标签:
这个也不是我原创的,我只是个学习者。
第一次听蒙地卡罗树搜索是关于阿尔法狗大战李世石。
https://jeffbradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/
回合制游戏中,每个选手都没有什么信息可以对对方隐藏的,而且也没有概率的因素在里面,比如掷骰子或者从牌队里面抽一张牌出来。
很多游戏都是这种类型,比如国际象棋,围棋等。
什么东西在这类游戏中都是确定的,从理论上来说,可以构建一颗树来包含所有可能的结果,然后可以给其中一位选手赋予一个和赢或者输相关的值。
找到最佳的可能的应对方案,就是对树进行搜索的过程,通过一种选择的方法,
在每一个回合中交替的取得最大值或者最小值,匹配不同选手冲突的目标,这个过程会一直对树搜索下去。
这个算法就称作minimax。
minimax的问题在于,要花很长的时间时间才能对树进行完全的搜索,尤其对于高度分支因子的游戏,或者说每一回合中可以走的步子很多。
这是由于对于很基础的minimax版本需要对树中所有的节点进行搜索才能找到最优解,同时树中待检验的节点数目随着分支因子以指数增长。
有很多的方法可以缓和这个问题,比如说仅仅搜索有限长度的步数,然后用评价函数来评估位置的值,或者修剪待搜索的分支如果它们可能是没有价值的。然而很多此类方法都需要对游戏的主要规则进行编码,然而这难以收集和制定。
即使这种方法可以做出下象棋的程序来击败象棋大师,但是这种成功并不适用于围棋,特别是不适用于在19x19的棋盘上。
然而,确实有一种游戏智能技术对这种高分支因子的程序有效,并且逐渐在围棋对弈程序的领域中占据主导。
很容易创建这种算法的基本实现,对较低分支因子的程序可取得不错的结果,可以基于它进行很简单的改进,然后对其改善可用于下围棋或者象棋。
可以对它进行配置,使得计算任意长度的时之后停止,当然,计算时间越长,取得的结果越好。
由于它实际上不需要和游戏相关的特定知识,可以用来进行一般的游戏对战。
同样也可以对它进行改进应用于那些规则中有随机性的游戏。
这种方法被称为Monte Carlo Tree Search(蒙地卡罗树搜索,MCTS)。
待会就会讲解MCTS是如果进行的,特别是一种称作Upper Confidence bound的东东应用于这种树(UCT),
然后就会向你展示如何用Python构建一个实现基本功能的MCTS。
设想,你将,你面对一排老(和)虎(谐)机,每个都有不同的回报概率和数目。
作为一个理性的人(呵呵,我就不理性),如果你将把它们都玩一遍,你会更倾向于用一种使你净收益最大的策略。
但是你如何才能做到这样呢?
无论出于什么原因,旁边一个人都没有,所以你不可能看到别人玩一会,然后获得那台是最好的机器。
很明显,你的策略将会是通过你自己平衡所有玩过的机器,从而靠自己收集信息,集中玩观察到的最好的机器。
有一种称为UCB1的策略,通过这样做对每个机器构建置信区间:

其中:
xi是第i台机器的平均回报
ni是第i台机器的游戏次数
n是总的游戏次数
然后,你的策略就是每次挑选出具有最大上界的那台机器。正如你这样做了之后,那台观测的机器的平均值会移动,
并且它的置信区间也会变窄,但是所有其他机器的区间都会变宽。最终,其他机器中有一台将会比你当前的这台会有更高的上界,
然后你就转到这一台上来。这种策略的特点在于,你的后悔度,即你只在实际上最好的那台机器上玩所得到的收益和你在这种策略下的期望收率的误差的增长速度是O(ln n)。这是一种和这种问题(被称作multi-armed bandit problem)理论上最好结果一样的大O增长速率,然后另外一个好处就是容易计算。
