInputPath(Job job,Path path);
2
3 public static void addInputPaths(Job job,String commaSeparatedPaths);
4
5 public static void setInputPaths(Job job,Path... inputPaths);
6
7 public static void setInputPaths(Job job,String commaSeparatedPaths);
addInputPath()、addInputPaths()方法可以将一 个或多个路径加入路径列表,可以分别调用这两种方法来建立路径列表;setInputPaths()方法一次设定完整的路径列表,替换前面调用中在 Job 上所设置的所有路径。它们具体的使用方法,看如下示例
1 // 设置一个源路径
2 FileInputFormat.addInputPath(job, new Path("hdfs://ljc:9000/buaa/inputPath1"));
3
4 // 设置多个源路径,多个源路径之间用逗号分开
5 FileInputFormat.addInputPaths(job, " hdfs://ljc:9000/buaa/inputPath1, hdfs://ljc:9000/buaa/inputPath2,...");
6
7 // inputPaths是一个Path类型的数组,可以包含多个源路径,比如hdfs://ljc:9000/buaa/inputPath1,hdfs://ljc:9000/buaa/inputPath2,等
8 FileInputFormat.setInputPaths(job, inputPaths);
9
10 // 设置多个源路径,多个源路径之间用逗号分开
11 FileInputFormat.setInputPaths(job, " hdfs://ljc:9000/buaa/inputPath1, hdfs://ljc:9000/buaa/inputPath2,...");
add 方法、set 方法允许指定包含的文件。如果需要排除特定文件,可以使用 FileInputFormat 的 setInputPathFilter()方法设置一个过滤器
1 public static void setInputPathFilter(Job job,Class<? extends PathFilter filter);
关于过滤器,这里不再深入讨论。即使不设置过滤 器,FileInputFormat 也会使用一个默认的过滤器来排除隐藏文件。 如果通过调用 setInputPathFilter()设置了过滤器,它会在默认过滤器的基础上进行过滤。换句话说,自定义的过滤器只能看到非隐藏文件
对于输入的数据源是文件类型的情况下,Hadoop 不仅擅长处理非结构化文本数据,而且可以处理二进制格式的数据, 但它们的基类都是FileInputFormat。下面我们介绍的几种常用输入格式,都实现了FileInputFormat基类
1、TextInputFormat
TextInputFormat 是默认的 InputFormat。每条记录是一行输入。键是LongWritable 类型,存储该行在整个文件中的字节偏移量。 值是这行的内容,不包括任何行终止符(换行符、回车符),它被打包成一个 Text 对象。
比如,一个分片包含了如下5条文本记录,记录之间使用tab(水平制表符)分割
1 22
2 17
3 17
4 11
5 11
每条记录表示为以下键/值对:
(0, 1 22)
(5, 2 17)
(10,3 17)
(15,4 11)
(20,5 11)
很明显,键并不是行号。一般情况下,很难取得行号,因为文件按字节而不是按行切分为分片。
2、KeyValueTextInputFormat
每一行均为一条记录, 被分隔符(缺省是tab(\t))分割为key(Text),value(Text)。可以通过 mapreduce.input.keyvaluelinerecordreader.key.value,separator属性(或者旧版本 API 中的 key.value.separator.in.input.line)来设定分隔符。 它的默认值是一个制表符。
比如,一个分片包含了如下5条文本记录,记录之间使用tab(水平制表符)分割。
1 22
2 17
3 17
4 11
5 11
每条记录表示为以下键/值对:
(1,22)
(2,17)
(3,17)
(4,11)
(5,11)
此时的键是每行排在制表符之前的 Text 序列。
3、NLineInputFormat
通过 TextInputFormat 和 KeyValueTextInputFormat,每个 Mapper 收到的输入行数不同。行数取决于输入分片的大小和行的长度。 如果希望 Mapper 收到固定行数的输入,需要将 NLineInputFormat 作为 InputFormat。与 TextInputFormat 一样, 键是文件中行的字节偏移量,值是行本身。N 是每个 Mapper 收到的输入行数。N 设置为1(默认值)时,每个 Mapper 正好收到一行输入。 mapreduce.input.lineinputformat.linespermap 属性(在旧版本 API 中的 mapred.line.input.format.linespermap 属性)实现 N 值的设定。
以下是一个示例,仍然以上面的4行输入为例。
1 22
2 17
3 17
4 11
5 11
例如,如果 N 是3,则每个输入分片包含三行。一个 mapper 收到三行键值对:
1 22
2 17
3 17
另一个 mapper 则收到后两行(因为总共才5行,所有另一个mapper只能收到两行)
