标签:
本文主要讲解Hadoop完全分布式的搭建,使用vm建立三个相同配置的主机进行搭建。本文讲解所有详细步骤希望对大家有用。
集群包括3个节点,1个Namenode、2个Datanode,其中节点之间可以相互ping通。节点IP地址和主机名如下:
序号 | IP地址 | 机器名 | 类型 | 用户名 |
1 | 192.168.1.127 | Master.Hadoop | Namenode | Hadoop |
2 | 192.168.1.128 | Slave1.Hadoop | Datanode | Hadoop |
3 | 192.168.1.129 | Slave2.Hadoop | Datanode | Hadoop |
所有节点均是CentOS系统,防火墙均禁用,所有节点上均创建了一个Hadoop用户,用户主目录是/home/Hadoop。所有节点上均创建了一个目录/usr/hadoop,并且拥有者是hadoop用户。因为该目录用于安装hadoop,用户对其必须有rwx权限。(一般做法是root用户下在/usr下创建hadoop目录,并修改该目录拥有者为hadoop(chown –R Hadoop: /usr/hadoop),否则通过SSH往其他机器分发Hadoop文件会出现权限不足的提示。
由于Hadoop要求所有机器上Hadoop的部署目录结构要求相同(因为在启动时按与主节点相同的目录启动其它任务节点),并且都有一个相同的用户名账户。参考各种文档上说的是所有机器都建立一个hadoop用户,使用这个账户来实现无密码认证。这里为了方便,分别在三台机器上都重新建立一个hadoop用户。
对于Datanode类型的系统,可以先安装一个系统,然后利用VMWare的克隆功能,克隆多个相同的系统。如下图所示。

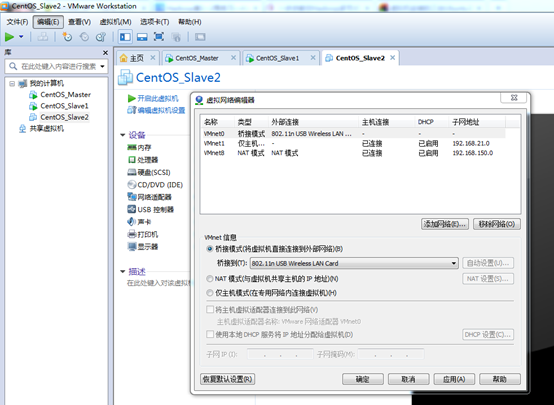
VMWare下安装CentOs系统的教程直接在网上找。特别注意的是:所有系统的网络选择为桥接模式,并且由于本机是在无线网络上进行上网的,故还要设置VMnet0的信息:在编辑->虚拟网络编辑器···如下图:
桥接网络是指本地物理网卡和虚拟网卡通过VMnet0虚拟交换机进行桥接,物理网卡和虚拟网卡在拓扑图上处于同等地位,那么物理网卡和虚拟网卡就相当于处于同一个网段,虚拟交换机就相当于一台现实网络中的交换机,所以两个网卡的IP地址也要设置为同一网段。
在”桥接到”那一栏里选择所用的网卡类型。
采用桥接来连接网络(适合有路由、交换机用户),配置静态IP来实现上网,局域网内通信。
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 #描述网卡对应的设备别名 BOOTPROTO=static #设置网卡获得ip地址的方式,为static HWADDR=”00:23:54:DE:01:69” ONBOOT=”yes” #系统启动时是否设置此网络接口,设置为yes TYPE=”Ethernet” USERCTL=no IPV6INIT=no PEERDNS=yes NETMASK=255.255.255.0 #网卡对应的网络掩码 IPADDR=192.168.1.127 #只有网卡设置成static时,才需要此字段 GATEWAY=192.168.1.1 #设置为路由器地址,一般都是这个 DNS1=202.112.17.33 #设置为本网络对应的,或者8.8.8.8 #google域名服务器 |
本次操作的配置图如下所示:

(可以直接在Master机上设置好,然后通过scp命令将该文件传递给所有的Slave,然后在Slave中修改相应的IPADDR即可,其它不变)
注意:这里需要注意还要改一个东西,因为scp过去的硬件地址是一样的必须修改下:
第一:修改vim /etc//etc/udev/rules.d/ 70-persistent-net.rules
将其中的名为eth0的网卡删掉。同时将eth1的网卡名修改为eth0
第二:修改vim /etc/sysconfig/network-scripts/ifcfg-eth0
将HWADDR修改为刚刚看见的eth1的地址。
“/etc/hosts”这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名对应的IP地址。
在进行Hadoop集群配置中,需要在”/etc/hosts”文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。
所以在所有的机器上的”/etc/hosts”文件中都要添加如下内容:
192.168.1.127 Master.Hadoop
192.168.1.128 Slave1.Hadoop
192.168.1.129 Slave2.Hadoop

