标签:
Kylin是一个开源的分布式的OLAP分析引擎,基于Hadoop提供SQL接口和OLAP接口,支持TB到PB级别的数据量。Kylin环境搭建前,需要安装JDK,MySQL,Tomcat,Hadoop,HBase,Hive,ZooKeeper等软件。由于我们使用Ambari对集群进行管理,所以这些工作已经做好,只简单介绍Kylin环境搭建。
一. Kylin环境搭建
下载apache-kylin-1.5.1-bin.tar.gz并且解压,配置Tomcat和Kylin的环境变量。然后主要是配置kylin.properties,比如kylin.rest.servers等。最后kylin.sh start启动Kylin,kylin.sh stop关闭Kylin。登陆http://hostname:7070/kylin访问Kylin应用程序,用户名和密码分别为ADMIN,KYLIN。
说明:需要说明的是apache-kylin-1.5.1-bin.tar.gz中已经包含Tomcat。
Kylin的一些特性,如下所示:
二. Kylin Cube建立和Job监控
我们使用官方自带的例子sample.sh进行学习,如下所示:
1.运行${KYLIN_HOME}/bin/sample.sh,并重启Kylin。
解析:
在Hive默认数据库下面生成了三张表,分别为kylin_cal_dt,kylin_category_groupings,kylin_sales。
2.登陆http://hostname:7070/kylin,并选择工程"learn_kylin"。
3.点击Model页面中Actions选项中的Build。
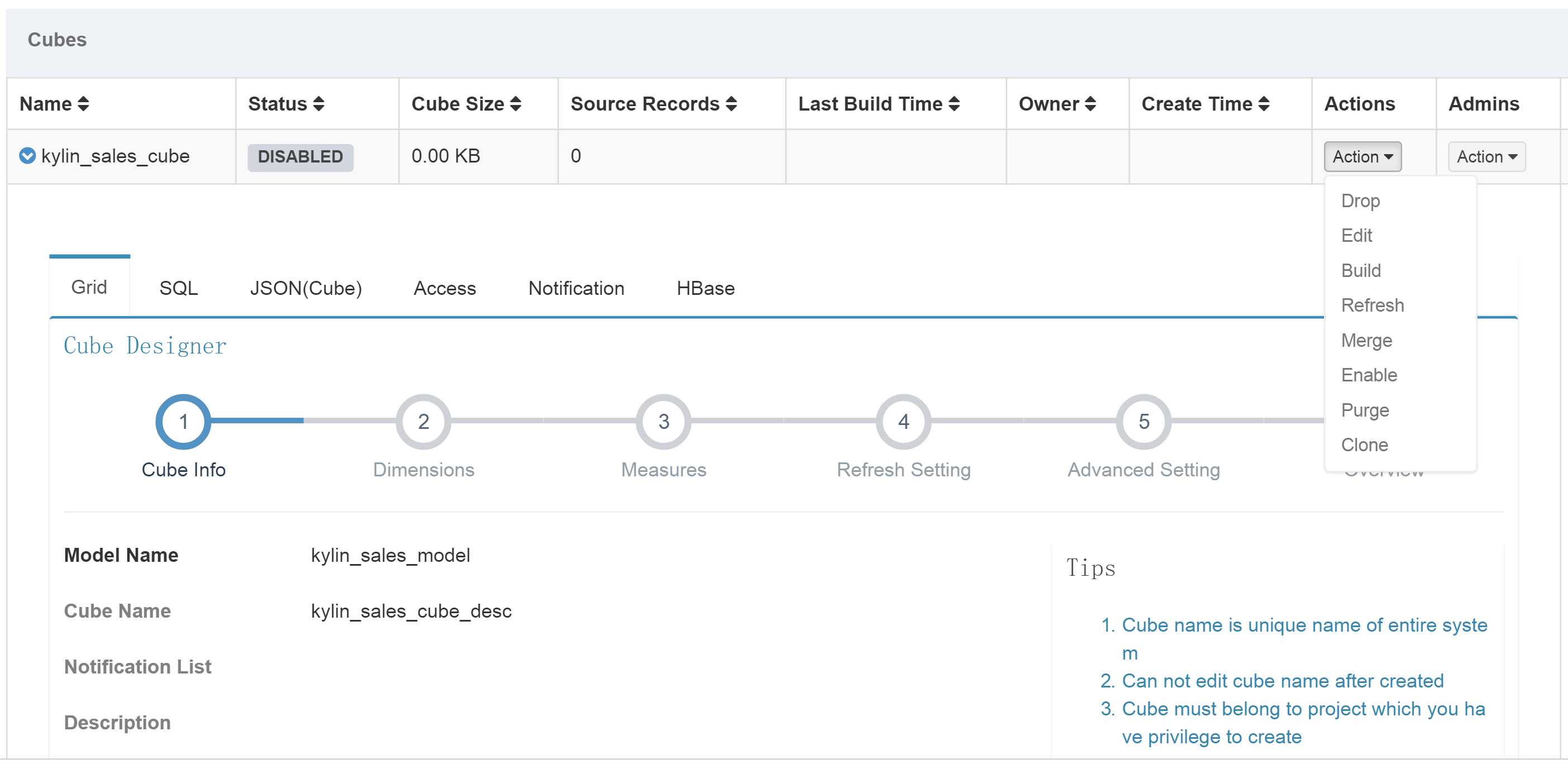
说明:点击END DATE输入框选择增量构建这个cube的结束日期,并Submit提交请求。
4.点击Monitor页面
提交请求成功后,将会看到新建了job。点击job详情按钮查看显示于右侧的详细信息。如下所示:
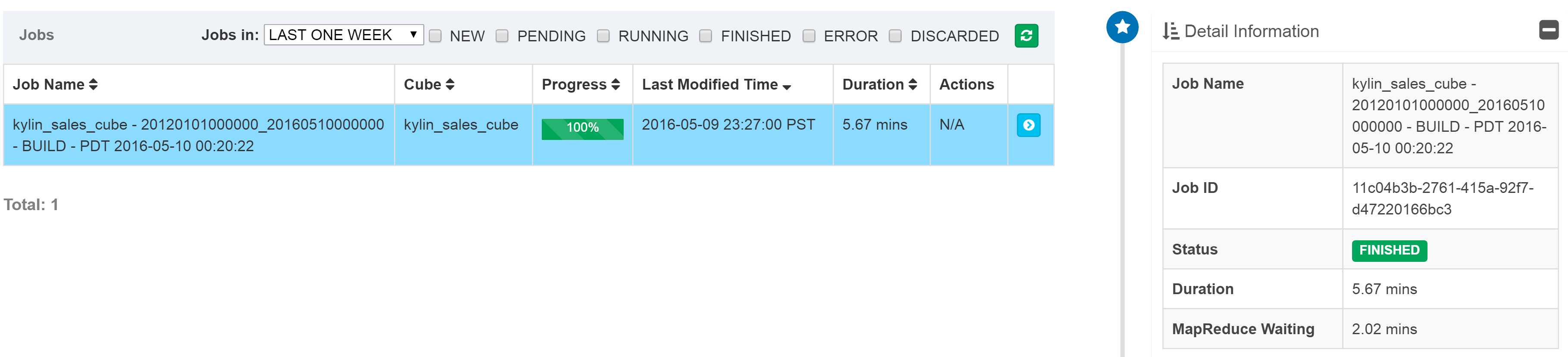
说明:job详细信息为跟踪一个job提供了它的每一步记录。可以将光标停放在一个步骤状态图标上查看基本状态和信息。点击每个步骤显示的图标按钮查看详情:Parameters、Log、MRJob、EagleMonitoring。
5.点击Insight页面中的New Query选项
解析:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
三. Kylin Cube权限授予
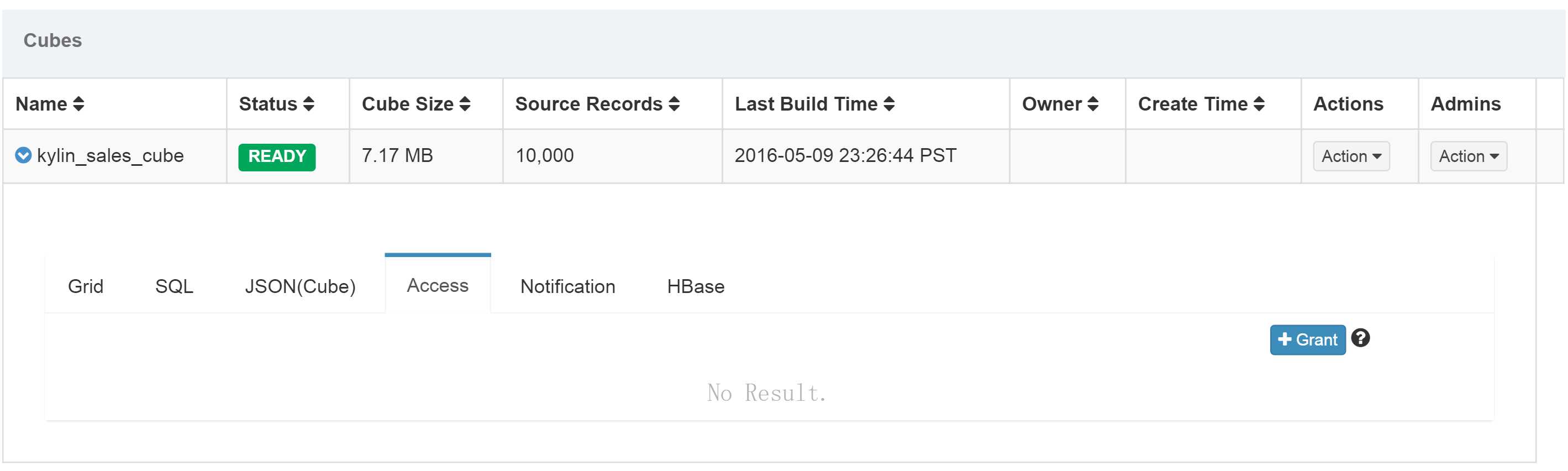
