标签:
不管是工业界还是学术界,机器学习都是一个炙手可热的方向,但是学术界和工业界对机器学习的研究各有侧重,学术界侧重于对机器学习理论的研究,工业界侧重于如何用机器学习来解决实际问题。我们结合美团在机器学习上的实践,进行一个实战系列的介绍,介绍机器学习在解决工业界问题的实战中所需的基本技术、经验和技巧。本文主要结合实际问题,概要地介绍机器学习解决实际问题的整个流程,包括对问题建模、准备训练数据、抽取特征、训练模型和优化模型等关键环节;另外几篇则会对这些关键环节进行更深入地介绍。
下文分为:
1)机器学习的概述;2)对问题建模;3)准备训练数据;4)抽取特征;5)训练模型;6)优化模型;7)总结 。
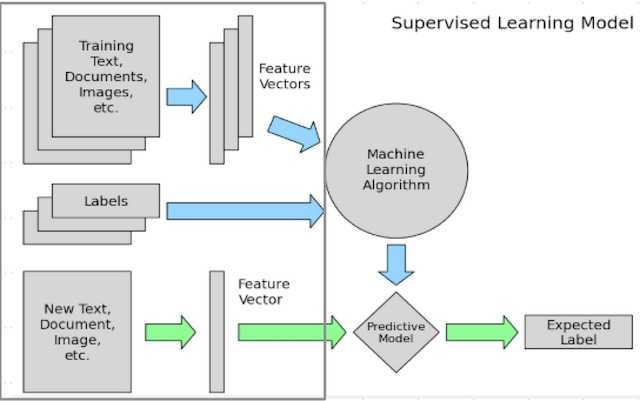
如上图所示是一个经典的机器学习问题框架图。数据清洗和特征挖掘的工作是在灰色框中框出的部分,即“数据清洗=>特征,标注数据生成=>模型学习=>模型应用”中的前两个步骤。
灰色框中蓝色箭头对应的是离线处理部分。主要工作是
1)从原始数据,如文本、图像或者应用数据中清洗出特征数据和标注数据。
2)对清洗出的特征和标注数据进行处理,例如样本采样,样本调权,异常点去除,特征归一化处理,特征变化,特征组合等过程。最终生成的数据主要是供模型训练使用。
◎ 收集问题的资料,理解问题,成为这个问题的专家;
◎ 拆解问题,简化问题,将问题转化机器可预估的问题。
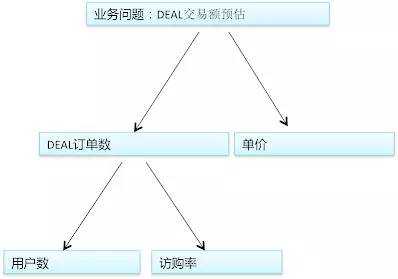
单个模型?多个模型?如何来选择?
按照上图进行拆解后,预估DEAL交易额就有2种可能模式,一种是直接预估交易额;另一种是预估各子问题,如建立一个用户数模型和建立一个访购率模型(访问这个DEAL的用户会购买的单子数),再基于这些子问题的预估值计算交易额。
◎ 不同方式有不同优缺点,具体如下:

◎ 选择哪种模式?
1)问题可预估的难度,难度大,则考虑用多模型;
2)问题本身的重要性,问题很重要,则考虑用多模型;
3)多个模型的关系是否明确,关系明确,则可以用多模型。
◎ 如果采用多模型,如何融合?