(同样,可以直接在Master机上设置好,然后通过scp命令将该文件传递给所有的Slave)
在Hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常。
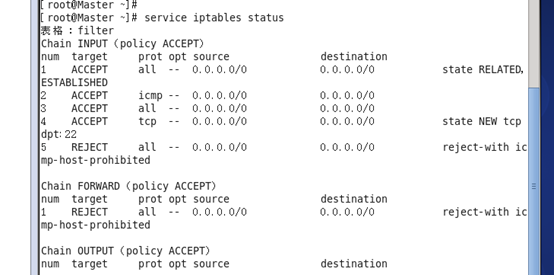

注意:修改后要重启系统,才能有效。
准备工作:
1. 在三个虚拟机上设定Hadoop用户:
adduser Hadoop #在root用户下
passwd Hadoop #输入两次密码
2. 在Hadoop用户下建立.ssh文件夹
mkdir ~/.ssh
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到 NameNode。
SSH之所以能够保证安全,原因在于它采用了公钥加密。过程如下:
(1)远程主机收到用户的登录请求,把自己的公钥发给用户。
(2)用户使用这个公钥,将登录密码加密后,发送回来。
(3)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
注意:如果你的Linux没有安装SSH,请首先安装SSH。
ssh-keygen –t rsa –P ”

运行后询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa(私钥)和id_rsa.pub(公钥),默认存储在”/home/用户名/.ssh”目录下。
查看“/home/用户名/”下是否有“.ssh”文件夹,且“.ssh”文件下是否有两个刚生产的无密码密钥对。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

查看”.ssh”文件夹:

查看下authorized_keys的权限。(很重要!)
如果权限不对则利用如下命令设置该文件的权限:
chmod 700 ~/.ssh #注意:这两条权限设置特别重要,决定成败。
chmod 600 ~/.ssh/authorized_keys
在Master机器上输入:ssh localhost 命令测试一下,看是否能无密码登录自己。
在Master中将公钥id_rsa.pub通过scp命令发到每一个Slave的同一个地方(即/home/Hadoop/.ssh文件夹下),并且设置权限(非常重要)
scp ~/.ssh/authorized_keys Hadoop@Slave1.Hadoop:~/.ssh/
scp ~/.ssh/authorized_keys Hadoop@Slave2.Hadoop:~/.ssh/
在Slave中设置权限(root用户下设置):
chown –R Hadoop:Hadoop /home/Hadoop/.ssh
chmod –R 700 /home/Hadoop/.ssh
chmod 600 /home/Hadoop/.ssh/authorized_keys
在Master下输入:
ssh Slave1.Hadoop
若不用密码则表示成功!
重点:设置好权限!!!
以下的软件安装先在Master上安装,全部安装完后,再通过复制到Slave中即可。
所有的机器上都要安装JDK,并且版本要一样。现在就先在Master服务器安装,然后把安装好的文件传递给Slave即可。安装JDK以及配置环境变量,需要以”root”的身份进行。
tar -zxvf jdk-8u25-linux-x64. gz
查看”/usr/java”下面会发现多了一个名为”jdk1.8.0_65”文件夹,说明我们的JDK安装结束,删除安装包即可,进入下一个”配置环境变量”环节。
# set java environment
export JAVA_HOME=/usr/java/ jdk1.8.0_65/
export JRE_HOME=/usr/java/ jdk1.8.0_65/jre
export CLASSPATH=.:
export PATH=
如下图所示:

保存并退出,执行下面命令使其配置立即生效。
source /etc/profile 或 . /etc/profile
重点说明:PATH变量要先把$JAVA_HOME放在第一位置,这样新安装的JDK能作为第一选择,否则,系统还是以原来的JDK为选择。
java –version

cd /usr
tar –xzvf hadoop-1.2.1.tar.gz
mv hadoop-1.2.1 hadoop
chown –R hadoop:hadoop hadoop
rm -rf hadoop-1.2.1.tar.gz
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=
该”hadoop-env.sh”文件位于”/usr/hadoop/conf”目录下。
在文件中修改下面内容:
export JAVA_HOME=/usr/java/ jdk1.8.0_65/
(此处的JAVA_HOME跟之前Java中环境配置的一样)
source hadoop-env.sh
hadoop version

cd /usr/hadoop
mkdir tmp
mkdir hdfs
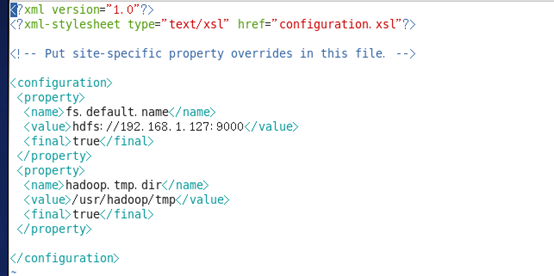
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS master(即namenode)的地址和端口号。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
(备注:请先在 /usr/hadoop 目录下建立 tmp 文件夹)
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.127:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>

