径向基函数(RBF)神经网络
RBF网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度,已成功应用于非线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
简单说明一下为什么RBF网络学习收敛得比较快。当网络的一个或多个可调参数(权值或阈值)对任何一个输出都有影响时,这样的网络称为全局逼近网络。由于对于每次输入,网络上的每一个权值都要调整,从而导致全局逼近网络的学习速度很慢。BP网络就是一个典型的例子。
如果对于输入空间的某个局部区域只有少数几个连接权值影响输出,则该网络称为局部逼近网络。常见的局部逼近网络有RBF网络、小脑模型(CMAC)网络、B样条网络等。
径向基函数解决插值问题
完全内插法要求插值函数经过每个样本点,即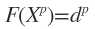 。样本点总共有P个。
。样本点总共有P个。
RBF的方法是要选择P个基函数,每个基函数对应一个训练数据,各基函数形式为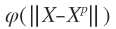 ,由于距离是径向同性的,因此称为径向基函数。||X-Xp||表示差向量的模,或者叫2范数。
,由于距离是径向同性的,因此称为径向基函数。||X-Xp||表示差向量的模,或者叫2范数。
基于为径向基函数的插值函数为:
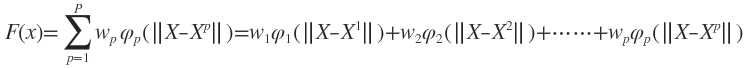
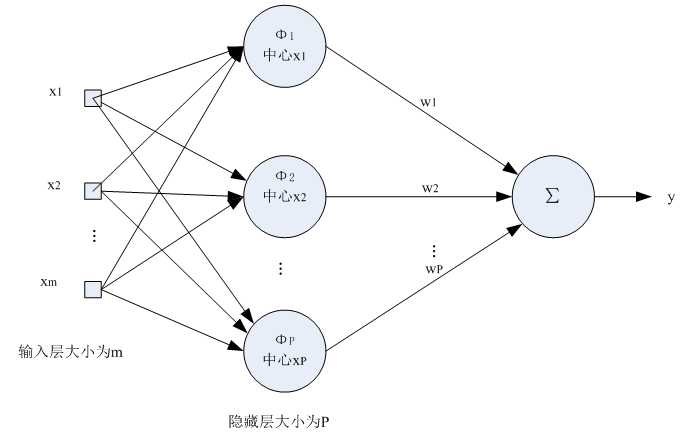
输入X是个m维的向量,样本容量为P,P>m。可以看到输入数据点Xp是径向基函数φp的中心。
隐藏层的作用是把向量从低维m映射到高维P,低维线性不可分的情况到高维就线性可分了。
将插值条件代入:
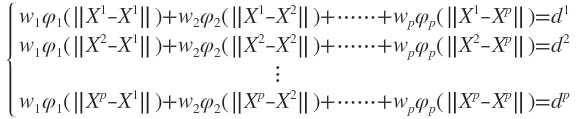
写成向量的形式为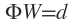 ,显然Φ是个规模这P对称矩阵,且与X的维度无关,当Φ可逆时,有
,显然Φ是个规模这P对称矩阵,且与X的维度无关,当Φ可逆时,有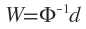 。
。
对于一大类函数,当输入的X各不相同时,Φ就是可逆的。下面的几个函数就属于这“一大类”函数:
1)Gauss(高斯)函数
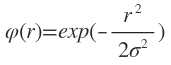
2)Reflected Sigmoidal(反常S型)函数
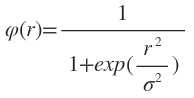
3)Inverse multiquadrics(拟多二次)函数
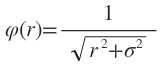
σ称为径向基函数的扩展常数,它反应了函数图像的宽度,σ越小,宽度越窄,函数越具有选择性。
完全内插存在一些问题:
1)插值曲面必须经过所有样本点,当样本中包含噪声时,神经网络将拟合出一个错误的曲面,从而使泛化能力下降。
由于输入样本中包含噪声,所以我们可以设计隐藏层大小为K,K<P,从样本中选取K个(假设不包含噪声)作为Φ函数的中心。
