标签:
1、YARN:将资源管理和作业调度/监控分成两个独立的进程。
包含两个组件:ResourceManager和ApplicationMaster
2、YARN的特性:
1)可扩展性;2)高可用性(HA);3)兼容性(1.0版本的作业也可以执行);4)提高集群利用率;
5)支持MapReduce编程范式。
3、Hadoop的进程:
1)NameNode HDFS的守护进程;
2)Secondary NameNode 监控HDFS状态的辅助后台程序,备用NameNode;
3)DataNode 负责把HDFS的数据块写到本地文件系统,数据块大小默认64MB;
4)ResourceManager 是一个中心服务,它负责调度、启动每一个Job与资源分配;
5)NodeManager 管理YARN集群的每一个节点,它负责Container状态的维护(CPU、内存、硬盘、网络),并向ResourceManager保持心跳;
6)ApplicationMaster 负责一个Job生命周期内的所有工作。
4、HDFS常用命令(略)
5、Hadoop常用配置参数详解(略)
6、Hive的三个主要接口:命令行Cli、客户端Client和Web界面WUI
1)最常用CLI,启动的时候会同时启动一个Hive服务,将写好的脚本放到Cli中执行。
2)Clinet是Hive的客户端,用户连接至HiveServer。
3)WUI是通过浏览器访问Hive的Web工具。
7、Hive元数据一般存储在数据库中,如MySQL(多用户)或Derby嵌入式数据库(单用户)中。
8、Hive的数据是存储在HDFS中的(包括外部表和内部表),大部分查询由MapReduce完成。
9、Hive的常用进程和服务:使用hive –service help命令可以看到Hive提供的服务。
cli:命令行接口。
hiveserver:客户端接口。
hwi:Hive的Web接口。
jar:与Hadoop jar等价的Hive接口。
metastore:元数据提供的服务。
10、Metastore的三种连接方式:单用户(Derby)、多用户(MySQL)和远程连接(如使用Thrift)
11、Hive语言,不支持Insert和Update,因为数据仓库的内容是读多写少,所有的数据要在加载时确定好,他的数据都是存储在HDFS中。
12、Hive没有专门定义的数据格式,格式由用户指定,用户在定义数据格式需要指定三个属性。
1)列分隔符(通常用空格、“\t”)
2)行分隔符(“\n”)
3)读取文件数据的方式(默认有三种:TextFile、SequenceFile、RCFile)
13、Hive不会对数据进行任何处理,也不会对数据进行扫描,因此不会建立索引。
14、Hive的查询是通过Hadoop来实现的,不是通过自己的执行引擎。
15、Hive的执行延迟较高,通常都是离线执行的,但是处理的数据量大。
16、Hive的扩展性非常好,可以扩展到上千台Hadoop。
17、Hive --database temp 直接进入temp数据库。
18、set -v / reset 设置或重置参数变量。
如:set mapred.reduce.tasks=10;
19、!执行外部shell命令。如:! ls --列出当前目录下的文件。
20、dfs 执行HDFS命令。
如:dfs -mkdir /user/Hadoop/warehouse;
21、add file / list file / delete file管理分步缓冲区资源,这些资源在所有的机器上都可以使用。
22、Hive -S 静默不输出。
23、插入数据:insert overwrite table HUserInfo select * from old_userinfo --从另一张表导入数据
24、hive -e ‘set;’ | grep mapred.reduce.tasks; //-e表示在外部直接执行后面的命令。
25、hive -d sitename=www.baidu.com //定义一个变量
26、跨库查询:select * from hive.Huserinfo;
27、假如外部有一个sql脚本get_order_sum.sql
hive -f /home/hadoopuser/scripts/get_order_sum.sql; //可以直接运行这个脚本
hive -v -f /home/hadoopuser/scripts/get_order_sum.sql; //可以把脚本里的sql也显示出来
hive -S -f /home/hadoopuser/scripts/get_order_sum.sql > test.txt; //静默执行 并把结果输出到txt中
28、Hive常用配置参数(略)在文件.hiverc中配置
29、Hive清数据,Hive不支持Delete
使用truncate table tablename;
清一个分区的数据:truncate table tablename partition dt=’2015-10-6’;
30、删除的数据到了回收站:.trash
31、创建索引,和SQL一样。
CREATE INDEX index_name ON TABLE tablename(col_name)AS index_type;
32、角色管理,对权限控制最好使用角色来控制。(略)
33、DESC命令,查看数据库或表的一些基本信息。
34、Hive四种导入数据的方式:
1)load data local inpath ‘1234.txt‘ into table mytable;
2)load data inpath ‘/home/hadoopuser/1234.txt‘ into table mytable;
3)insert overwrite table mytable
> PARTITION (age)
> select id, name, tel, age
> from oldtable;
4)create table mytable
> as
> select id, name, tel
> from oldtable;
35、创建Hive表的时候如何创建动态分区?