可以根据问题的特点和要求进行线性融合,或进行复杂的融合。以本文问题为例,至少可以有如下两种:
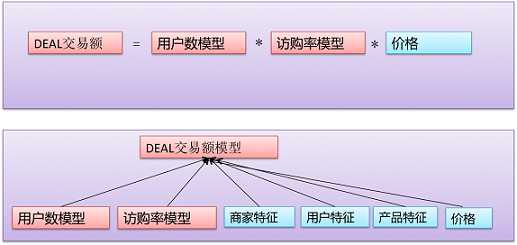
模型选择
对于DEAL交易额这个问题,我们认为直接预估难度很大,希望拆成子问题进行预估,即多模型模式。那样就需要建立用户数模型和访购率模型,因为机器学习解决问题的方式类似,下文只以访购率模型为例。要解决访购率问题,首先要选择模型,我们有如下的一些考虑:
◎主要考虑
1)选择与业务目标一致的模型;
2)选择与训练数据和特征相符的模型。
训练数据少,High Level特征多,则使用“复杂”的非线性模型(流行的GBDT、Random Forest等);
训练数据很大量,Low Level特征多,则使用“简单”的线性模型(流行的LR、Linear-SVM等)。
◎补充考虑
1)当前模型是否被工业界广泛使用;
2)当前模型是否有比较成熟的开源工具包(公司内或公司外);
3)当前工具包能够的处理数据量能否满足要求;
4)自己对当前模型理论是否了解,是否之前用过该模型解决问题。
为实际问题选择模型,需要转化问题的业务目标为模型评价目标,转化模型评价目标为模型优化目标;根据业务的不同目标,选择合适的模型,具体关系如下:
通常来讲,预估真实数值(回归)、大小顺序(排序)、目标所在的正确区间(分类)的难度从大到小,根据应用所需,尽可能选择难度小的目标进行。对于访购率预估的应用目标来说,我们至少需要知道大小顺序或真实数值,所以我们可以选择Area Under Curve(AUC)或Mean Absolute Error(MAE)作为评估目标,以Maximum likelihood为模型损失函数(即优化目标)。综上所述,我们选择spark版本 GBDT或LR,主要基于如下考虑:
1)可以解决排序或回归问题;
2)我们自己实现了算法,经常使用,效果很好;
3)支持海量数据;
4)工业界广泛使用。
准备训练数据
深入理解问题,针对问题选择了相应的模型后,接下来则需要准备数据;数据是机器学习解决问题的根本,数据选择不对,则问题不可能被解决,所以准备训练数据需要格外的小心和注意:
注意点:
◎待解决问题的数据本身的分布尽量一致;
◎训练集/测试集分布与线上预测环境的数据分布尽可能一致,这里的分布是指(x,y)的分布,不仅仅是y的分布;
◎y数据噪音尽可能小,尽量剔除y有噪音的数据;
◎非必要不做采样,采样常常可能使实际数据分布发生变化,但是如果数据太大无法训练或者正负比例严重失调(如超过100:1),则需要采样解决。
常见问题及解决办法
◎待解决问题的数据分布不一致:
1)访购率问题中DEAL数据可能差异很大,如美食DEAL和酒店DEAL的影响因素或表现很不一致,需要做特别处理;要么对数据提前归一化,要么将分布不一致因素作为特征,要么对各类别DEAL单独训练模型。
◎数据分布变化了:
1)用半年前的数据训练模型,用来预测当前数据,因为数据分布随着时间可能变化了,效果可能很差。尽量用近期的数据训练,来预测当前数据,历史的数据可以做降权用到模型,或做transfer learning。
◎y数据有噪音:
1)在建立CTR模型时,将用户没有看到的Item作为负例,这些Item是因为用户没有看到才没有被点击,不一定是用户不喜欢而没有被点击,所以这些Item是有噪音的。可以采用一些简单规则,剔除这些噪音负例,如采用skip-above思想,即用户点过的Item之上,没有点过的Item作为负例(假设用户是从上往下浏览Item)。
◎采样方法有偏,没有覆盖整个集合:
1)访购率问题中,如果只取只有一个门店的DEAL进行预估,则对于多门店的DEAL无法很好预估。应该保证一个门店的和多个门店的DEAL数据都有;
