标签:
作者:寒小阳 && 龙心尘
时间:2016年4月
出处:
http://blog.csdn.net/han_xiaoyang/article/details/51253274
http://blog.csdn.net/longxinchen_ml/article/details/51253526
声明:版权所有,转载请联系作者并注明出处
特别鸣谢:北京大学焦剑博士对Recurrent Neural Networks Tutorial part1一文的翻译和部分内容提供
在离人工智能越来越近的今天,研究界和工业界对神经网络和深度学习的兴趣也越来越浓,期待也越来越高。
我们在深度学习与计算机视觉专栏中看过计算机通过卷积神经网络学会了识别图片的内容——模仿人类的看,而工业界大量的应用也证明了神经网络能让计算机学会听(比如百度的语音识别),于是大量的精力开始投向NLP领域,让计算机学会写也一定是非常有意思的事情,试想一下,如果计算机通过读韩寒和小四的小说,就能写出有一样的调调的文字,这是多带劲的一件事啊。
你还别说,还真有这么一类神经网络,能够在NLP上发挥巨大的作用,处理从语言模型(language model)到双语翻译,到文本生成,甚至到代码风格模仿的问题。这就是我们今天要介绍的RNN(递归神经网络)。
RNN是一个和时间序列有关系的神经网络,大家想想,对单张图片而言,像素信息是静止的,而对于一段话而言,里面的词的组成是有先后的,而且通常情况下,后续的词和前面的词有顺序关联。这时候,独立层级结构的卷积神经网络通常就很难处理这种时序关联信息了,而RNN却能有效地进行处理。
RNN在处理时间序列的内容有多有效呢,咱们列一些RNN处理的例子来一起看看。
我们知道卷积神经网络在0-9数字识别上已经能有人类的识别精确度了,但是对于一连串的数字,还是得有一些特殊的处理的。比如说,下面是让RNN学会了从左到右读数字门牌号。

我们也能让RNN学着从右到左自己绘出门牌号图片:

RNN能模仿各种格式的文件,比如说下面是RNN学习出来的XML文件,和Latex代数几何文件样本:
<page>
<title>Antichrist</title>
<id>865</id>
<revision>
<id>15900676</id>
<timestamp>2002-08-03T18:14:12Z</timestamp>
<contributor>
<username>Paris</username>
<id>23</id>
</contributor>
<minor />
<comment>Automated conversion</comment>
<text xml:space="preserve">#REDIRECT [[Christianity]]</text>
</revision>
</page>

我们暂时不管内容正确性,这个格式编排能力,已经让我瞠目结舌。
爱折腾的程序猿GG们,当然会把握住一切可学习的资源,于是乎,他们把github上linux的源码拉下来了,然后喂给递归神经网络学习,两三天后…我们发现它能自己生成如下的代码块了
/*
* Increment the size file of the new incorrect UI_FILTER group information
* of the size generatively.
*/
static int indicate_policy(void)
{
int error;
if (fd == MARN_EPT) {
/*
* The kernel blank will coeld it to userspace.
*/
if (ss->segment < mem_total)
unblock_graph_and_set_blocked();
else
ret = 1;
goto bail;
}
segaddr = in_SB(in.addr);
selector = seg / 16;
setup_works = true;
for (i = 0; i < blocks; i++) {
seq = buf[i++];
bpf = bd->bd.next + i * search;
if (fd) {
current = blocked;
}
}
rw->name = "Getjbbregs";
bprm_self_clearl(&iv->version);
regs->new = blocks[(BPF_STATS << info->historidac)] | PFMR_CLOBATHINC_SECONDS << 12;
return segtable;
}且不说代码内容是否有意义,这标准的C代码风格,看完已有吓尿的趋势。
哦,对,刚才我们提了RNN对文字的处理能力。我们来看看,Andrej Karpathy自己做了一个实验,把所有莎士比亚的作品串起来组成一个单一的(4.4MB)文件。训练了一个512个隐藏节点的3层RNN网络。训练网络几小时后,得到了如下样本结果:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain‘d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I‘ll have the heart of the wars.
