标签:
一,Control Flow
在Control Flow中,Task是最小的单元,Task通过Precedence Constraint来保持同步。
1,Control Flow 不能在组件之间传递数据,用于串行或并行执行任务,担当Task的调度者。
如果两个Task之间没有设置precedence constraint,那么这两个Task是并发执行的。在design package时,最大限度地提高task的并发处理能力,能够充分利用server的资源,有助于减少ETL执行的时间。
2,Control Flow 通过Precedence Constraint保持同步
在Task之间设置Precedence Constraint,只有在上游Task执行完成之后,才会执行下游Task;在上游Task执行完成之前,下游Task不会执行。
二,Data Flow
Data Flow 由三部分组成:源,转换和目的,用于处理数据,对数据进行转移(源提取数据和目标加载数据)和转换。
数据流具有流的特性,数据以流的形式并发处理,数据不是一次性全部加载,而是划分为不重复的多个部分,组成一个流,源源不断地从上游组件流向下游组件。在数据流动的过程中,Data Flow的所有组件同时对Data进行处理。上游组件处理完一批Data之后,交接给下游组件继续处理,同时,上游组件继续处理下一批数据。数据在组件之间流动,各个组件同时处理数据的不同部分,直到全部数据处理完成。
Data Flow具有反馈和自动调节的功能,如果下游组件的处理速度存在压力,那么SSIS将会向上游施加反向压力,自动调节,使上游的数据流动速度减缓。
1,内存缓存区结构
数据流使用内存暂时存储数据源中的数据,这意味着,将数据从源提取到SSIS Engine时,Data会存储在预先分配好的内存缓存中,可以根据data row的宽度(一个row中所有column的字节数),设置DefaultBufferMaxRows属性来调整缓冲区的大小,或直接设置DefaultBufferSize属性。
Data Flow Task的属性
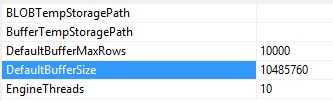


SSIS Engine根据Server的资源和压力,会预先分配一组缓冲区,每一个缓冲区存储完整数据集的一个不重复子集。当对数据流进行转换时,SSIS Engine 后台使用一种更为有效的方式:对同一个缓冲区,逐个应用转换组件的业务逻辑,这比将更改后的数据复制到另一个缓冲区,然后应用转换组件的业务逻辑更为有效。不过,有些情况下,SSIS Engine需要复制缓冲区,甚至需要拦截数据流,对整个数据集进行数据转换,例如,聚合和排序。
2,转换的阻塞性:非阻塞(流),半阻塞和阻塞
大多数转换都是流性的,这意味着在转换逻辑应用到某一行时,不会阻止数据移动到下一个转换。
3,转换的同步和异步输出
每一种转换都有输入和输出,如果输入所使用的缓冲区和输出所使用的缓冲区不一样,那么转换的输出就是异步的,换句话说,许多转换不能够既执行指定操作又维护缓存区(行数或者行的顺序),所以必须复制数据,以实现所期望的结果。
在转换组件的Advanced Editor中,每个column存在一个LineageID属性,这是一个指向缓冲区的指针,标识该列在缓冲区中的位置。
Specifies the lineage ID of the output column when this item was first placed in the data flow.