2)无客观数据的二分类问题,用规则来获得正/负例,规则对正/负例的覆盖不全面。应该随机抽样数据,进行人工标注,以确保抽样数据和实际数据分布一致。
访购率问题的训练数据
◎收集N个月的DEAL数据(x)及相应访购率(y);
◎收集最近N个月,剔除节假日等非常规时间 (保持分布一致);
◎只收集在线时长>T 且 访问用户数 > U的DEAL (减少y的噪音);
◎考虑DEAL销量生命周期 (保持分布一致);
◎考虑不同城市、不同商圈、不同品类的差别(保持分布一致)。
抽取特征
完成数据筛选和清洗后,就需要对数据抽取特征,就是完成输入空间到特征空间的转换(见下图)。针对线性模型或非线性模型需要进行不同特征抽取,线性模型需要更多特征抽取工作和技巧,而非线性模型对特征抽取要求相对较低。
对于线性模型,可以仅仅对特征做简单处理,作为模型的输入。
对于非线性模型,需要利用领域知识做非线性特征变换(例如特征组合)特征组合后再来选择特征:如对用户id和用户特征做组合来获得较大的特征集再来选择特征,这种做法在推荐系统和广告系统中比较常见,这也是所谓亿级甚至十亿级特征的主要来源,原因是用户数据比较稀疏,组合特征能够同时兼顾全局模型和个性化模型,这个问题有机会可以展开讲。
extract_fea
通常,特征可以分为High Level与LowLevel,High Level指含义比较泛的特征,LowLevel指含义比较特定的特征,举例来说:
DEAL A1属于POIA,人均50以下,访购率高;
DEAL A2属于POIA,人均50以上,访购率高;
DEAL B1属于POIB,人均50以下,访购率高;
DEAL B2属于POIB,人均50以上,访购率底;
基于上面的数据,可以抽到两种特征,POI(门店)或人均消费;POI特征则是Low Level特征,人均消费则是High Level特征;假设模型通过学习,获得如下预估:
如果DEALx 属于POIA(LowLevel feature),访购率高;
如果DEALx 人均50以下(HighLevel feature),访购率高。
所以,总体上,Low Level 比较有针对性,单个特征覆盖面小(含有这个特征的数据不多),特征数量(维度)很大。High Level比较泛化,单个特征覆盖面大(含有这个特征的数据很多),特征数量(维度)不大。长尾样本的预测值主要受High Level特征影响。高频样本的预测值主要受Low Level特征影响。
对于访购率问题,有大量的High Level或Low Level的特征,其中一些展示在下图:

feature_list
◎非线性模型的特征
1)可以主要使用High Level特征,因为计算复杂度大,所以特征维度不宜太高;
2)通过High Level非线性映射可以比较好地拟合目标。
◎线性模型的特征
1)特征体系要尽可能全面,High Level和Low Level都要有;
2)可以将High Level转换Low Level,以提升模型的拟合能力。
特征归一化
特征抽取后,如果不同特征的取值范围相差很大,最好对特征进行归一化,以取得更好的效果,常见的归一化方式见(一)线性回归与特征归一化(feature scaling)
特征离散化
为了便于表示和在模型中处理,需要对连续值特征进行离散化处理。常用的离散化方法包括等值划分和等量划分。等值划分是将特征按照值域进行均分,每一段内的取值等同处理。例如某个特征的取值范围为[0,10],我们可以将其划分为10段,[0,1),[1,2),...,[9,10)。等量划分是根据样本总数进行均分,每段等量个样本划分为1段。例如距离特征,取值范围[0,3000000],现在需要切分成10段,如果按照等比例划分的话,会发现绝大部分样本都在第1段中。使用等量划分就会避免这种问题,最终可能的切分是[0,100),[100,300),[300,500),..,[10000,3000000],前面的区间划分比较密,后面的比较稀疏。