36、Hive数据查询支持正则,当你不知道列名的时候可以用。
SELECT ‘正则’ FROM mytable;
39、数据排序
order by全局排序
sort by只在一个reducer中排序
distribyte by将指定的内容分到同一个reducer中
cluster by = distribyte by + sort by
40、实用的写法
SELECT * FROM table1 t1,table2 t2,table3 t3 WHERE t1.id=t2.id AND t2.id=t3.id;
41、semi-join比一般的inner join更为高效。
42、CTE
WITH q1 AS (SELECT * FROM src WHERE key>50)
下面就可以直接使用q1这个临时表。
43、什么是UDF?UDAF?UDTF?
User Defined Function(用户自定义函数)
44、什么是分析函数?
45、Hive存储的三种格式:
TextFile:不压缩,磁盘开销大;
SequenceFile:使用方便、可分割、可压缩、并发读取,但是占用空间比较大;
RCFile:压缩,但是加载时消耗大。
46、HiveSQL的join实现过程:
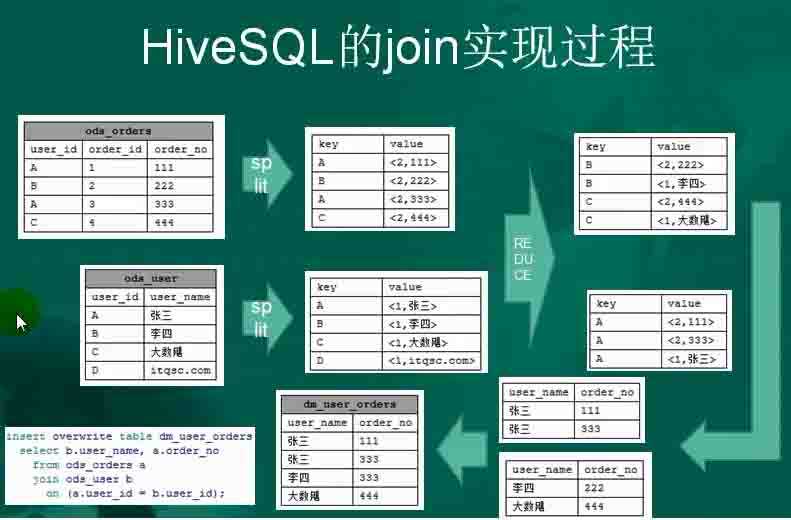
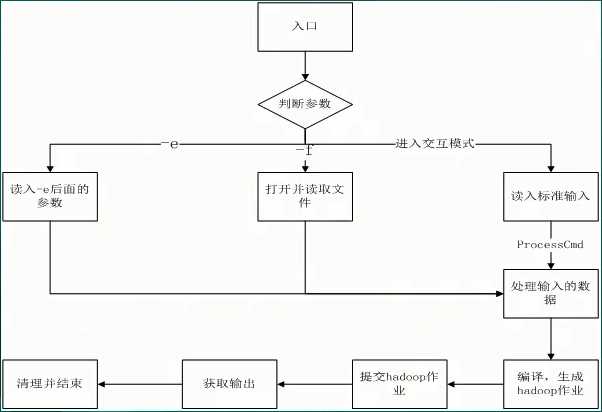
