标签:
对话模型此前的研究大致有三个方向:基于规则、基于信息检索、基于机器翻译。基于规则的对话系统,顾名思义,依赖于人们周密设计的规则,对话内容限制在特定领域下,实际应用如智能客服,智能场馆预定系统。基于信息检索是指根据输入语句,在回复候选集中匹配最相近的语句作为回复,涉及到特征与排序算法的选择。优点是得到的回复通常语法正确、语义明确,但由于回复是事先存在的,因此不能很好的适应语境。还有一种思路源自机器翻译,使用神经网络encode-decode框架:将输入语句映射为向量,根据向量生成回复。需要注意的是,对话生成与机器翻译有明显不同的地方:机器翻译要求输入与输出的语义完全一致,但在对话中需要有话题深入等语义偏移的情况。
这里总结的4篇文章均基于机器翻译的思路,使用神经网络为对话生成建模。第一篇文章是最典型的encode-decode结构;第二篇文章在decode网络输入部分做了修改,建模“回复中的词语各侧重于上下文不同部分”这一情况;第三篇文章在encode网络处做了修改,没有使用与decode部分同类的网络,输入也换成了context与message的bag-of-word,直观理解,更偏向于对输入语句主题的提炼挖掘。第四篇文章修改了decode网络的目标函数,意图使系统生成更丰富的回答,而不是一些通用于各种语境的无效回复,如”I don’t know”。
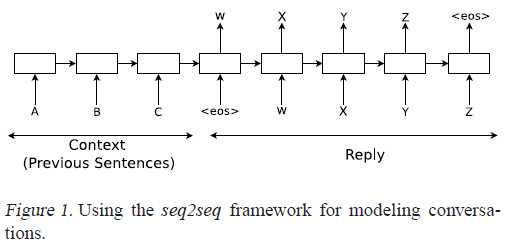
purely data driven approach without rules,采用了seq2seq框架,使用两个LSTM,分别:将输入语句映射为固定长度的向量,根据向量预测对话中的下一句话。在特定主题的数据集IT helpdesk troubleshooting和无特定主题的电影对白数据集OpenSubtitles上进行了实验,可以回答某些简单问题,但是与其他对话系统一样,存在前后话题一致性的问题。
Overview:
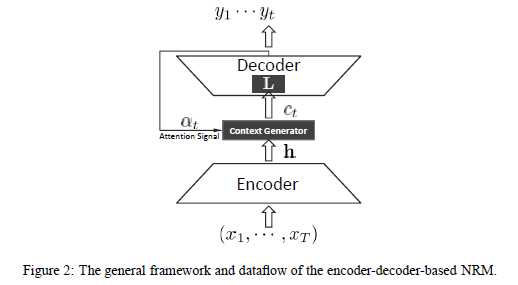
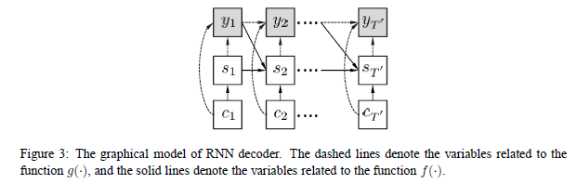
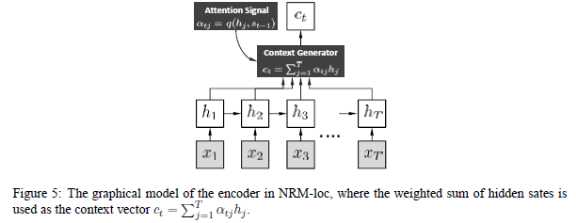
同样采用了seq2seq框架,使用的是两个RNN:从输入语句中习得潜在语义(encode),然后根据潜在语义生成应答语句(decode)。这篇论文创新之处在于decode网络输入变量的构造上——往常的seq2seq模型是将encode网络的最后一个隐状态作为decode网络各个时刻的输入;但在这里,是将encode网络各个时刻的隐状态加权之后,作为decode网络不同时刻的输入。不同时刻下,decode网络中的输入不同,因为对encode隐状态使用的权值不同。