特征选择
特征抽取和归一化之后,如果发现特征太多,导致模型无法训练,或很容易导致模型过拟合,则需要对特征进行选择,挑选有价值的特征。特征选的的方式分为如下几种:
◎ Filter: 计算每一个特征与响应变量的相关性:工程上常用的手段有计算皮尔逊系数和互信息系数,皮尔逊系数只能衡量线性相关性而互信息系数能够很好地度量各种相关性,但是计算相对复杂一些,好在很多toolkit里边都包含了这个工具(如sklearn的MINE),得到相关性之后就可以排序选择特征了;
◎ Wrapper: 选择一个特征子集加入原有特征集合,用模型进行训练,比较自己加入前后的效果,如果效果变好,则认为该子集特征有效。Wrapper特征选择能剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化模型,协助理解数据产生的过程。其一般过程如下图所示:
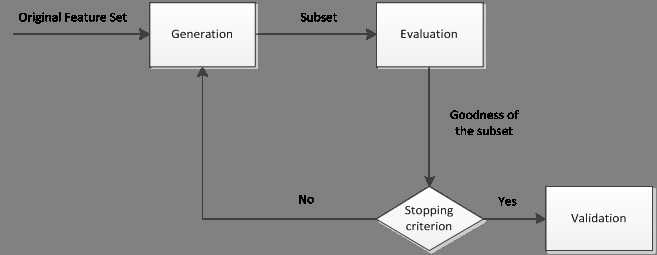
◎ Embedded:特征选择与模型训练结合,在损失函数中加入L1,L2正则。L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验;
综上,下面是一个特征工程的图:
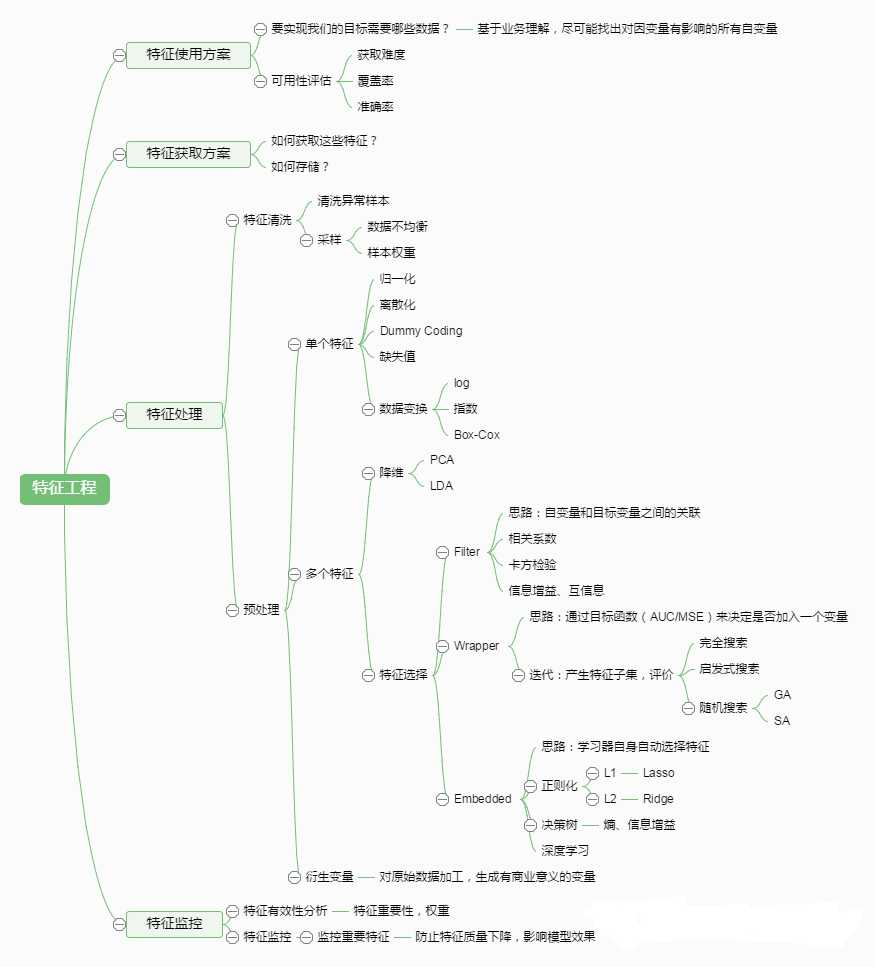
优化模型
经过上文提到的数据筛选和清洗、特征设计和选择、模型训练,就得到了一个模型,但是如果发现效果不好?怎么办?
【首先】
反思目标是否可预估,数据和特征是否存在bug。
【然后】
分析一下模型是Overfitting还是Underfitting,从数据、特征和模型等环节做针对性优化。
Underfitting& Overfitting
所谓Underfitting,即模型没有学到数据内在关系,如下图左一所示,产生分类面不能很好的区分X和O两类数据;产生的深层原因,就是模型假设空间太小或者模型假设空间偏离。
所谓Overfitting,即模型过渡拟合了训练数据的内在关系,如下图右一所示,产生分类面过好地区分X和O两类数据,而真实分类面可能并不是这样,以至于在非训练数据上表现不好;产生的深层原因,是巨大的模型假设空间与稀疏的数据之间的矛盾。
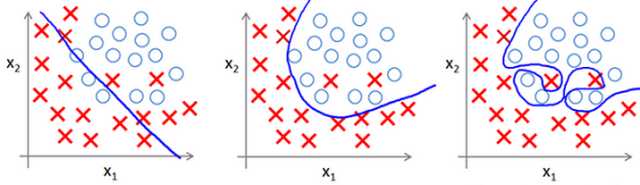
underfitting_overfitting
在实战中,可以基于模型在训练集和测试集上的表现来确定当前模型到底是Underfitting还是Overfitting,判断方式如下表:

怎么解决Underfitting和Overfitting问题?

总结
综上所述,机器学习解决问题涉及到问题建模、准备训练数据、抽取特征、训练模型和优化模型等关键环节,有如下要点:
◎ 理解业务,分解业务目标,规划模型可预估的路线图。
◎ 数据:
y数据尽可能真实客观;
训练集/测试集分布与线上应用环境的数据分布尽可能一致。
◎ 特征:
利用DomainKnowledge进行特征抽取和选择;
针对不同类型的模型设计不同的特征。
◎ 模型:
针对不同业务目标、不同数据和特征,选择不同的模型;
如果模型不符合预期,一定检查一下数据、特征、模型等处理环节是否有bug;
考虑模型Underfitting和Qverfitting,针对性地优化。
标签:
原文地址:http://www.cnblogs.com/ooon/p/5434123.html