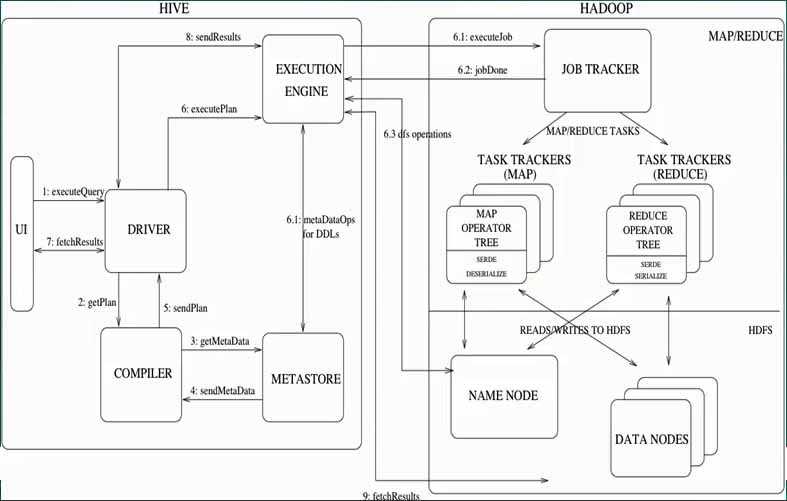
47、Hive的执行生命周期
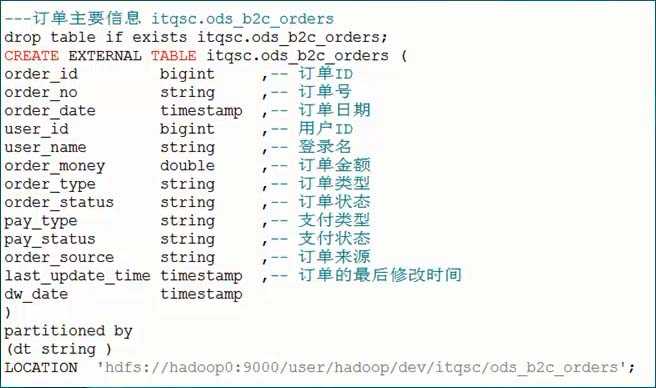
48、举例:订单端口模块
49、HiveSQL实战
将下面脚本创建成.sh文件,直接调用即可。
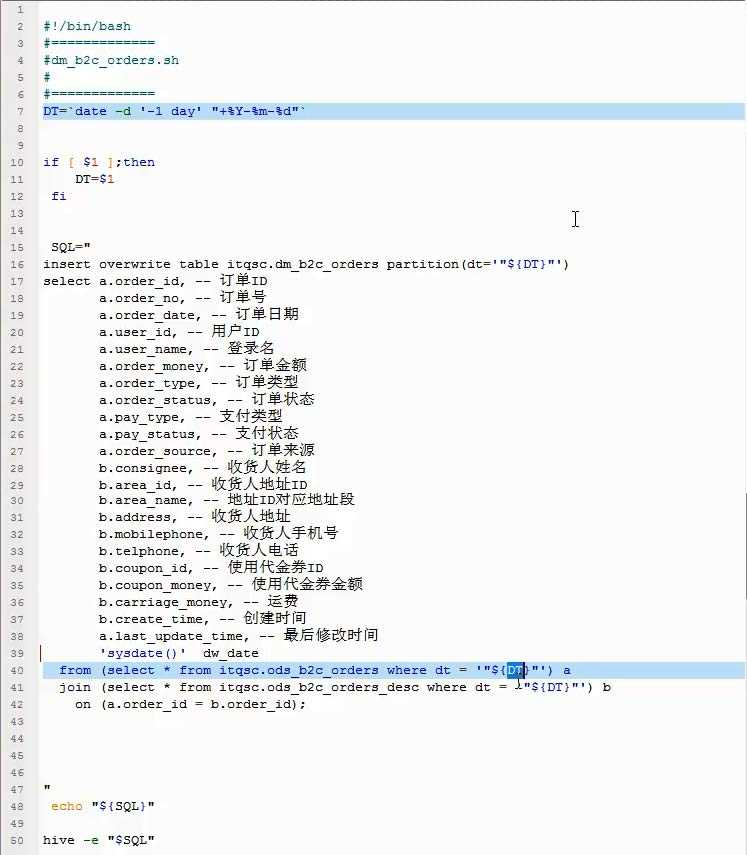
50、HiveSQL实战2
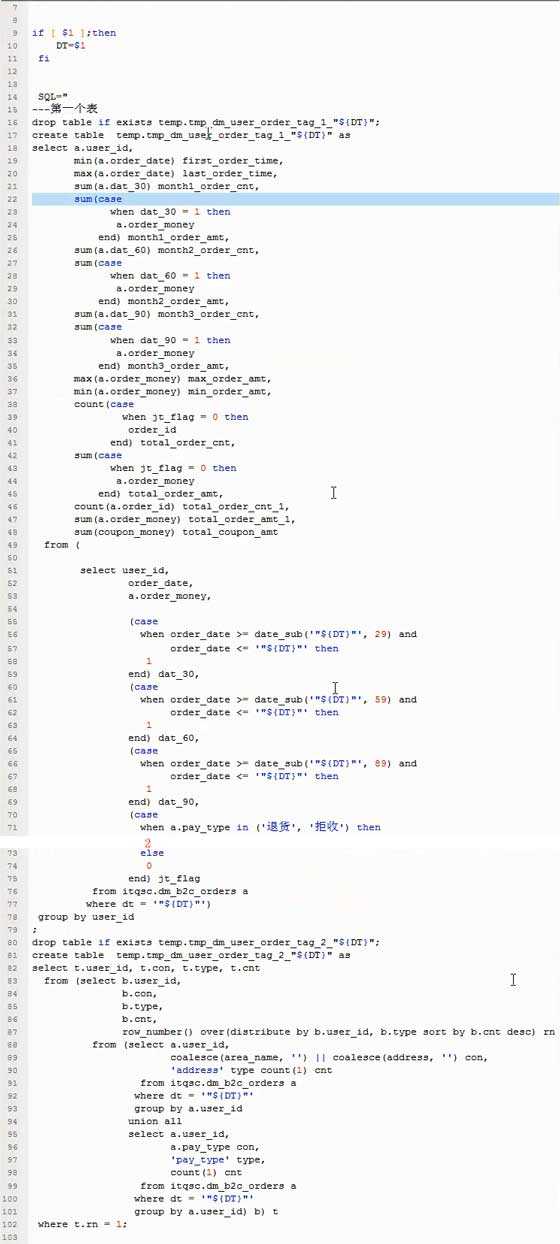
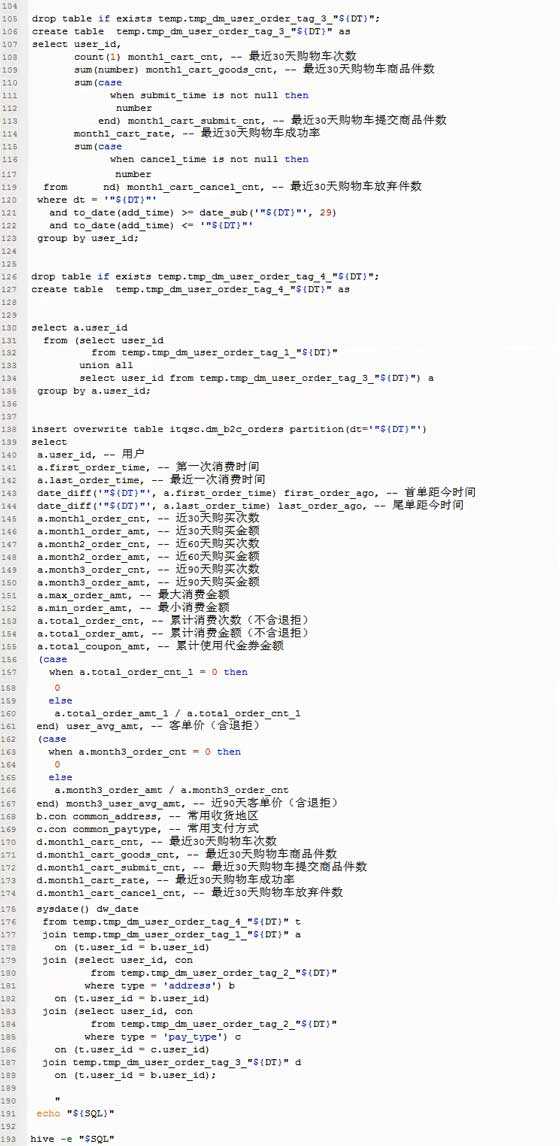
标签:
原文地址:http://www.cnblogs.com/hunttown/p/5452660.html