Clown:
Come, sir, I will make did behold your worship.
VIOLA:
I‘ll drink it.恩,作为一个文学功底弱哭的码农,莎士比亚这样的大文豪,文笔风格我是读不出来的。但是我们有韩寒啊,我们有广大女中学生稀饭的四娘啊,于是我们去github上扒了一份能处理中文的char-rnn代码下来。把四娘的大作集合,从《幻城》到《左手倒影右手年华》,再到《悲伤逆流成何》和《小时代》,处理了处理,放在一起(咳咳,我只是拿来做实验学习的,不传播…版权问题表找博主…),丢给RNN学习了,然后,恩,我们看看它能学到什么。
每个人,闭上眼睛的时候,才能真正面对光明
他们在吱呀作响的船舷上,静静看着世界,没有痛苦的声音,碎裂的海洋里摇晃出阵阵沉默,吞噬过来。他们的躯体,一点,一点,逐渐暗淡在巨浪中,下沉。温润、潮湿、环抱,他手中兰花草磨成的微笑已经腐烂。记忆破蛹而出,翻滚着随风摆动的兰花草,气味扑鼻,海潮依旧。
你们虔诚的看着远方,我抬起头,不经意间,目光划过你们的面庞,上面淡淡的倔强印,那么坚强
尘世凡间
沉睡亿万光年的年轻战士
萦绕不散的寂寞烟云中
静候在末世岛屿之上
守候,女王何时归来
你的目光延向她迟归的方向
缓缓推进的海浪
这最后一夜
荡漾小四的文字我是看不懂的,不过RNN生成的这些文字,却让我也隐约感受到了一些“45度角仰望天空,眼泪才不会掉下来”的气息,当然,这几段已是输出结果中比较好的内容,也有一些通畅程度一般的,但足以证明递归神经网络在NLP上有不可思议的学习能力。
刚才被递归神经网络惊呆的小伙伴们,咱们把目光先从小四那里收回来。看看这神奇的递归神经网络到底是何许神物,背后的原理又是什么样的。
传统的神经网络(包括CNN)中我们假定所有输入和输出都是相互独立的。很遗憾,对于许多任务而言,这一个假设是不成立的。如果你想预测下一个单词或一个句子,你就需要知道前面的词。递归神经网络之所以被称作递归,就是因为每个元素都执行相同的任务序列,但输出依赖之前的计算结果。我们换一种方法说明一下RNN:大家可以想象RNN模型是有“记忆”的,“记忆”中存储着之前已经计算的信息。理论上说RNN可以记得并使用任意长度的序列中的信息,不过实际应用中,我们通常只回溯几个步骤(后面详细讨论)。我们先一起来看一个典型的RNN的图例:

上图显示了将RNN展开成一个完整的网络的过程。之所以我们用展开这个字眼,因为递归神经网络每一层(或者我们叫做每个时间点t)到下一层(下一个时间点),其变换的过程(权重W)是一致的。举个例子说,如果我们关注的序列是包含5个单词的句子,递归神经网络将会依据先后顺序展开成五个神经网络,每个单词为一层。RNN是根据下面的步骤来迭代和做计算的:
假定
假定
针对上面的步骤,咱们再细提几个点:
我们就可以直接把隐状态
不像普通的深度神经网络,每一层和每一层之间都会有不同的权重参数,一个RNN神经网络共享同一组参数
上面的图表在每一步都有输出/output,但是根据任务不同,有时候并没有必要在每一步都有输出。比如说我们对句子的情感做判定的时候,我们其实只关心最后的情感判定结果,而不是中间每个词的结果。RNN最主要的特征是隐状态,因为它是“记忆体”,保留了之前的绝大多数信息。
刚才我们提到的RNN只是最原始版本的RNN,而近几年随着研究者的深入,提出了一系列新的RNN网络类型。比如:
双向RNN的思想和原始版RNN有一些许不同,只要是它考虑到当前的输出不止和之前的序列元素有关系,还和之后的序列元素也是有关系的。举个例子来说,如果我们现在要去填一句话中空缺的词,那我们直观就会觉得这个空缺的位置填什么词其实和前后的内容都有关系,对吧。双向RNN其实也非常简单,我们直观理解一下,其实就可以把它们看做2个RNN叠加。输出的结果这个 时候就是基于2个RNN的隐状态计算得到的。
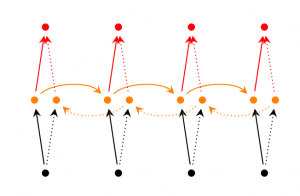
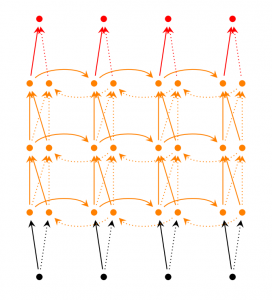