直观的理解是,对于decode网络将生成的新词,它对应的是上下文信息中的某一部分,而不是整个上下文信息,因此使用权重来加强对应的部分。这种思路最初见于《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》,并且在其中提到了权重的计算方法:需要计算此时decode网络的前一个隐状态和的encode网络各隐状态的“对齐”情况,单独使用一个神经网络训练完成的。文中取的最好效果的模型还需要在上述方法中加一些改进:输入到decode网络各时刻的变量,由encode网络各时刻隐状态加权结果与encode网络最后时刻隐状态连接而成。
Overview:
Decoder:standard RNN
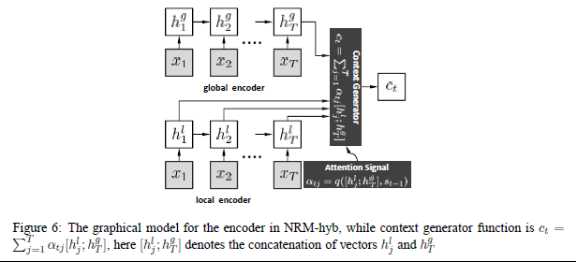
Global scheme
local scheme:
Combine global and local:
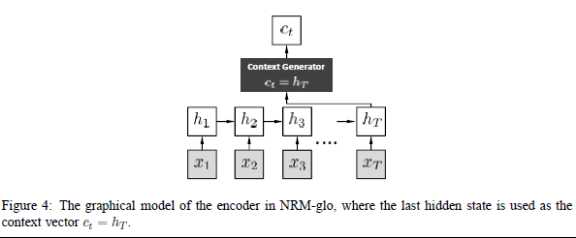
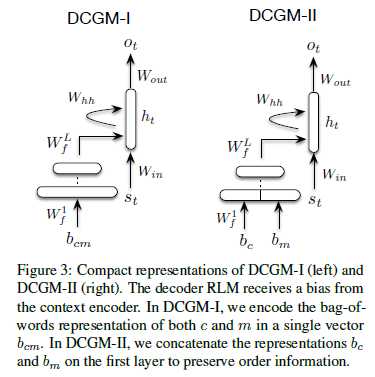
encoder为多层前向网络,decoder为RNN。论文中将对话分为context,message,response。其中,为了保持上下文信息,在encoder的输入为对话中context和message的bag-of-word(文中考虑了context、message词袋合并、分开两种情况),并且encoder网络最后一层的输出向量参与到decoder的每个隐层计算中去。
对话模型倾向于生成一些通用的回答,譬如“I don’t know”,无论前一句是什么都适用。针对这个问题,作者提出了新的decode网络目标函数,希望可以生成多样化的回答。Decode网络通常使用的目标函数是使得输出句子在给定输入时取得最大似然(见公式7),作者提出目标函数应使得输入句与输出句有最大互信息(见公式8),以此来限制通用的、与上下文无关的回答。


作者对公式8进行了两种变形(公式9,公式10),对应着论文中的两种实现思路,推导过程及结果见下图。针对公式9,作者还进一步考虑了:头几个生成的词语对整个输出句子的影响很大,因此对头几个词乘上惩罚系数,鼓励那些概率不那么大的词作为句首,希望借此生成更丰富的回答;鼓励生成更长的句子,但设有上限(20个词)。针对公式10,需要计算给定回复下得到输入句的概率(P(S|T)),这要求先生成回复T,而T搜索空间极为巨大。故作者在实现时先使用P(S|T)求得N-best候选应答,然后在再根据完整的公式10重排,得到最佳应答(近似)。

关于conversation generation的论文笔记
标签:
原文地址:http://www.cnblogs.com/violinist/p/5467556.html