标签:
除了精确推理之外,我们还有非精确推理的手段来对概率图单个变量的分布进行求解。在很多情况下,概率图无法简化成团树,或者简化成团树后单个团中随机变量数目较多,会导致团树标定的效率低下。以图像分割为例,如果每个像素的label都是随机变量,则图中会有30W个随机变量(30W像素的小型相机)。且这30W个随机变量相互之间耦合严重(4邻接,多回环),采用团树算法无法高效的获得单个像素label的可能值。所以,在精确推理之外,我们使用非精确推理的手段对节点的概率分布进行估计。
BP是精确推理中的概念,我们从root向leaf发射一次MESSAGE,再接受一次MESSAGE则可完成团树的标定,这个过程称为置信传播。但是在多回环的团树,BP非常难执行,由于环的存在会导致某个节点一直无法出于可发射MESSAGE的状态(此时的团树不叫团树,应该称为“聚类图”)。然而理论证明,如果我们预先给定一套消息传递的顺序,保证节点i -> j 传播且仅传播一次消息,那么消息最终会收敛到某个定值。一旦消息收敛到某个定值,则代表节点之间就某变量达成一致,我们获得概率图可行的分布。此时对聚类图中的变量进行边缘化,即可获得有效的单变量分布。
Loopy置信传播有3项极其重要的工作:
1、保证节点之间仅传播一次的传播顺序(此顺序显然不是唯一的)
2、获取每次传播后更新的消息
3、判断消息最终收敛

1 List = []; 2 edges_ = P.edges; 3 for i = 1:length(P.clusterList) 4 j = find(edges_(i,:),8); 5 List = [List; j‘ linspace(i,i,length(j))‘]; 6 end 7 length_list = length(List); 8 array_ = mod(m,length_list)+1; 9 ij = List(array_,:); 10 i = ij(1); 11 j = ij(2);
1 length_c = length(P.clusterList); 2 for m = 1:length_c 3 if m ~= j&&P.edges(m,i)==1 4 Belief(i) = FactorProduct(Belief(i), lastMESSAGES(m, i)); 5 end 6 end 7 Belief(i).val = Belief(i).val/sum(Belief(i).val); 8 MESSAGES(i,j) = FactorMarginalization(Belief(i),setdiff(Belief(i).var,... 9 MESSAGES(i,j).var)); 10 MESSAGES(i,j).val = MESSAGES(i,j).val/sum(MESSAGES(i,j).val);
1 converged = true; 2 thresh = 1.0e-6; 3 %converged should be 1 if converged, 0 otherwise. 4 5 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 6 % YOUR CODE HERE 7 % 8 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 9 [a_,b_] = size(mNew); 10 length_m = a_*b_; 11 m_New_array = reshape(mNew,length_m,1); 12 m_Old_array = reshape(mOld,length_m,1); 13 for i = 1:length_m 14 diff = m_New_array(i).val - m_Old_array(i).val; 15 if max(abs(diff)) > thresh 16 converged = false; 17 return 18 end 19 end
如果消息收敛,则我们可以得到聚类图中各个Cluster的联合分布,每个Cluster可能仅对应1~2个随机变量,很容易就能求到所有随机变量的分布。
MCMC是马尔科夫蒙特卡罗的缩写。马尔科夫指的是马尔科夫链,蒙特卡罗指的是基于频率的随机变量分布推测方法。这里值得注意的是虽然马尔科夫链与马尔科夫场里面都有马尔科夫,这两样东西却是完全不同的。马尔科夫链是描述采样过程的一种模型,马尔科夫场是概率图模型。研究马尔科夫场可以帮助我们对随机变量进行建模,研究马尔科夫链可以帮助我们更好的求解马尔科夫场。对于马尔科夫链而言,我们可以从任意一个状态出发(一个状态就是所有var的一个assignment),转移到另一个状态。而转移到另一个状态的概率由MRF决定。最终,各种状态出现的次数则代表了assignment 对应的val.