深层双向RNN和双向RNN比较类似,区别只是每一步/每个时间点我们设定多层结构。实际应用的时候,这种方式可以让我们的神经网络有更大的容量(但这也意味着我们需要更多的训练数据)
LSTM(Long Short Term Memory)可能是目前最流行,你见到各种paper提到最多的RNN神经网络了。LSTM和基线RNN并没有特别大的结构不同,但是它们用了不同的函数来计算隐状态。LSTM的“记忆”我们叫做细胞/cells,你可以直接把它们想做黑盒,这个黑盒的输入为前状态
下面我们用python和Theano库实现一个简单的RNN,并解决一类最常见但有有用的NLP问题,语言模型。
语言模型是NLP中最常见和通用的一个概念。它能帮助我们判定一个短语串或者一句话出现的概率(在给定一个语料集后)。这在各种打分机制中非常非常有用,比如翻译系统中翻译结果的选定,比如语音识别中文字串的选定。关于语言模型具体的内容可以参见我们之前的博文从朴素贝叶斯到N-gram语言模型。
我们这里的目标就是要用RNN构建语言模型,即输出短语串/一句话的概率
上式中,
我们需要一些文本语料去让RNN学习,所幸的是,并不像有监督学习中,每个样本都需要标注一个结果,这里只要句子或者短语串就可以。因此我们从reddit(类似百度贴吧)中抓了15000条长评论下来。我们希望RNN能学到这些评论者的评论风格(就像神奇的帝吧),并能模仿他们生成一些话。但是我们都知道,机器学习问题,效果的上限其实取决于你的数据,所以我们都需要对数据先做一些预处理。
最初的语料文本需要一些简单的处理才能交给机器学习算法学习,比如句子最常见的处理是分词,对于英语而言,有纯天然的空格分隔开,对中文而言,我们需要自己去做断句和分词。比如英文的句子 “He left!”可以分词成3部分: “He”, “left”, “!”。这里使用python的NLTK包做分词处理。
其实绝大多数词在我们的文本中就只会出现一两次,而这些极度不常出现的词语,其实去掉就行了,对最后的结果反倒有帮助。太多的词语,一方面让模型的训练变得很慢,同时因为它们只出现一两次,所以我们从语料中也学不出太多和它们相关的知识。因此我们有很简单的处理方法来处理它们。
比如说,我们就限定我们的语料库是8000词的,这8000词以外的词语我们都用UNKNOWN_TOKEN这个特殊字符来标注。比如单词“nonlinearities”不在我们的8000词汇集中,那“nonlineraties are important in neural networks”这句话就要被我们处理成“UNKNOWN_TOKEN are important in Neural Networks”了。我们完全可以把UNKNOWN_TOKEN视作一个新的词汇,而对于它的预测也和其他词完全一样。
分词后,一句话变成一个词/短语 串,我们再做一些特殊的处理,比如把SENTENCE_START和SENTENCE_END添加到词/短语 串首位当做特殊的开始于结束标志。这样句子第一个词的预测可以看做出现SENTENCE_START后,出现第一个词的概率。
对于词向量的编码,我们打算用最简单的词序列编码。解释一下,大概是这样。一句简单的“I left home”的输入x可能被译作[0, 179, 341, 416], 其中0对应句子起始符SENTENCE_START,而I在词表中的下标为179,而输出y会被译作[179, 341, 416, 1]。这个可理解吧,因为我们在做的事情,是由前面的词语,推断后面的词语。
代码大概是下面这个样子:
vocabulary_size = 8000
unknown_token = "UNKNOWN_TOKEN"
sentence_start_token = "SENTENCE_START"
sentence_end_token = "SENTENCE_END"
# 读取数据,添加SENTENCE_START和SENTENCE_END在开头和结尾
print "Reading CSV file..."