三,异步转换输出示例
异步转换输出是指,转换的输入缓冲区和输出缓冲区不同。
1,Data Flow
2,Data Source组件
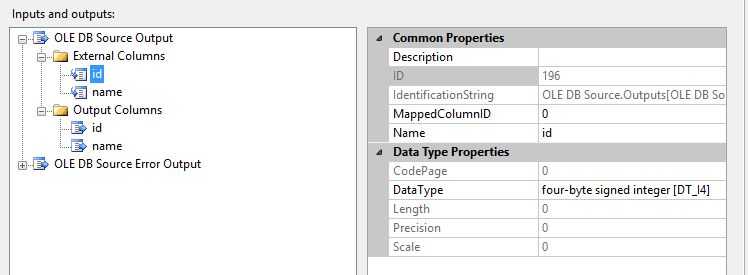
Data Source 具有External columns和 output columns。
External columns直接来源于数据源,Data Source 组件创建缓冲区,将数据复制到缓冲区中,分配LineageID,这个缓冲区就是Data Source 组件的输出。
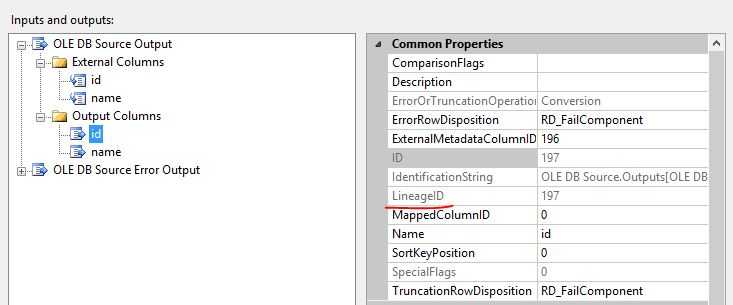
3,Sort 组件
Sort组件的Input Columns,ID 列的LineageID是197,和Data Source 输出缓冲区中ID 列的LineageID属性相同,这说明,Sort 转换直接使用Data Source的输出缓冲区。
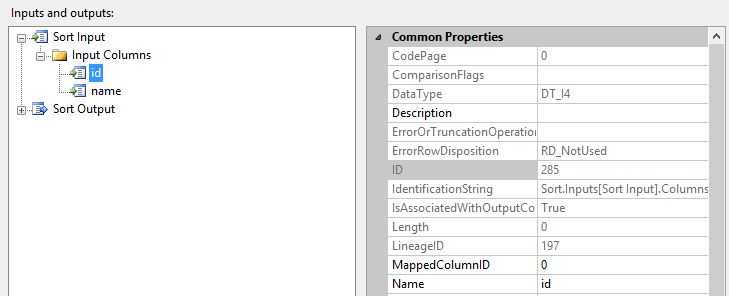
Sort 转的输出,ID列的LineageID属性值是 288。相同的列之所以存在不同的LineageID值,是因为Sort转换的输出是异步的,输入缓冲区和输出缓冲区不同,因此输出需要一个新的列标识符。
SortColumnID属性值是197,是输出列的源列。SortColumnID属性 Specifies the lineage identifier of the input column that is associated with this output column。
所有具有半阻塞性和阻塞性的转换都是异步输出的,这些转换不会直接向下游传递输入缓冲区,因为需要拦截数据以进行处理和重组。
四,同步转换输出示例
属性IdentificationString用于标识组件的数据流,其值是有特定格式的字符串,例如: Conditional Split.Inputs[conditional Split input]
属性SynchronousInPutID 用于标识组件的输出流的IdentificationString,如果组件的属性SynchronousInPutID为None,说明组件会创建新的输出流,转换输出是异步的,如果组件的属性SynchronousInPutID 是一个IdentificationString,说明组件的输出和输入使用相同的缓冲区。
1,Data Flow
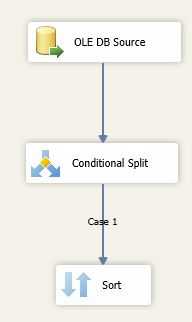