点击+Grant按钮进行授权。一个cube有四种不同的权限,分别是CUBE QUERY,CUBE OPERATION,CUBE MANAGEMENT,CUBE ADMIN。授权对象也有两种:User和Role。Role是指一组拥有同样权限的用户。
1. 授予用户权限
解析:
选择User类型,输入你想要授权的用户的用户名并选择相应的权限。选择User类型,输入你想要授权的用户的用户名并选择相应的权限。然后点击Grant按钮提交请求。在这一操作成功后,便会在表中看到一个新的表项。可以选择不同的访问权限来修改用户权限。点击Revoke按钮可以删除一个拥有权限的用户。
2. 授予角色权限
选择Role类型,通过点击下拉按钮选择你想要授权的一组用户并选择一个权限。然后点击Grant按钮提交请求。在这一操作成功后,便会在表中看到一个新的表项。可以选择不同的访问权限来修改组权限。点击Revoke按钮可以删除一个拥有权限的组。
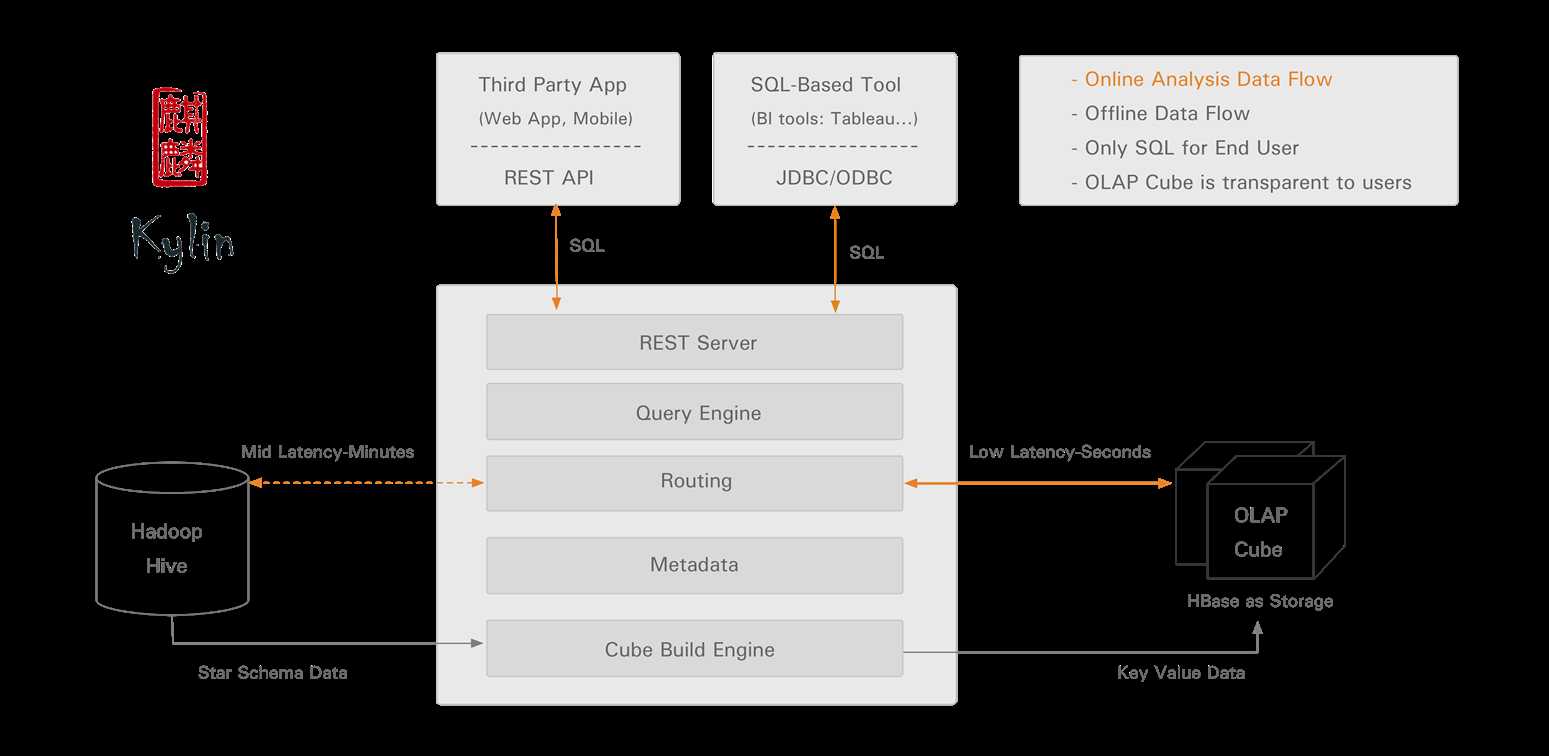
四. Kylin工作原理
Kylin OLAP引擎基础框架,包括元数据(Metadata)引擎,查询引擎,Job引擎及存储引擎等,同时包括REST服务器以响应客户端请求。Apache Kylin概览,如下所示:
参考文献:
[1] APACHE KYLIN概览:http://kylin.apache.org/cn/
[2] 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例:http://lxw1234.com/archives/2016/04/643.htm
[3] Apache Kylin的快速数据立方体算法:http://www.infoq.com/cn/articles/apache-kylin-algorithm
[4] 面向大数据的终极OLAP引擎方案:http://www.csdn.net/article/2014-10-25/2822286
[5] Kylin的OLAP引擎:http://www.mamicode.com/info-detail-1015006.html
[6] Apache Kylin大数据时代的OLAP利器:http://www.bitstech.net/author/huwei/
[7] Kylin的Cube模型:http://www.cnblogs.com/en-heng/p/5239311.html
标签:
原文地址:http://www.cnblogs.com/shengshengwang/p/5477220.html