标签:
Curriculum Learning of Multiple Tasks
CVPR 2015
对于多任务的学习(Multi-Task Learning)像是属性识别等任务,之前都是每一个属性训练一个分类器,后来有了深度学习,大家都用共享卷积层的方式来联合的学习(Joint Learning)。让网络去学习各个任务或者说各个属性之间潜在的联系,最后对其进行分类,或者逻辑回归。本文对这种做法提出了其诟病,说是:多个task之间的相互关系并不相同,有的有关系 有的关系很弱或者基本不相关等等。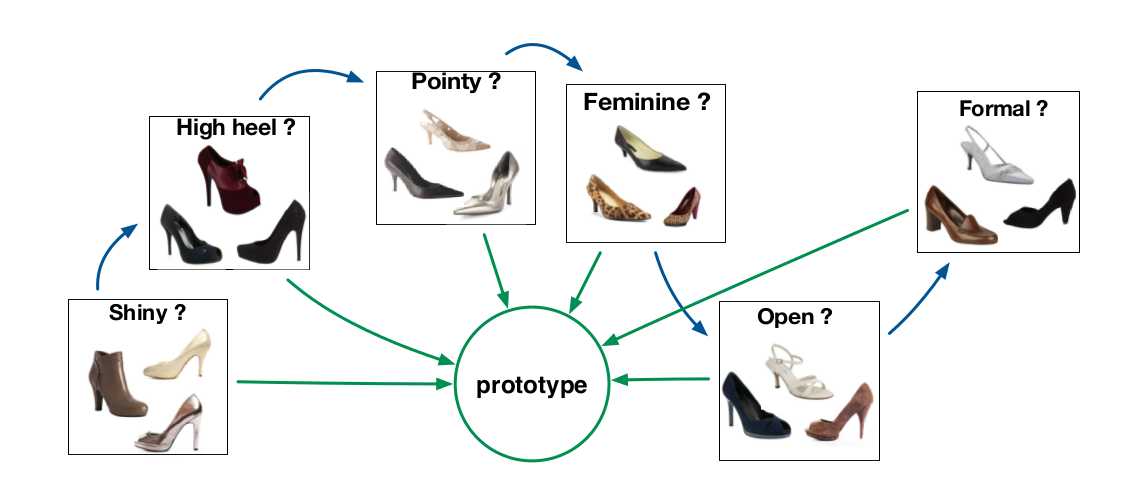 如上图所示,给出了两种pipeline,一种是绿色箭头所示的那样,所有的学习任务都被建模成相关的,这种相关性主要基于信息共享(Sharing Information);另一种,是本文提出的先学习某一任务,再在此基础之上,去学习其他的任务,按照这种相关性最终完成所有的task learning。本文focus在参数转移方法,该方法基于这样的idea:models corresponding to related tasks are similar to each other in terms of their parameter representations. 即:对应相关任务的模型根据他们的参数表示来说都是相似的。本文的一个假设是:模型之间的相似性可以通过对应的参数向量之间的欧式距离来度量。本文所提出的方法可以看做是将 multi-task problem 分解为一系列的 domain adaptation problems 。
如上图所示,给出了两种pipeline,一种是绿色箭头所示的那样,所有的学习任务都被建模成相关的,这种相关性主要基于信息共享(Sharing Information);另一种,是本文提出的先学习某一任务,再在此基础之上,去学习其他的任务,按照这种相关性最终完成所有的task learning。本文focus在参数转移方法,该方法基于这样的idea:models corresponding to related tasks are similar to each other in terms of their parameter representations. 即:对应相关任务的模型根据他们的参数表示来说都是相似的。本文的一个假设是:模型之间的相似性可以通过对应的参数向量之间的欧式距离来度量。本文所提出的方法可以看做是将 multi-task problem 分解为一系列的 domain adaptation problems 。
当然了这里也有吹水啦,如:本文是受到人类教育过程的启发,将在校的学生看做是一个多任务的学习机,假设要学习很多的课程。但是并非一次性全部学习完毕,而是按照一定的序列,依次进行,按照一定的有意义的序列,该学生就可以逐渐的增加他们的只是,并且将之前学到的东西,用于后面更加有效的进行课程学习。
学习课程的次序严重影响最终的表现,本文用 PAC-Bayesian theory 来证明依赖于数据表示和算法的一个总的边界(a genetalization bound)来解决这个任务。基于这个bound,本文提出了一个理论上可证明的算法自动的选择一个较好的序列进行学习。本文的实验证明按照自动学习到的序列,可以获得比单独训练或者联合训练都要好的结果。
看到这里,大伙是不是迫不及待了?Come On !
假设我们有n个任务,分别为 t1 t2 t3 ... tn,共享相同的输入和输出空间。每一个任务 ti 定位对应的集合Si,有mi个采样的训练点。我们也假设为了解决每一个任务,学习者用一个线性估计 f(x) = sign<w, x>,w是一个权重向量,通过 0/1 loss 衡量分类的性能。学习者的目标是为了找到n个权重向量 w1 w2 ... wn 使得任务t1 t2 t3 ...tn的平均期望误差最小:
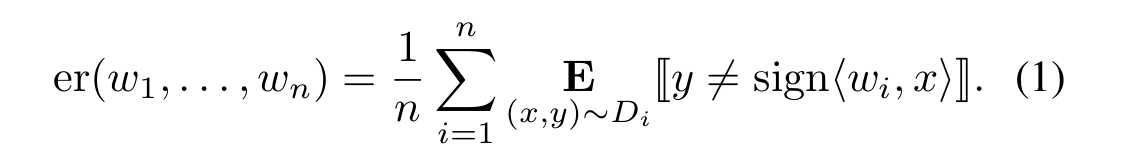
1. Learning in a fixed order.
本节就是用Adaptive SVM来学习每一个任务,并且将之前的任务用于下一个任务的学习,给定一个权重向量和一个任务的训练数据,Adaptive SVM执行下列的优化:
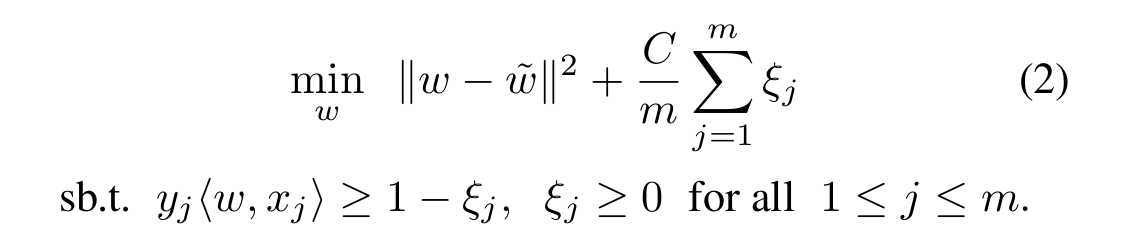
上式中带波浪线的w表示的是上一个任务的权重向量。
2. Learning a data-dependent order.
这里我们根据结果的平均期望误差(the average expected error)检查序列 pi 的作用,我们假设:用来解决单独任务 t 的学习算法对于所有任务来说都是一样的而且是确定的。算法基于上一个解决的任务得到的解 和 训练数据S,返回对应的权重向量 W。紧接着的理论提供了平均期望误差的上线:

论文笔记之:Curriculum Learning of Multiple Tasks
标签:
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/5466574.html