标签:
NLPIR汉语分词系统(自然语言处理与信息检索共享平台),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取;张华平博士先后倾力打造十余年,内核升级10次。
全球用户突破20万,先后获得了2010年钱伟长中文信息处理科学技术奖一等奖,2003年国际SIGHAN分词大赛综合第一名,2002年国内973评测综合第一名。
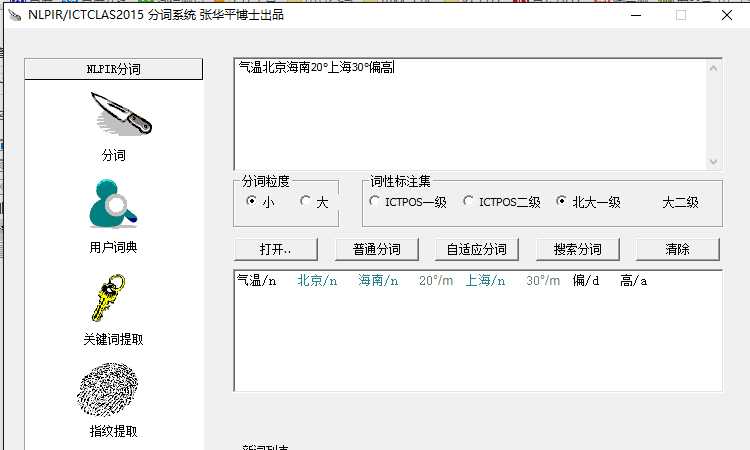
下面我们以KETTLE为例来说明
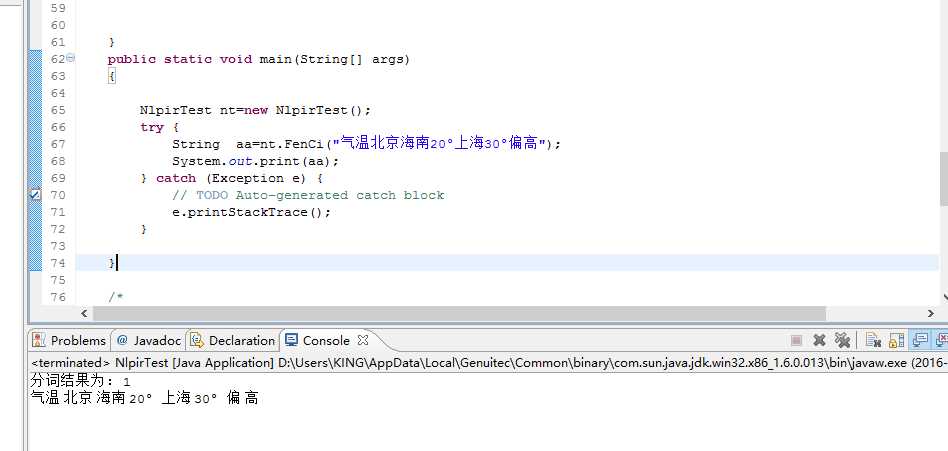
首先使用NLPIR提供的demo开发一个java project,通过在main函数中测试可以完成简单的分词功能,如下图所示
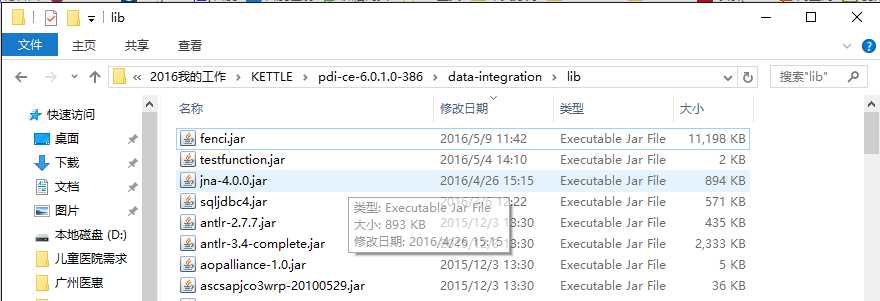
把开发的java project导出为 fenci.jar放入到......\pdi-ce-6.0.1.0-386\data-integration\lib下面
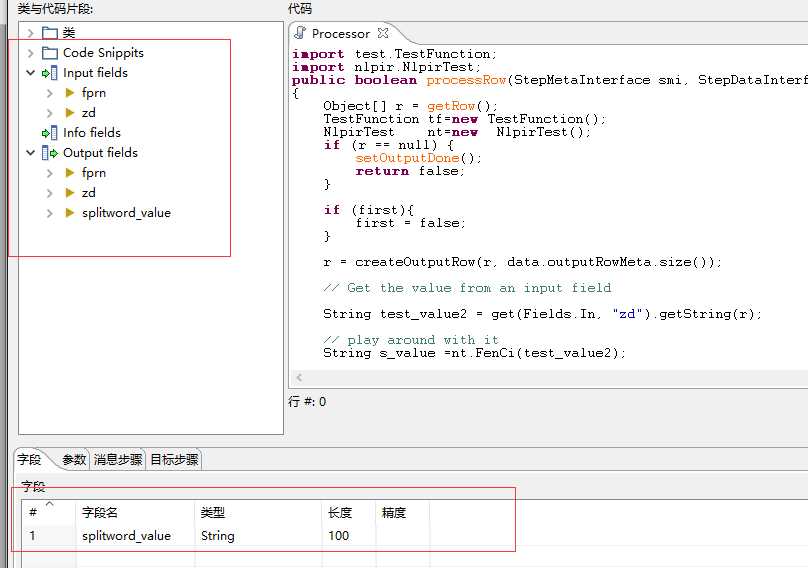
在kettle的ktr中拖入一个Java 代码的控件,代码如下图所示
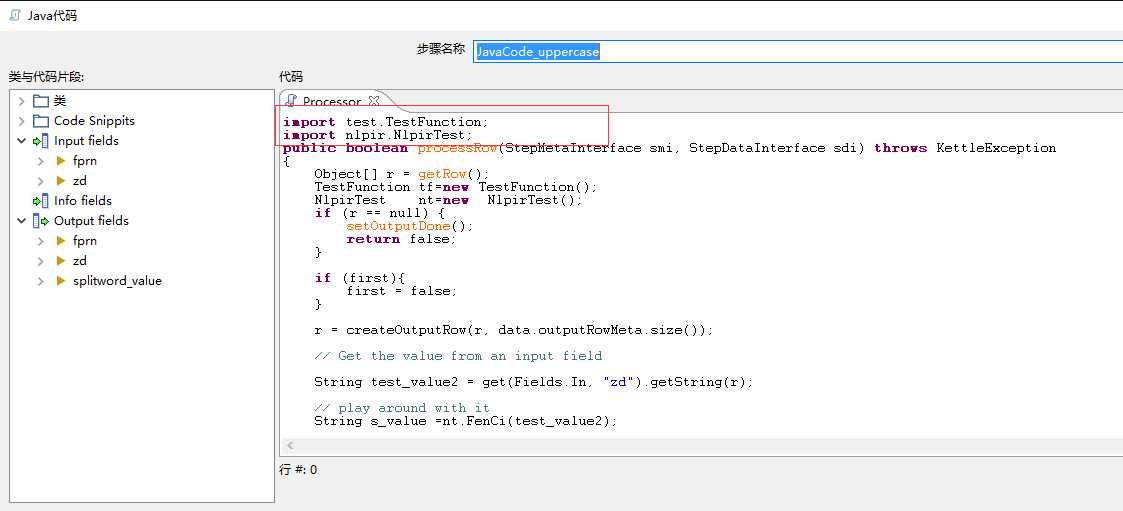
具体代码为:
import test.TestFunction; import nlpir.NlpirTest; public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException { Object[] r = getRow(); TestFunction tf=new TestFunction(); NlpirTest nt=new NlpirTest(); if (r == null) { setOutputDone(); return false; } if (first){ first = false; } r = createOutputRow(r, data.outputRowMeta.size()); // Get the value from an input field String