标签:
2014的新特性针对基数估计的新设计相信大家并不陌生,同时如果亲身体验过从低版本升级到2014的小伙伴一定感触良多。一个字 “丫的坑死我了!”
很多因为升级到2014后语句莫名其妙的问题网上很多,今天讲述一个我在2014下遇到的分区表问题,话不多说先上个小奇葩:
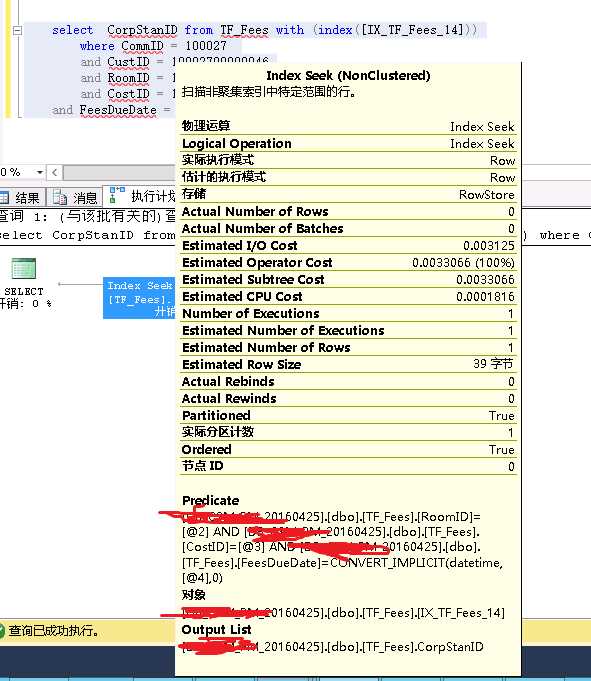
TF_Fees表为一个数据2QW+的数据表并作了200+分区,并且每个分区都在不同的文件组(非不同物理磁盘)(有人会说 谁会做200多个分区...好吧确实有)从执行计划来看这条简单的语句使用了IX_TF_Fees_14 这个索引查找并且耗时38毫秒!
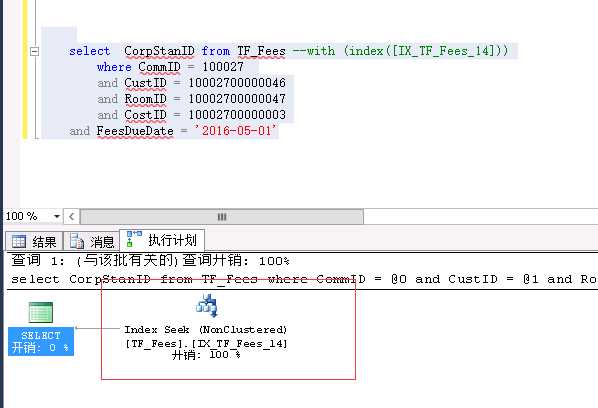
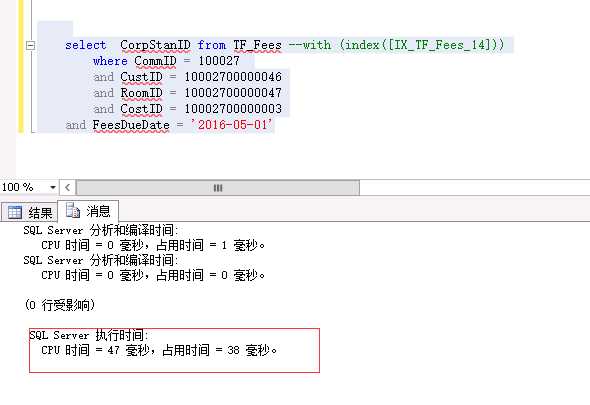
-------------------------------下面亮点来了-----------------------------------
指定使用 IX_TF_Fees_14 这个索引,神奇的效果出现了 执行时间0毫秒(反复测试的结果....)