with open(‘data/reddit-comments-2015-08.csv‘, ‘rb‘) as f:
reader = csv.reader(f, skipinitialspace=True)
reader.next()
# 分句
sentences = itertools.chain(*[nltk.sent_tokenize(x[0].decode(‘utf-8‘).lower()) for x in reader])
# 添加SENTENCE_START和SENTENCE_END
sentences = ["%s %s %s" % (sentence_start_token, x, sentence_end_token) for x in sentences]
print "Parsed %d sentences." % (len(sentences))
# 分词
tokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences]
# 统计词频
word_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences))
print "Found %d unique words tokens." % len(word_freq.items())
# 取出高频词构建词到位置,和位置到词的索引
vocab = word_freq.most_common(vocabulary_size-1)
index_to_word = [x[0] for x in vocab]
index_to_word.append(unknown_token)
word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])
print "Using vocabulary size %d." % vocabulary_size
print "The least frequent word in our vocabulary is ‘%s‘ and appeared %d times." % (vocab[-1][0], vocab[-1][1])
# 把所有词表外的词都标记为unknown_token
for i, sent in enumerate(tokenized_sentences):
tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent]
print "\nExample sentence: ‘%s‘" % sentences[0]
print "\nExample sentence after Pre-processing: ‘%s‘" % tokenized_sentences[0]
# 构建完整训练集
X_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences])
y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])下面是一个实际的句子在这8000词汇的语料库中,映射成的X和Y,
x:
SENTENCE_START what are n’t you understanding about this ? !
[0, 51, 27, 16, 10, 856, 53, 25, 34, 69]
y:
what are n’t you understanding about this ? ! SENTENCE_END
[51, 27, 16, 10, 856, 53, 25, 34, 69, 1]
我们还记得RNN的结构是下面这样的:
我们先来做一些数据设定和构建。
假设输入x为词序列(就像前面提到的一样),其中每个
然后我们复习一下之前说到的RNN前向计算公式:
咳咳,咱们是严谨派,再确认下各种输入输出的维度好了。我们假设词表大小C = 8000,而隐状态向量维度H = 100。这里需要提一下的是,我们之前也说到了,这个隐状态有点类似人类的“记忆体”,之前的数据信息都存储在这里,其实把它的维度设高一些可以存储更多的内容,但随之而来的是更大的计算量,所以这是一个需要权衡的问题。所以我们有下面一些设定:
对了,其中U,V和W是RNN神经网络的参数,也就是我们要通过对语料学习而得到的参数。所以,总的说下来,我们需要
初始化参数
我们定义一个类,叫做RNNNumpy,初始化U,V和W还是有一些讲究的,我们不能直接把它们都初始化为0,这样在计算过程中会出现“对称化”问题。初始化的不同对于最后的训练结果是有不同的影响的,在这个问题上有很多的paper做了相关的研究,其实参数初始值的选定和咱们选定的激励函数是有关系的,比如我们这里选
以下是对应的python代码,其中word_dim是词表大小,hidden_dim是隐层大小,bptt_truncate大家先不用管,我们一会儿会介绍到。
class RNNNumpy:
def __init__(self, word_dim, hidden_dim=100, bptt_truncate=4):
# 给词表大小,隐状态维度等赋值
self.word_dim = word_dim
