标签:style blog http color 使用 strong 数据 2014
前言
本文从使用 GPU 编程技术的角度来了解计算中并行实现的方法思路。
并行计算中需要考虑的三个重要问题
1. 同步问题
在操作系统原理的相关课程中我们学习过进程间的死锁问题,以及由于资源共享带来的临界资源问题等,这里不做累述。
2. 并发度
有一些问题属于 “易并行” 问题:如矩阵乘法。在这类型问题中,各个运算单元输出的结果是相互独立的,这类问题能够得到很轻松的解决 (通常甚至调用几个类库就能搞定问题)。
然而,若各个运算单元之间有依赖关系,那问题就复杂了。在 CUDA 中,块内的通信通过共享内存来实现,而块间的通信,则只能通过全局内存。
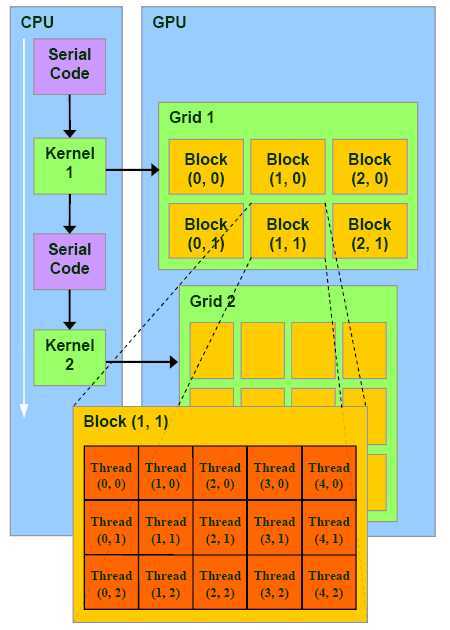
CUDA 并行编程架构可以用网格 (GRID) 来形容:一个网格好比一只军队。网格被分成好多个块,这些块好比军队的每个部门 (后勤部,指挥部,通信部等)。每个块又分成好多个线程束,这些线程束好比部门内部的小分队,下图可帮助理解:
3. 局部性
在操作系统原理中,对局部性做过重点介绍,简单来说就是将之前访问过的数据 (时间局部性) 和之前访问过的数据的附近数据 (空间局部性) 保存在缓存中。
在 GPU 编程中,局部性也是非常重要的,这体现在要计算的数据应当在计算之前尽可能的一次性的送进显存,在迭代的过程中一定要尽可能减少数据在内存和显存之间的传输,实际项目中发现这点十分重要的。
对于 GPU 编程来说,需要程序猿自己去管理内存,或者换句话来说,自己实现局部性。
并行计算的两种类型
1. 基于任务的并行处理
这种并行模式将计算任务拆分成若干个小的但不同的任务,如有的运算单元负责取数,有的运算单元负责计算,有的负责... ... 这样一个大的任务可以组成一道流水线。
需要注意的是流水线的效率瓶颈在于其中效率最低的那个计算单元。
2. 基于数据的并行处理
这种并行模式将数据分解为多个部分,让多个运算单元分别去计算这些小块的数据,最后再将其汇总起来。
一般来说,CPU 的多线程编程偏向于第一种并行模式,GPU 并行编程模式则偏向于第二种。
常见的并行优化对象
1. 循环
这也是最常见的一种模式,让每个线程处理循环中的一个或一组数据。
这种类型的优化一定要小心各个运算单元,以及每个运算单元何其自身上一次迭代结果的依赖性。
2. 派生/汇集模式
该模式下大多数是串行代码,但代码中的某一段可以并行处理。
典型的情况就是某个输入队列当串行处理到某个时刻,需要对其中不同部分进行不同处理,这样就可以划分成多个计算单元对改队列进行处理 (也即派生),最后再将其汇总 (也即汇集)。
这种模式常用于并发事件事先不定的情况,具有 “动态并行性”。
3. 分条/分块模式
对于特别庞大的数据 (如气候模型),可以将数据分为过个块来进行并行计算。
4. 分而治之
绝大多数的递归算法,比如快速排序,都可以转换为迭代模型,而迭代模型又能映射到 GPU 编程模型上。
特别要说明的是,虽然费米架构和开普勒架构的 GPU 都支持缓冲栈,能够直接实现递归模型到 GPU 并行模型的转换。但为了程序的效率,在开发时间允许的情况下,我们最好还是先将其转换为迭代模型。
二 从 GPU 的角度理解并行计算,布布扣,bubuko.com
标签:style blog http color 使用 strong 数据 2014
原文地址:http://www.cnblogs.com/scut-fm/p/3879446.html