test_value2 = get(Fields.In, "zd").getString(r); // play around with it String s_value =nt.FenCi(test_value2); // Set a value in a new output field get(Fields.Out, "splitword_value").setValue(r,s_value); // Send the row on to the next step. putRow(data.outputRowMeta, r); return true; }
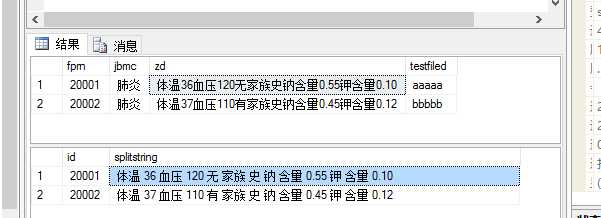
这样输出中就会新增加一列字段名为 "splitword_value"的输出,如下图所示,左侧和下面显示正常则说明类书写正常
3.5:难点解析
从下载的官方文件中得知:
1.分词和提取关键词在一起jnaTest是新词发现和关键词提取在一起。
2.如果加载项目后无法运行请配置classpath中的lib路径为jna包的路径。
3.loadlibrary中的dll路径为你项目中dll的路径,该路径可以是绝对路径或者相对路径。
4.如果出现未提示错误,可以F5刷新项目查看日志文件。
5.建议jdk使用32,因为jna在32jdk上更稳定。
所以本人在64bit jdk下面没有成功,在kettle环境引用32bit的jdk后一切都可以跑起来了
另:由于是32bit的jdk,需要修改kettle的启动文件 spoon.bat中的默认设置修改如下
原来的值:if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms1024m" "-Xmx2048m" "-XX:MaxPermSize=256m"
修改后为:if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms512m" "-Xmx1024m" "-XX:MaxPermSize=256m"
保存spoon.bat再次启动 一切正常
标签:
原文地址:http://www.cnblogs.com/wxjnew/p/5473974.html