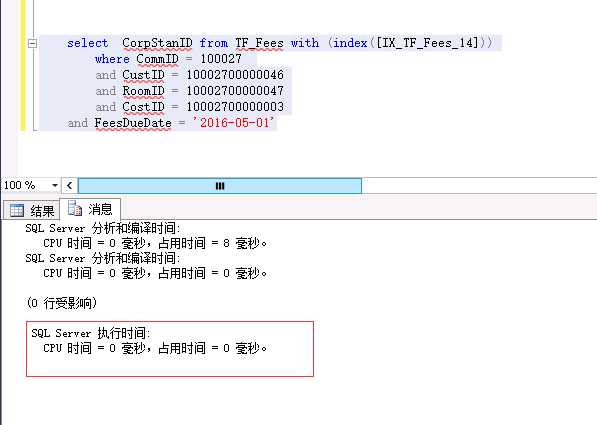
------------------------------------肯定有人怀疑执行计划的问题-----------------------
用本人资深找茬的功力我真没看出不同
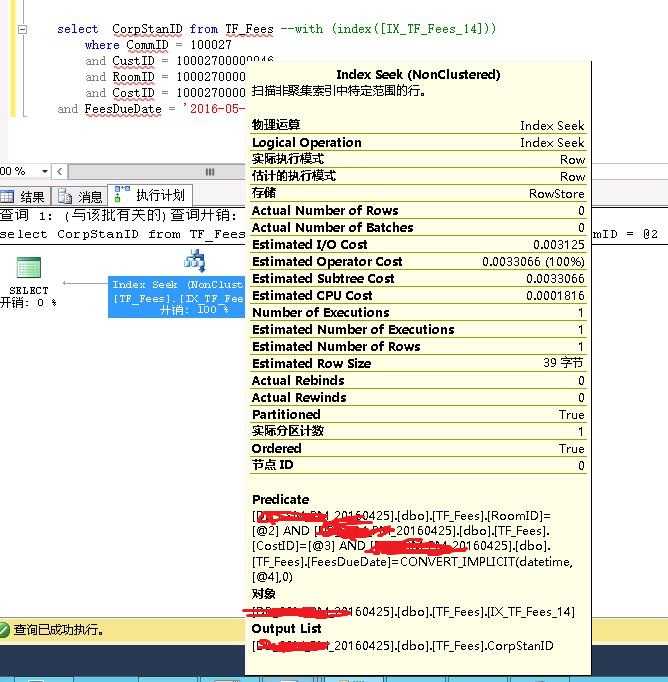
--------------------------------那IO呢?-------------------------------
用本人资深找茬的功力我还是没看出不同
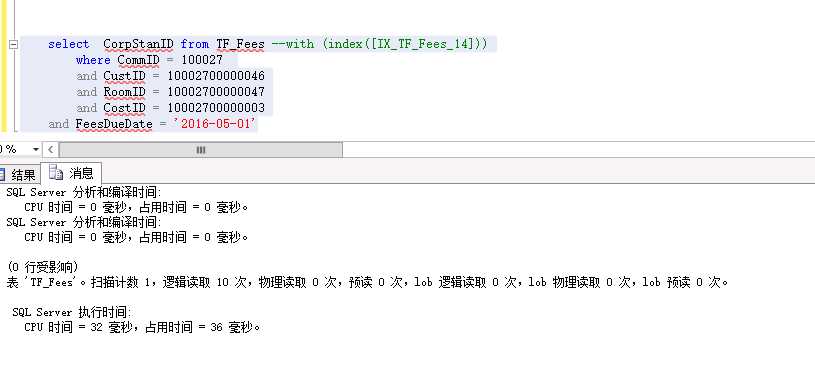
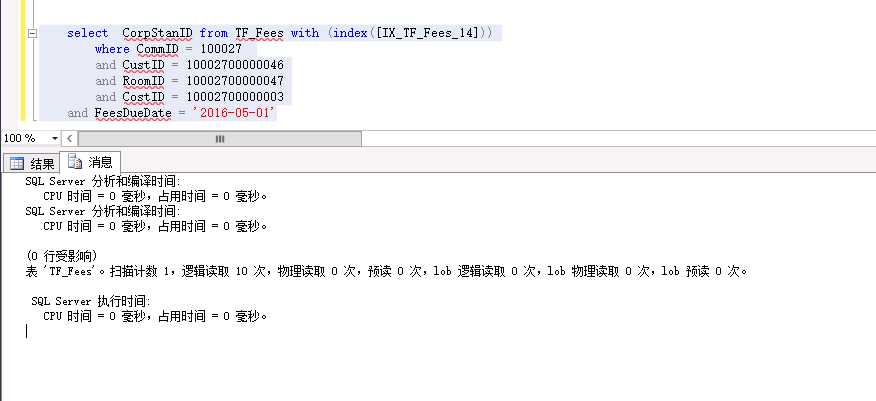
38毫秒和0毫秒看似没有差别,但是这条语句是在一个几万次的循环中,悲剧可想而知!!!
真真的不明白是什么原理 SQL SERVER在编译语句选用索引,选用计划的时候到底做了什么,只能傻傻的尝试。表在没有分区的情况下执行时间很稳定都是0毫秒 ,毕竟这么简单的语句。那么和分区数是否有关系的?200+的分区数,尝试降低一半,下面我完全复制了这张表数据、索引等,不同的是这次我只用100个分区。
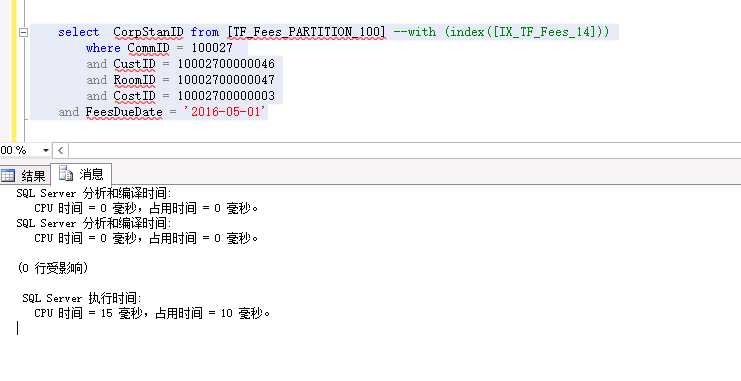
话说100个分区的时间确实比200个分区的时间缩短将近一半。那么果真的分区个数导致的,这么简单离奇的时间变长? 真心想不明白这是为什么了!!!!!!!
想不明白了....
想不明白了....
希望研究过分区表索引选用问题的大神给点思路...毕竟添加个指定索引不是解决问题的根本办法~~~~~~~~
标签:
原文地址:http://www.cnblogs.com/double-K/p/5475576.html