标签:
说明:此方案已经我们已经运行1年。
1、场景描述:
我们对客户登录日志做了数据仓库,但实际业务使用中有一些个共同点,
A 需要关联维度表
B 最终仅取某个产品一段时间内的数据
C 只关注其中极少的字段
基于以上业务,我们决定每天定时统一关联维度表,对关联后的数据进行另外存储。各个业务直接使用关联后的数据进行离线计算。
2、择parquet的外部因素
在各种列存储中,我们最终选择parquet的原因有许多。除了parquet自身的优点,还有以下因素
A、公司当时已经上线spark 集群,而spark天然支持parquet,并为其推荐的存储格式(默认存储为parquet)。
B、hive 支持parquet格式存储,如果以后使用hiveql 进行查询,也完全兼容。
3、选择parquet的内在原因
下面通过对比parquet和csv,说说parquet自身都有哪些优势
csv在hdfs上存储的大小与实际文件大小一样。若考虑副本,则为实际文件大小*副本数目。(若没有压缩)
3.1 parquet采用不同压缩方式的压缩比
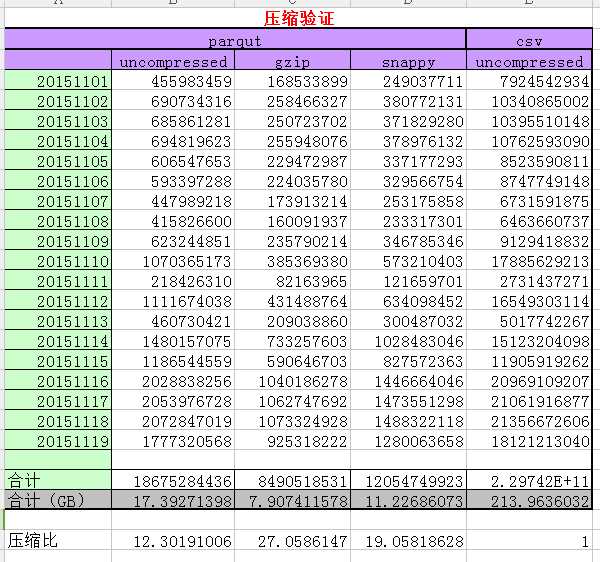
说明:原始日志大小为214G左右,120+字段
采用csv(非压缩模式)几乎没有压缩。
采用parquet 非压缩模式、gzip、snappy格式压缩后分别为17.4G、8.0G、11G,达到的压缩比分别是:12、27、19。
若我们在hdfs上存储3份,压缩比仍达到4、9、6倍
3.2 分区过滤与列修剪
3.2.1分区过滤
parquet结合spark,可以完美的实现支持分区过滤。如,需要某个产品某段时间的数据,则hdfs只取这个文件夹。
spark sql、rdd 等的filter、where关键字均能达到分区过滤的效果。
使用spark的partitionBy 可以实现分区,若传入多个参数,则创建多级分区。第一个字段作为一级分区,第二个字段作为2级分区。。。。。
3.2.2 列修剪
列修剪:其实说简单点就是我们要取回的那些列的数据。
当取得列越少,速度越快。当取所有列的数据时,比如我们的120列数据,这时效率将极低。同时,也就失去了使用parquet的意义。
3.2.3 分区过滤与列修剪测试如下:
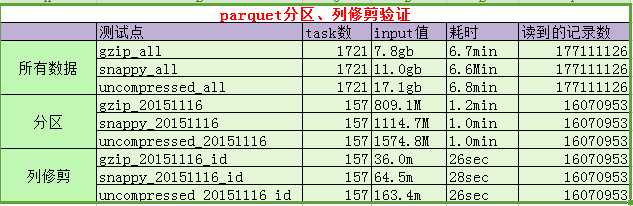
说明:
A、task数、input值、耗时均为spark web ui上的真实数据。
B、之所以没有验证csv进行对比,是因为当200多G,每条记录为120字段时,csv读取一个字段算个count就直接lost excuter了。
C、注意:为避免自动优化,我们直接打印了每条记录每个字段的值。(以上耗时估计有多部分是耗在这里了)
D、通过上图对比可以发现:
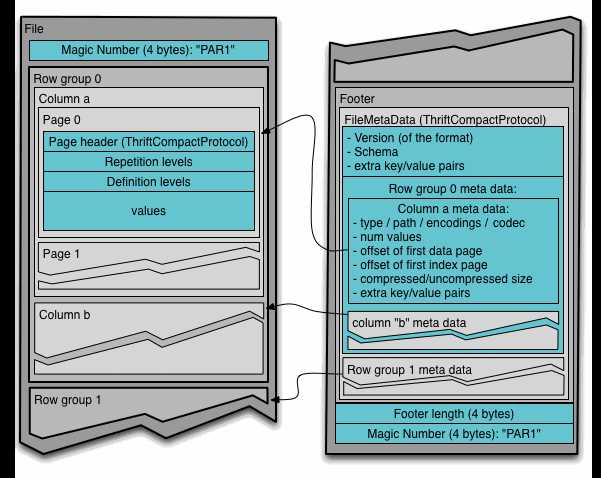
E、测试时请开启filterpushdown功能
4、结论
标签:
原文地址:http://www.cnblogs.com/piaolingzxh/p/5469964.html