self.hidden_dim = hidden_dim
self.bptt_truncate = bptt_truncate
# 随机初始化参数U,V,W
self.U = np.random.uniform(-np.sqrt(1./word_dim), np.sqrt(1./word_dim), (hidden_dim, word_dim))
self.V = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (word_dim, hidden_dim))
self.W = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (hidden_dim, hidden_dim))前向计算
这个和卷积神经网络的前向运算完全一样,就是一个根据权重计算下一层/下一个时间点的输出、隐状态的过程。简单的实现如下:
def forward_propagation(self, x):
# 总共的 序列/时间 长度
T = len(x)
# 在前向计算时,我们保留所有的时间隐状态s,因为之后会用到
# 初始的隐状态设为 0
s = np.zeros((T + 1, self.hidden_dim))
s[-1] = np.zeros(self.hidden_dim)
# 在前向计算时,我们也保留所有的时间点输出o,之后也会用到
o = np.zeros((T, self.word_dim))
# 每个时间/序列点 进行运算
for t in np.arange(T):
# one-hot编码矩阵乘法,可以视作列选择
s[t] = np.tanh(self.U[:,x[t]] + self.W.dot(s[t-1]))
o[t] = softmax(self.V.dot(s[t]))
return [o, s]
RNNNumpy.forward_propagation = forward_propagation
从上面的代码我们也可以看到,我们不仅计算了输出o,同时我们也计算了隐状态s。我们之后得用它们去计算梯度,再重复一下哈,这里的每个
def predict(self, x):
# 做前向计算,取概率最高的词下标
o, s = self.forward_propagation(x)
return np.argmax(o, axis=1)
RNNNumpy.predict = predict来来来,试跑一下:
np.random.seed(10)
model = RNNNumpy(vocabulary_size)
o, s = model.forward_propagation(X_train[10])
print o.shape
print o
(45, 8000)
[[ 0.00012408 0.0001244 0.00012603 ..., 0.00012515 0.00012488
0.00012508]
[ 0.00012536 0.00012582 0.00012436 ..., 0.00012482 0.00012456
0.00012451]
[ 0.00012387 0.0001252 0.00012474 ..., 0.00012559 0.00012588
0.00012551]
...,
[ 0.00012414 0.00012455 0.0001252 ..., 0.00012487 0.00012494
0.0001263 ]
[ 0.0001252 0.00012393 0.00012509 ..., 0.00012407 0.00012578
0.00012502]
[ 0.00012472 0.0001253 0.00012487 ..., 0.00012463 0.00012536
0.00012665]]对于句子(这里长度为45)中的每个词, 我们的模型得到了8000个概率(对应词表中的词)。额,我们这里只是验证一下前向运算是否能正常进行,但是参数U,V,W是随机取的,未训练,因此得到的结果其实是随机的。
然后验证下predict函数:
predictions = model.predict(X_train[10])
print predictions.shape
print predictions
(45,)
[1284 5221 7653 7430 1013 3562 7366 4860 2212 6601 7299 4556 2481 238 2539
21 6548 261 1780 2005 1810 5376 4146 477 7051 4832 4991 897 3485 21
7291 2007 6006 760 4864 2182 6569 2800 2752 6821 4437 7021 7875 6912 3575]计算损失函数
和其他机器学习算法一样一样的是,我们需要一个损失函数/loss function来表征现在的预测结果和真实结果差别有多大,也便于我们之后的迭代和训练。一个比较通用的损失函数叫做互熵损失,有兴趣仔细了解的同学,可以看看我们之前的博客线性SVM与SoftMax分类器,如果我们有N个训练样本(这里显然是句子中词的个数咯),C个类别(这里显然是词表大小咯),那我们可以这样去定义损失函数描述预测结果o和实际结果y之间的差距:
