标签:
MapReduce主要包括两个阶段:一个是Map,一个是Reduce. 每一步都有key-value对作为输入和输出。
Map阶段的key-value对的格式是由输入的格式决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对文件的起始位置,value就是此行的字符文本。Map阶段的输出的key-value对的格式必须同reduce阶段的输入key-value对的格式相对应。
下面开始尝试,假设我们需要处理一批有关天气的数据,其格式如下:
按照ASCII码存储,每行一条记录
每一行字符从0开始计数,第15个到第18个字符为年
第25个到第29个字符为温度,其中第25位是符号+/-
Text文本样例:
0067011990999991950051507+0000+ 0043011990999991950051512+0022+ 0043011990999991950051518-0011+ 0043012650999991949032412+0111+ 0043012650999991949032418+0078+ 0067011990999991937051507+0001+ 0043011990999991937051512-0002+ 0043011990999991945051518+0001+ 0043012650999991945032412+0002+ 0043012650999991945032418+0078+
上代码啦:
package Hadoop; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.StringTokenizer; /** * Created by root on 4/23/16. */ public class hadoopTest extends Configured implements Tool{ //map将输入中的value复制到输出数据的key上,并直接输出 public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
//实现map函数 @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String year = line.substring(15, 19); int airTemperature; if (line.charAt(25) == ‘+‘) { airTemperature = Integer.parseInt(line.substring(26, 30)); } else { airTemperature = Integer.parseInt(line.substring(25, 30)); } context.write(new Text(year), new IntWritable(airTemperature)); } }
//reduce将输入中的key复制到输出数据的key上,并直接输出 public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; for (IntWritable sorce : values) { maxValue = Math.max(maxValue, sorce.get()); } context.write(key, new IntWritable(maxValue)); } } @Override public int run(String[] arg0) throws Exception {
//这里测试用,传入的路径直接赋值 String InputParths = "/usr/local/hadooptext.txt"; String OutputPath = "/usr/local/hadoopOut";
//声明一个job对象,这里的getConf是获取hadoop的配置信息,需要继承Configured. Job job = new Job(getConf());
//设置job名称 job.setJobName("AvgSorce");
//设置mapper输出的key-value对的格式 job.setOutputKeyClass(Text.class);
//设置Mapper,默认为IdentityMapper,这里设置的代码中的Mapper job.setMapperClass(hadoopTest.Map.class);
//Combiner可以理解为小的Reducer,为了降低网络传输负载和后续Reducer的计算压力 可以单独写一个方法进行调用 job.setCombinerClass(Reduce.class);
//设置reduce输出的key-value对的格式
job.setOutputValueClass(IntWritable.class);
//设置输入格式 job.setInputFormatClass(TextInputFormat.class);
//设置输入输出目录 FileInputFormat.setInputPaths(job, new Path(InputParths)); FileOutputFormat.setOutputPath(job, new Path(OutputPath)); boolean success = job.waitForCompletion(true); return success ? 0 : 1; } public static void main(String[] args) throws Exception { int ret = ToolRunner.run(new hadoopTest(), args); System.exit(ret); } }
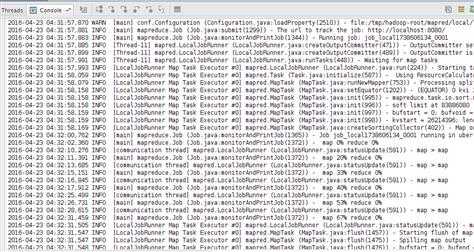
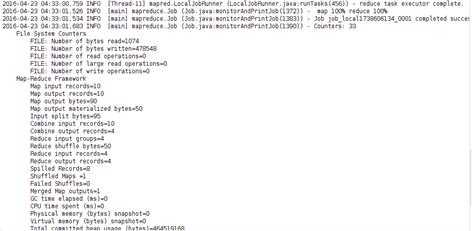
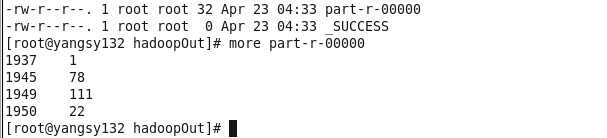
执行结果:
标签:
原文地址:http://www.cnblogs.com/yangsy0915/p/5425368.html