蒙地卡罗的的原理也在与此。在一个标准的蒙地卡罗过程中,大量的随机模拟过程被运行,在这种情况下,你想从棋盘上找到最优的位置。从这个开始状态的所有可能步骤都会被统计,然后根据返回过来的全局最优解来决定下哪一步。这种方法的缺点是,在模拟的给定的任一回合,都会有很多种可能的步子可下,但是只有一两处是很好的。如果每一轮都随机下一步,会使得模拟极不可能向前获得最优路径。因此,UCT作为一个增强的方法被提出来。这种想法是:如果所有位置仅仅移动一步的统计信息可以获得,任何一种给定的棋盘的位置都可以看作一种multi-armed bandit problem。因此,UCT采用计算多步的收益,而不是靠纯随机模拟进行。
第一步,选择,直到你获得了必要的统计信息来处理你达到的每一个位置,就像面对一个multi-armed bandit problem一样。
采用的那一步,将会通过UCB1算法选择出来,而不是随机选择,然后应用于获得下一个要考虑的位置的信息。
选择过程将会进行到你达到了一个并给所有子位置的统计信息都被记录的哪个位置。
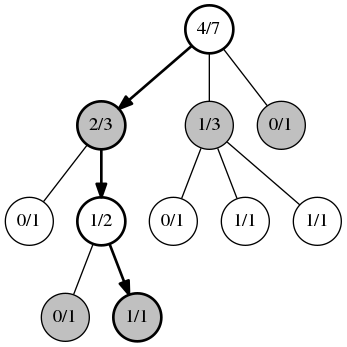
选择
每一步加粗标记的是通过UCB1算法选择的位置和下的步骤。注意到很多次的游戏过程已经进行了,从而获得如上的统计信息。
每个圈圈包含了赢的次数/总共进行的次数。
第二步,展开,当你不能在用UCB1时就会展开。一个随机选择一个未访问过的子位置,并且一个新的记录节点被加入到这颗统计树中。
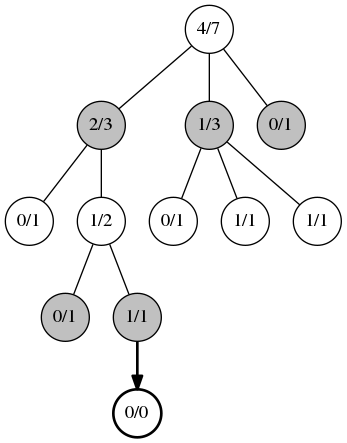
在树的最底部标记的1/1下面并没有更多的统计信息,因此我们随机选择一步,并且把它加入到新纪录中,初始化为0/0。
展开过后,剩余的对战是在第三阶段,模拟。这一步通过一个典型的蒙地卡罗模拟来完成,要么是通过纯随机选择要么是通过一些简单的启发式权重,或者是一些需要大量计算的启发式方法并且评估。对于分支因子较小的游戏,light playout是个不错的选择。
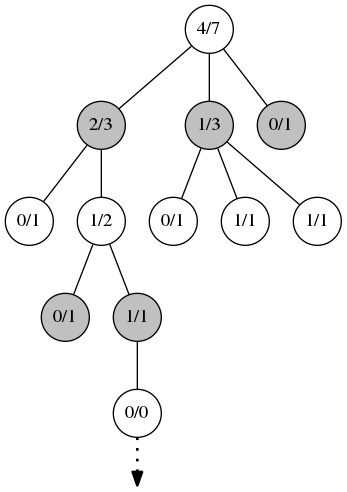
一旦新的记录被加入进来,蒙地卡罗模拟过程便开始了,这里用一个点画线的箭头描述。
在模拟过程中下的步骤是完全随机的,或者为了下得更好而使用一些权重计算。
最终,第四步是更新或者反向传递过程。这一过程发生在博弈进行到末尾之后。
在博弈过程过所有访问过的位置对战次数增加,并且如果在这个位置的选手赢得了对战,那么赢的次数也会增加。
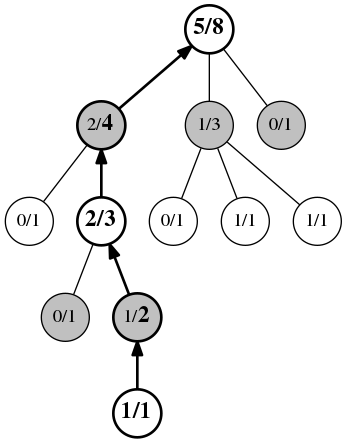
在模拟达到最后时,在路径中的所有采纳的记录都会被更新。每个的对战的次数都会加1,并且如果匹配赢的一方赢的次数也会加1,这里用加粗来来表示。
这个算法可以设置在任意计算时间长度或则其他条件下停止。如果对战的次数进行地越多,这棵树的统计信息在内存中会增长,并且最终选择的落子步骤也会接近于实际的最优解,根据游戏的不同,所花的时间也许会很久。
想要了解更过关于UCB1和UCT的数学上的知识,可以参考http://homes.di.unimi.it/~cesabian/Pubblicazioni/ml-02.pdf和https://www.lri.fr/~sebag/Examens_2008/UCT_ecml06.pdf。
现在让我们来看看代码。为了分隔某些考量,我们将需要一个Board类,其目的是包含游戏规则并且不考虑AI,以及一个MonteCarlo类,这个类只考虑AI算法,并且会查询Board对象以获得关于游戏的信息。我们假设棋盘类支持如下接口:
未完。。。
标签:
原文地址:http://www.cnblogs.com/tuhooo/p/5471126.html