2,Conditional Split组件
查看Conditional Split组件的输出,发现case1 没有Output Columns
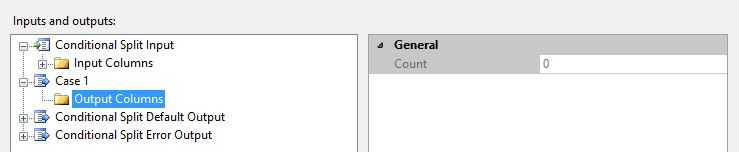
点击Case1,查看属性SynchronousInPutID,值是Conditional Split.Inputs[conditional Split input]。
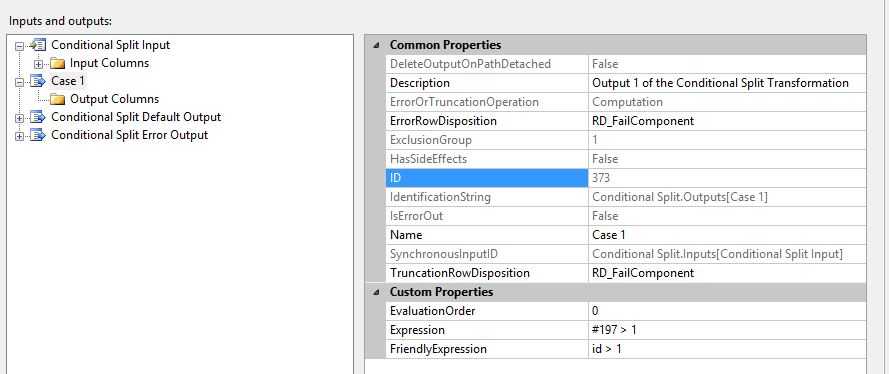
查看 Conditional Split的 输入流,查看属性IdentificationString的值,和组件的输出流Case1的SynchronousInPutID属性值相同。
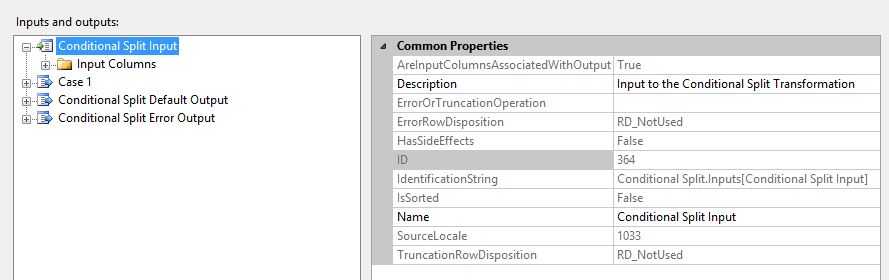
3,验证LineageID值
查看Sort组件的Input Columns,ID的LineageID是 197,和DataSource组件的输出流,Conditional Split的输入流都相同,说明Conditional Split没有创建新的数据缓冲区,使用的是Data source 创建的缓冲区来进行数据转换。
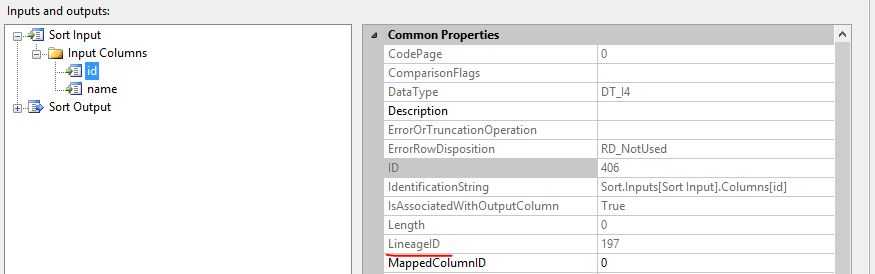
结论:在同步转换输出中,当完成了转换逻辑之后,会立即将缓冲区传递到下游的转换,即转换输入和转换输出使用相同的缓冲区,避免复制缓冲区到输出,因此相同列的LineageID是相同的。
五, 识别转换的异步性
通过Advanced Editor,查看Output的SynchronousInPutID属性,Specifies the input ID of rows in this output
如果SynchronousInPutID属性值为None,那么该组件输出是异步的,如果该值不是None,而是IdentificationString 格式的字符串,那么该转换输出是同步的。
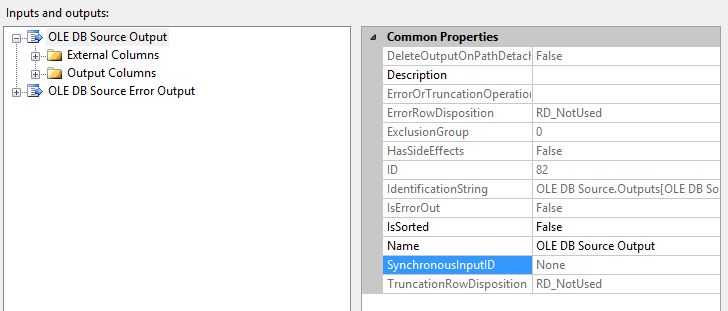
六,数据流缓冲区的申请和释放
Data source 组件会创建新的缓冲区,并为响应的Column分配LineageID值。当缓冲区数据被加载到destination之后,destination会释放缓冲区。
SSIS的 Data Flow 和 Control Flow
标签:
原文地址:http://www.cnblogs.com/ljhdo/p/5465236.html