公式看起来略吓人,但其实它做的事情就是把每个样本的损失加一加,然后输出,我们定义了一个calculate_loss函数:
def calculate_total_loss(self, x, y):
L = 0
# 对于每句话
for i in np.arange(len(y)):
o, s = self.forward_propagation(x[i])
# 我们只在乎预测对的那个词的概率
correct_word_predictions = o[np.arange(len(y[i])), y[i]]
# 加到总loss里
L += -1 * np.sum(np.log(correct_word_predictions))
return L
def calculate_loss(self, x, y):
# 除以总样本数
N = np.sum((len(y_i) for y_i in y))
return self.calculate_total_loss(x,y)/N
RNNNumpy.calculate_total_loss = calculate_total_loss
RNNNumpy.calculate_loss = calculate_loss用随机梯度下降和时间反向传播训练RNN
现在损失函数也有咯,我们要做的事情就是最小化这个损失函数,以让我们的预测结果和真实的结果最接近咯。最常用的优化算法叫做SGD(随机梯度下降),大家可以理解成我们要从一座山上下山,于是我们每到一个位置,都环顾一下四周,看看最陡(下山最快)的方向是什么,然后顺着它走走,“随机”的意思是我们其实不用全部的样本去计算这个方向,而是用部分样本(有时候是一个)来计算。
计算这个方向就是我们计算梯度的过程,从数学上来说,其实就是在给定损失函数
细致的内容我们之后会再提到,这里呢,简单地告诉大家,我们需要一个反向传播(时间轴上的)来用求导链式法则计算梯度。代码如下:
def bptt(self, x, y):
T = len(y)
# 反向计算
o, s = self.forward_propagation(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(T)[::-1]:
dLdV += np.outer(delta_o[t], s[t].T)
# Initial delta calculation
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:,x[bptt_step]] += delta_t
# 每一步更新delta
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]
RNNNumpy.bptt = bptt恩,然后我们需要根据梯度来迭代和更新参数,也就是要顺着坡度方向下山咯。
# Outer SGD Loop
# - model: The RNN model instance
# - X_train: The training data set
# - y_train: The training data labels
# - learning_rate: Initial learning rate for SGD
# - nepoch: Number of times to iterate through the complete dataset
# - evaluate_loss_after: Evaluate the loss after this many epochs
def train_with_sgd(model, X_train, y_train, learning_rate=0.005, nepoch=100, evaluate_loss_after=5):
# We keep track of the losses so we can plot them later
losses = []
num_examples_seen = 0
for epoch in range(nepoch):
# Optionally evaluate the loss
if (epoch % evaluate_loss_after == 0):
loss = model.calculate_loss(X_train, y_train)
losses.append((num_examples_seen, loss))
time = datetime.now().strftime(‘%Y-%m-%d %H:%M:%S‘)
print "%s: Loss after num_examples_seen=%d epoch=%d: %f" % (time, num_examples_seen, epoch, loss)
# Adjust the learning rate if loss increases
if (len(losses) > 1 and losses[-1][1] > losses[-2][1]):
learning_rate = learning_rate * 0.5
print "Setting learning rate to %f" % learning_rate
sys.stdout.flush()
