标签:
yarn是一个分布式的资源管理系统。
它诞生的原因是原来的MapReduce框架的一些不足:
1、JobTracker单点故障隐患
2、JobTracker承担的任务太多,维护Job状态,Job的task的状态等
3、在taskTracker端,使用map/reduce task表示资源过于简单,没有考虑cpu、内存等使用情况。当把多个需要消耗大量内存的task调度到一起时,很容易出现问题
演化后的基本组件
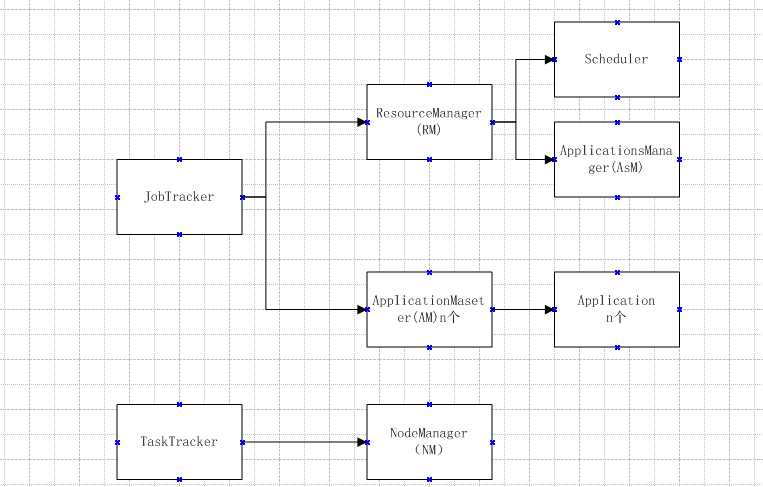
下面具体解释:
yarn是一个资源管理的框架,而非计算的框架,理解这点很重要。
图中的Application相当于1.x版本中的map/reduce job。
图中的Container是一个逻辑概念,是一组资源(内存、cpu等)的统称。
AM:每一个Application对应一个AM。
ResourceManager:主要来做资源的协调者。有两个重要的组件:
Scheduler:【资源调度】从所有运行着的Application收到资源请求后,构建一个全局的分配计划。然后根据Application特殊的限制以及全局的一些限制条件分配资源。【资源监视】周期性的接受来自NM的资源使用率监控信息。注意这和job的执行情况无关,只是监视资源。另外可以为AM提供其已完成的container的状态信息。
Asm:接收资源请求,向Scheduler申请一个Container提供给AM,并启动AM。向client提供AM运行状态。总结一句话,就是用来管理所有AM的生命周期。
yarn工作流程:
总结的说就是两步:client提交Job到ASM,ASM请求资源运行起来AM;AM接管,它计算split、申请资源、与NM配合运行task、监控task等。
1、Job client向AsM提交job。
1)获得ApplicationID
2)将Application定义,以及所需jar包上传到hdfs指定目录(yarn-site.xml的yarn.app.mapreduce.am.staging-dir)
3)构造资源请求对象以及Application提交上下文信息,提交给AsM
2、AsM向Scheduler请求一个供AM运行的Container,向其所在NM发送launchContainer信息,启动Container
3、AM被其所在的NM启动后向ASM注册
4、Job client从AsM处获得AM信息,并与之直接通信
5、AM计算splits并为所有map构造资源请求
6、AM做一些OutputCommitter的准备工作
7、AM向Scheduler申请资源(一组Container)然后与NM一起对Container执行一些必要的任务,例如资源本地化
8、AM监视task,如果失败重新申请Container,如果完成,运行OutputCommitter的cleanup以及commit动作
9、AM退出
client想知道监控信息的途径:
task的从AM获取
AM的从AsM获取
NM还有一项工作,监控task所使用的资源,如果超出所申请的Container范围,则kill掉其任务进程
yarn是资源框架,计算框架运行于资源框架之上。map-reduce是计算模型,它实现了特定的ApplicationMaster,才得以在yarn上运行。如果是其他的计算模型,还需要实现特定的ApplicationMaster,才能在yarn上运行。
引申阅读:http://www.aboutyun.com/thread-7678-1-3.html
标签:
原文地址:http://www.cnblogs.com/xyang/p/5475088.html