标签:
不少同学抱怨,在集群的GPU节点上运行caffe程序时,经常出现"Out of Memory"的情况。实际上,如果我们在提交caffe程序到某个GPU节点的同时,指定该节点某个比较空闲的gpu id,便可以避免"Out of Memory"的情况。步骤如下:
1. 在提交任务前,制作一个带有“nvidia-smi”命令的run_gpu.sh文件
#!/bin/bash #$ -V #$ -cwd #$ -j y #$ -S /bin/bash nvidia-smi
2. 提交run_gpu.sh文件到某个GPU节点(以g0502为例)
qsub -l h=g0502 run_gpu.sh
3. 查看run_gpu.sh任务的运行结果
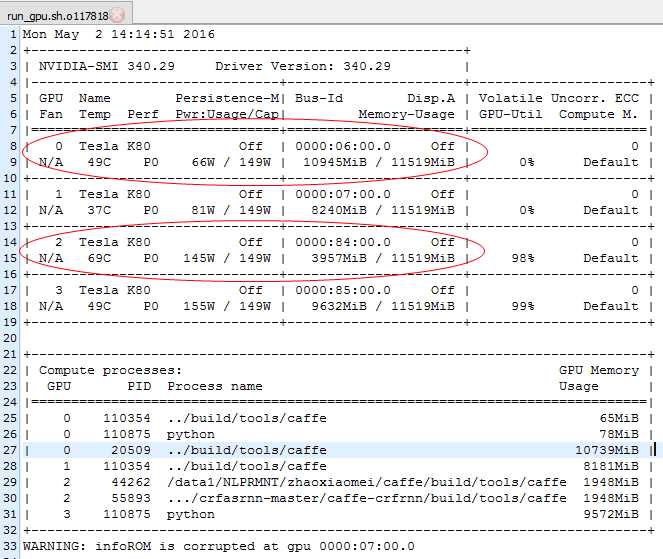
可以看到,g0502节点有四块gpu,id分别为0, 1, 2, 3。其中0,1和3的内存几乎都已经占满了,只有2稍微空闲一些。所以,若在提交caffe程序到g0502节点上,需要指定运行caffe程序的gpu id为2。否则,提交上去的caffe程序将默认gpu id为0,导致很有可能出现"Out of Memory"的情况。
4. 在提交caffe程序的.sh文件(如caffe_train.sh)中指定gpu id。
1 #!/bin/bash 2 #$ -V 3 #$ -cwd 4 #$ -j y 5 #$ -S /bin/bash 6 7 ./build/tools/caffe train -gpu 2 -solver models/segnet/segnet_building_solver.prototxt
在.sh文件的第7行,"-gpu 2"的含义为显式指定gpu id为2。
5. 提交caffe_train.sh文件到g0502节点。
qsub -l h=g0502 caffe_train.sh
6. 查看caffe_train.sh.o文件

可以看到,caffe_train.sh文件指定了g0502节点中gpu id为2的gpu来运行caffe程序。这样,我们便可以在很大程度上避免在集群上运行的caffe程序出现"Out of Memory"的情况。
7. 用matcaffe测试训练好的caffemodel时指定gpu id
与训练时一样,用matcaffe测试训练好的caffemodel时,我们也可以显式指定gpu id,以避免出现“Out of Memory"的情况。与在caffe_train.sh文件中指定gpu id不一样,测试时,我们需要在.m文件中显式指定gpu id。而不是在.sh文件中指定。
caffe.set_mode_gpu(); caffe.set_device(2); % set gpu id net = caffe.Net(model, weights,‘test‘);
第2行,caffe.set_device(2),显式指定gpu id为2。
8. 用pycaffe测试训练好的caffemodel时指定gpu id
与matcaffe同理,我们需要在.py文件中显式指定gpu id。
1 import caffe 2 #..... 3 if __name__ == ‘__main__‘: 4 caffe.set_mode_gpu() 5 # set gpu_id 6 caffe.set_device(2);
第6行,caffe.set_device(2),显式指定gpu id为2。
至此,我们便可以通过指定集群某个节点中较为空闲的gpu id来避免出现“Out of Memory"的情况~^_^~
在集群上运行caffe程序时如何避免Out of Memory
标签:
原文地址:http://www.cnblogs.com/hzm12/p/5452329.html