# For each training example...
for i in range(len(y_train)):
# One SGD step
model.sgd_step(X_train[i], y_train[i], learning_rate)
num_examples_seen += 1那个,那个,我们得试验一下,是不是这玩意确实能让我们下山。恩,也就是迈着步子的过程,你得看看,我们的海拔是不是每次都降了一些。我们这个地方也来检查一下:
np.random.seed(10)
# 在小样本集上试试
model = RNNNumpy(vocabulary_size)
losses = train_with_sgd(model, X_train[:100], y_train[:100], nepoch=10, evaluate_loss_after=1)2015-09-30 10:08:19: Loss after num_examples_seen=0 epoch=0: 8.987425
2015-09-30 10:08:35: Loss after num_examples_seen=100 epoch=1: 8.976270
2015-09-30 10:08:50: Loss after num_examples_seen=200 epoch=2: 8.960212
2015-09-30 10:09:06: Loss after num_examples_seen=300 epoch=3: 8.930430
2015-09-30 10:09:22: Loss after num_examples_seen=400 epoch=4: 8.862264
2015-09-30 10:09:38: Loss after num_examples_seen=500 epoch=5: 6.913570
2015-09-30 10:09:53: Loss after num_examples_seen=600 epoch=6: 6.302493
2015-09-30 10:10:07: Loss after num_examples_seen=700 epoch=7: 6.014995
2015-09-30 10:10:24: Loss after num_examples_seen=800 epoch=8: 5.833877
2015-09-30 10:10:39: Loss after num_examples_seen=900 epoch=9: 5.710718恩,还凑合,看样子确实在带着我们迈向成功,O(∩_∩)O~
恩,上面就是一个完整的简易RNN实现,至少,是可用的。
不过尴尬的是。。。同学们有木有发现,在CPU上,这样的每一轮迭代,都要花费160ms左右的时间。这蛋碎的速度,加上RNN巨大的训练轮数,要把小四的作品都学完,咳咳,估计人家下几本书都出了。于是只好祭出大杀器——GPU,配合某python深度学习库Theano来加速了:
from utils import load_model_parameters_theano, save_model_parameters_theano
model = RNNTheano(vocabulary_size, hidden_dim=50)
losses = train_with_sgd(model, X_train, y_train, nepoch=50)
save_model_parameters_theano(‘./data/trained-model-theano.npz‘, model)
load_model_parameters_theano(‘./data/trained-model-theano.npz‘, model)这就是用开源库的好处,纯手撸的N行代码,在这里调了几个函数就Done了…恩,感谢开源精神…
产出文本
有模型之后,我们就可以试着去生成概率最高的文本了。
def generate_sentence(model):
# 从 start token/开始符 开始一句话
new_sentence = [word_to_index[sentence_start_token]]
# 直到拿到一个 end token/结束符
while not new_sentence[-1] == word_to_index[sentence_end_token]:
next_word_probs = model.forward_propagation(new_sentence)
sampled_word = word_to_index[unknown_token]
while sampled_word == word_to_index[unknown_token]:
samples = np.random.multinomial(1, next_word_probs[-1])
sampled_word = np.argmax(samples)
new_sentence.append(sampled_word)
sentence_str = [index_to_word[x] for x in new_sentence[1:-1]]
return sentence_str
num_sentences = 10
senten_min_length = 7
for i in range(num_sentences):
sent = []
# 短句就不要咯,留下长的就好
while len(sent) < senten_min_length:
sent = generate_sentence(model)
print " ".join(sent)然后你就发现,上面的模型能模仿reddit中的评论,去生成一些句子了。比如:
居然连标点和有些标点组成的表情都模仿出来了,还是灰常神奇的,当然,基线版的RNN也产出了非常非常多的不顺畅句子,这个和我们的语料量,以及中间隐状态的维度有关系。但另外一点是,这种方式的RNN,“记忆体”并不是最合适的,比如最近很火的LSTM和GRU都能更好地处理历史信息的记忆和遗忘过程。这个我们会在之后的博客里面提到。
以上就是这篇RNN简介的所有内容,RNN确实是一个非常神奇的神经网络,而在对时间序列信息(比如NLP自然语言处理)上也有着独到的优势。更多的RNN与NLP处理的知识(比如LSTM)我们在之后的博客里会提到,现在的RNN能基于大量的语料学习写一些简单的句子,相信有一天,计算机也能写出大段的优美诗歌,赏心悦目的文字,长篇情节跌宕起伏的小说。
参考文献:
1、Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
2、Recurrent Neural Networks Tutorial, Part 2 – Implementing a RNN with Python, Numpy and Theano
3、The Unreasonable Effectiveness of Recurrent Neural Networks
标签:
原文地址:http://blog.csdn.net/longxinchen_ml/article/details/51253526