4 11
5 11
这里的键和值与 TextInputFormat 生成的一样。
4、SequenceFileInputFormat
用于读取 sequence file。键和值由用户定义。序列文件为 Hadoop专用的压缩二进制文件格式。它专用于一个 MapReduce作业和其它 MapReduce作业之间的传送数据(适用与多个 MapReduce 链接操作)。
2、多个输入
虽然一个 MapReduce 作业的输入可以包含多个输入文件,但所有文件都由同一个 InputFormat 和 同一个 Mapper 来解释。 然而,数据格式往往会随时间演变,所以必须写自己的 Mapper 来处理应用中的遗留数据格式问题。或者,有些数据源会提供相同的数据, 但是格式不同。
这些问题可以使用 MultipleInputs 类来妥善处理,它允许为每条输入路径指定 InputFormat 和 Mapper。例如,我们想把英国 Met Office 的气象站数据和 NCDC 的气象站数据放在一起来统计平均气温,则可以按照下面的方式来设置输入路径。
1 MultipleInputs.addInputPath(job,ncdcInputPath,TextInputFormat.class,NCDCTemperatureMapper.class);
2
3 MultipleInputs.addInputPath(job,metofficeInputPath,TextInputFormat.class,MetofficeTemperatureMapper.class);
这段代码取代了对 FileInputFormat.addInputPath()和job.setMapperClass() 的常规调用。Met Office 和 NCDC 的数据都是文本文件,所以对两者都使用 TextInputFormat 数据类型。 但这两个数据源的行格式不同,所以我们使用了两个不一样的 Mapper,分别为NCDCTemperatureMapper和MetofficeTemperatureMapper。重要的是两个 Mapper 的输出类型一样,因此,reducer 看到的是聚集后的 map 输出,并不知道这些输入是由不同的 Mapper 产生的。
MultipleInputs 类还有一个重载版本的 addInputPath() 方法,它没有 Mapper参数。如果有多种输入格式而只有一个 Mapper(通过 Job 的 setMapperClass()方法设定),这种方法很有用。其具体方法如下所示。
1 public static void addInputPath(Job job,Path path,class< ? extends InputFormat> inputFormatClass);
3、DBInputFormat
这 种输入格式用于使用 JDBC 从关系数据库中读取数据。因为它没有任何共享能力,所以在访问数据库的时候必须非常小心,在数据库中运行太多的 mapper 读数据可能会使数据库受不了。 正是由于这个原因,DBInputFormat 最好用于加载少量的数据集。与之相对应的输出格式是DBOutputFormat,它适用于将作业输出数据(中等规模的数据)转存到数据库
4、自定义 InputFormat
有时候 Hadoop 自带的输入格式,并不能完全满足业务的需求,所以需要我们根据实际情况自定义 InputFormat 类。而数据源一般都是文件数据,那么自定义 InputFormat时继承 FileInputFormat 类会更为方便,从而不必考虑如何分片等复杂操作。 自定义输入格式我们分为以下几步:
1、继承 FileInputFormat 基类。
2、重写 FileInputFormat 里面的 isSplitable() 方法。
3、重写 FileInputFormat 里面的 createRecordReader()方法。
按照上述步骤如何自定义输入格式呢?下面我们通过一个示例加强理解。
我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩。 样本数据如下所示,每行数据的数据格式为:学号、姓名、语文成绩、数学成绩、英语成绩、物理成绩、化学成绩
19020090040 秦心芯 123 131 100 95 100
19020090006 李磊 99 92 100 90 100
。。。。。
下面我们就编写程序,实现自定义输入并求出每个学生的总成绩和平均成绩。分为以下几个步骤,这里只给出步骤,代码见下
第一步:为了便于每个学生学习成绩的计算,这里我们需要自定义一个 ScoreWritable类实现 WritableComparable 接口,将学生各门成绩封装起来
第二步:自定义输入格式 ScoreInputFormat类,首先继承 FileInputFormat,然后分别重写 isSplitable() 方法和 createRecordReader() 方法。 需要注意的是,重写createRecordReader()方法,其实也就是重写其返回的对象ScoreRecordReader。 ScoreRecordReader 类继承 RecordReader,实现数据的读取
第三步:编写 MapReduce 程序,统计学生总成绩和平均成绩。需要注意的是,上面我们自定义的输入格式ScoreInputFormat,需要在 MapReduce 程序中做如下设置,job.setInputFormatClass(ScoreInputFormat.class);//设置自定义输入格式
一般情况下,并不需要我们自定义输入格式,Hadoop 自带有很多种输入格式,基本满足我们工作的需要
标签:
原文地址:http://www.cnblogs.com/hyl8218/p/5422947.html