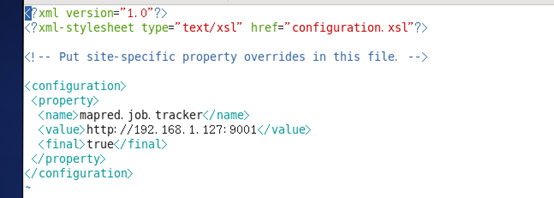
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.1.127:9001</value>
</property>
</configuration>
有两种方案:
(1)第一种
修改localhost为Master.Hadoop
(2)第二种
去掉”localhost”,加入Master机器的IP:192.168.1.127
为保险起见,启用第二种,因为万一忘记配置”/etc/hosts”局域网的DNS失效,这样就会出现意想不到的错误,但是一旦IP配对,网络畅通,就能通过IP找到相应主机。
vim /usr/hadoop/conf/masters
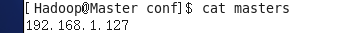
与配置masters文件类似:
vim /usr/hadoop/conf/slaves

在Master上装完JDK以及Hadoop以及配置好环境后,进行下步工作:
在Master中输入:
scp –r /usr/java root@Slave1.Hadoop :/usr/
scp –r /usr/java root@Slave2.Hadoop :/usr/
在Master中输入:
scp /etc/profile root@Slave1.Hadoop :/etc/
scp /etc/profile root@Slave2.Hadoop :/etc/
在Master中输入:
scp –r /usr/hadoop root@Slave1.Hadoop :/usr/
scp –r /usr/hadoop root@Slave2.Hadoop :/usr/
将/usr/java,/usr/hadoop的用户组改为Hadoop用户,设置权限为755。
至此环境搭建完毕
在”Master.Hadoop”上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
hadoop namenode –format
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。使用下面命令启动。
start-all.sh
stop-all.sh
在Master上用 java自带的小工具jps查看进程。
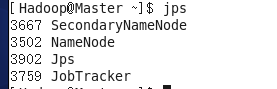
在Slave1上用 java自带的小工具jps查看进程。

注:上两幅图表示成功!

访问JobTracker:http://192.168.1.127:50030
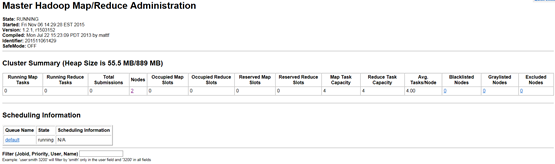
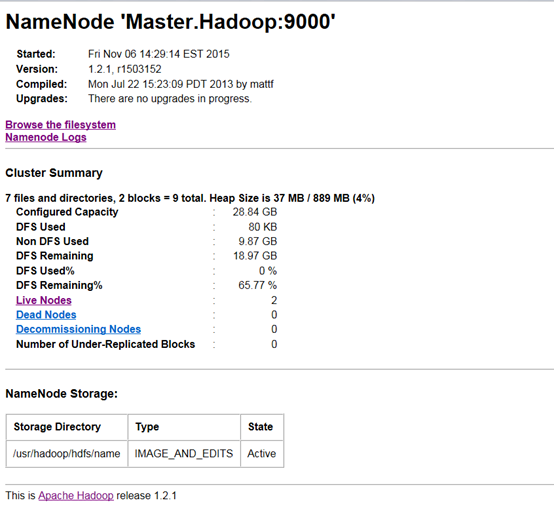
访问NameNode:http://192.168.1.127:50070
hadoop安装完之后敲入hadoop命令时,老是提示这个警告:
Warning: $HADOOP_HOME is deprecated.
解决方案一:编辑”/etc/profile”文件,去掉HADOOP_HOME的变量设定,重新输入hadoop fs命令,警告消失。
解决方案二:编辑”/etc/profile”文件,添加一个环境变量,之后警告消失:
export HADOOP_HOME_WARN_SUPPRESS=1
很有可能是因为权限设置的不对!
有可能是Master和Slave的防火墙没有关掉。
标签:
原文地址:http://blog.csdn.net/peace1213/article/details/51334508