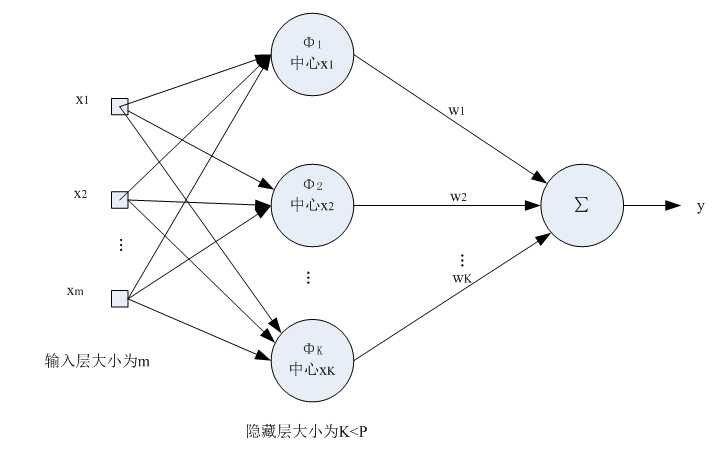
2)基函数个数等于训练样本数目,当训练样本数远远大于物理过程中固有的自由度时,问题就称为超定的,插值矩阵求逆时可能导致不稳定。
拟合函数F的重建问题满足以下3个条件时,称问题为适定的:
- 解的存在性
- 解的唯一性
- 解的连续性
不适定问题大量存在,为解决这个问题,就引入了正则化理论。
正则化理论
正则化的基本思想是通过加入一个含有解的先验知识的约束来控制映射函数的光滑性,这样相似的输入就对应着相似的输出。
寻找逼近函数F(x)通过最小化下面的目标函数来实现:
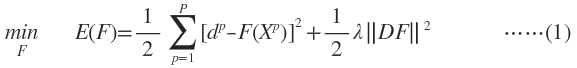
加式的第一项好理解,这是均方误差,寻找最优的逼近函数,自然要使均方误差最小。第二项是用来控制逼近函数光滑程度的,称为正则化项,λ是正则化参数,D是一个线性微分算子,代表了对F(x)的先验知识。曲率过大(光滑度过低)的F(x)通常具有较大的||DF||值,因此将受到较大的惩罚。
直接给出(1)式的解:
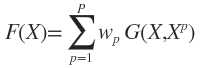
权向量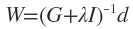 ********************************(2)
********************************(2)
G(X,Xp)称为Green函数,G称为Green矩阵。Green函数与算子D的形式有关,当D具有旋转不变性和平移不变性时,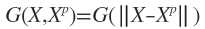 。这类Green函数的一个重要例子是多元Gauss函数:
。这类Green函数的一个重要例子是多元Gauss函数:
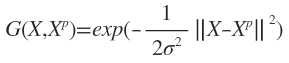 。
。
正则化RBF网络
输入样本有P个时,隐藏层神经元数目为P,且第p个神经元采用的变换函数为G(X,Xp),它们相同的扩展常数σ。输出层神经元直接把净输入作为输出。输入层到隐藏层的权值全设为1,隐藏层到输出层的权值是需要训练得到的:逐一输入所有的样本,计算隐藏层上所有的Green函数,根据(2)式计算权值。
广义RBF网络
Cover定理指出:将复杂的模式分类问题非线性地映射到高维空间将比投影到低维空间更可能线性可分。
广义RBF网络:从输入层到隐藏层相当于是把低维空间的数据映射到高维空间,输入层细胞个数为样本的维度,所以隐藏层细胞个数一定要比输入层细胞个数多。从隐藏层到输出层是对高维空间的数据进行线性分类的过程,可以采用单层感知器常用的那些学习规则,参见神经网络基础和感知器。
注意广义RBF网络只要求隐藏层神经元个数大于输入层神经元个数,并没有要求等于输入样本个数,实际上它比样本数目要少得多。因为在标准RBF网络中,当样本数目很大时,就需要很多基函数,权值矩阵就会很大,计算复杂且容易产生病态问题。另外广RBF网与传统RBF网相比,还有以下不同:
- 径向基函数的中心不再限制在输入数据点上,而由训练算法确定。
- 各径向基函数的扩展常数不再统一,而由训练算法确定。
- 输出函数的线性变换中包含阈值参数,用于补偿基函数在样本集上的平均值与目标值之间的差别。
因此广义RBF网络的设计包括:
结构设计--隐藏层含有几个节点合适