吉布斯采样使用了非常朴素的概念,对于一个给定的assignment,如果此时更换var1的取值,则是转向下一个状态了。而var1本身的分布可能知道,但是与var1相关概率的联合分布是由Cluster决定的。只要总结MRF中var1所有的信息,并将上一个assignment作为”后验“,那么就可以求得var1”此时“的边缘分布了。依据此边缘分布决定一个var1的取值并更新assignment,就完成了采样。
所以Gibbs采样中有3个重要的地方:
1、求取与var1有关的分布
2、求取var1在先前assignment条件下的后验分布
3、依据结果分布更新var1的值
1 var_array = 1:length(A); 2 EVDCE = [var_array‘ A‘]; 3 factorLists = G.var2factors(V); 4 for j = 1:length(factorLists) 5 factorList = factorLists{j}; 6 Distribution_= F(factorList(1)); 7 length_fList = length(factorList); 8 if length_fList>1 9 for i = 2:length_fList 10 Distribution_ = FactorProduct(Distribution_,F(factorList(i))); 11 end 12 end 13 end 14 15 EVDCE_var = setdiff(Distribution_.var,V); 16 EVDCE = EVDCE(EVDCE_var,:); 17 target_var = ObserveEvidence(Distribution_,EVDCE); 18 target_var = FactorMarginalization(target_var,setdiff(Distribution_.var,V)); 19 LogBS = target_var.val; 20 LogBS = log(LogBS);
randSample();
在吉布斯采样中,存在陷入某个局部采样循环的风险。简而言之,如果var1,var2,var3具有很强的相关性,那么在给定var2,var3的条件下,var1很难取到其他值。并且,初始条件很容易将Gibbs采样陷入某个MC回环中,使得其无法遍历整个状态空间。最终导致错误的结果。MH采样与Gibbs采样不同,MH一次对所有var的assignment进行更新,同样是状态转移,显然MH会转移的更远。关于MC,其要达到稳态,必须满足稳态性质,定性而言:如果某个状态发生的概率越高,则其转移向其他概率的可能性必须很小,以保证很高的自转移概率。
如果有两个状态s1,s2,如果我们强制从s1 --> s2,那么必须决定从s1 --> s2的概率是多少。定性而言,如果s1 很难发生s2很容易发生,则这个转移发生的概率应该比较高。如果两者都很容易/很难发生,这个转移发生的概率应该一般容易发生。如果s1很容易发生,则转移会很难出现。依赖转移稳定公式建模,则有此转移发生的概率为:
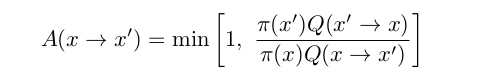
式中:Q是计划转移的概率,pi是assignment发生的概率。A是接受概率。A的作用是对于任意Q,强制转移符合稳定性质。这里有两样东西是未知的:1、Q,2、A。相反pi是已知的。由于基于采样的算法是被用于图像分割等领域,var很多,card却很小,和ORC正好相反。card小的好处是我们可以直接求取联合分布,在依据联合分布进行查询,就可以获得pi了。
*********************************************** Q的设计据说是一份值60W刀年薪的job,不敢妄议。这里我们假设Q是给定的(uniform/SW) **********************************************
MH采样的流程如下:
1、给定Assignment,依据F求pi(Assignment)
2、根据上面的公式计算接受概率A
3、决定是否接受,完成采样更新Assignment
基于团树的精确推理算法可以很好的完成树状结构聚类图的推理,并且运行速度很快。对于多环的结构我们可以选择LBP算法以及基于采样的算法。LBP算法的弱点是MESSAGE难以收敛,会耗费较长时间,但是其可以保证所有的Assignment都能被遍历到。基于采样的算法同样也会耗费一定的时间,但是这个时间是可控的,其决定于我们需要的迭代次数,对某些任务可以牺牲精度来换取迭代次数的减少。
至此,我们完成了所有推理相关工作的作业。然而这并不是完整的概率图,在之前的学习中,我们都假设factor的val是已知的,这个val难道来自秋名山的神秘车牌?显然不是的。它来自机器学习。
由于Coursera Honor Code,不再公布源码。
标签:
原文地址:http://www.cnblogs.com/ironstark/p/5428097.html