参数设计--各基函数的数据中心及扩展常数、输出节点的权值。
下面给出计算数据中心的两种方法:
- 数据中心从样本中选取。样本密集的地方多采集一些。各基函数采用统一的偏扩展常数:
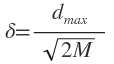
dmax是所选数据中心之间的最大距离,M是数据中心的个数。扩展常数这么计算是为了避免径向基函数太尖或太平。 - 自组织选择法,比如对样本进行聚类、梯度训练法、资源分配网络等。各聚类中心确定以后,根据各中心之间的距离确定对应径向基函数的扩展常数。
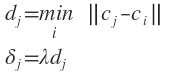
λ是重叠系数。
接下来求权值W时就不能再用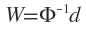 了,因为对于广义RBF网络,其行数大于列数,此时可以求Φ伪逆。
了,因为对于广义RBF网络,其行数大于列数,此时可以求Φ伪逆。
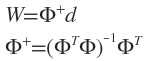
数据中心的监督学习算法
最一般的情况,RBF函数中心、扩展常数、输出权值都应该采用监督学习算法进行训练,经历一个误差修正学习的过程,与BP网络的学习原理一样。同样采用梯度下降法,定义目标函数为
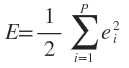
ei为输入第i个样本时的误差信号。
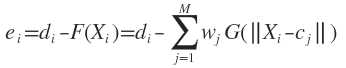
上式的输出函数中忽略了阈值。
为使目标函数最小化,各参数的修正量应与其负梯度成正比,即
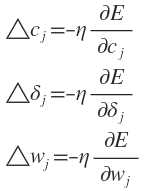
具体计算式为
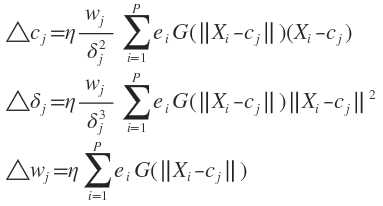
上述目标函数是所有训练样本引起的误差总和,导出的参数修正公式是一种批处理式调整,即所有样本输入一轮后调整一次。目标函数也可以为瞬时值形式,即当前输入引起的误差
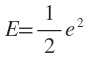
此时参数的修正值为:
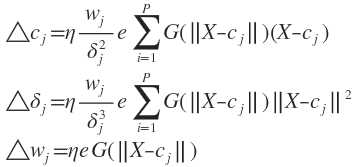
下面我们就分别用本文最后提到的聚类的方法和数据中心的监督学习方法做一道练习题。
考虑Hermit多项式的逼近问题
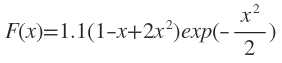
训练样本这样产生:样本数P=100,xi且服从[-4,4]上的均匀分布,样本输出为F(xi)+ei,ei为添加的噪声,服从均值为0,标准差为0.1的正态分布。
(1)用聚类方法求数据中心和扩展常数,输出权值和阈值用伪逆法求解。隐藏节点数M=10,隐藏节点重叠系数λ=1,初始聚类中心取前10个训练样本。
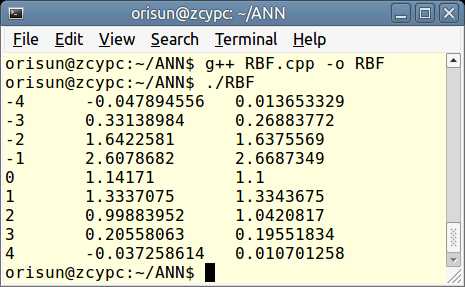
(2)用梯度下降法训练RBF网络,设η=0.001,M=10,初始权值为[-0.1,0.1]内的随机数,初始数据中心为[-4,4]内的随机数,初始扩展常数取[0.1,0.3]内的随机数,目标误差为0.9,最大训练次数为5000。
标签:
原文地址:http://www.cnblogs.com/xss1993/p/5460517.html