标签:
1、什么是mapreduce
mapreduce是hadoop自带的分布式计算框架。
2、mapreduce的基本思想
2.1、能够解决什么问题
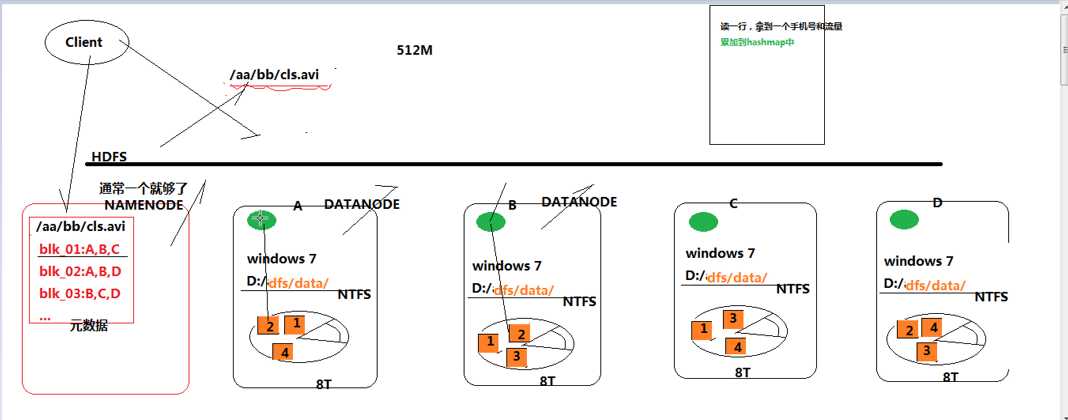
假设一个场景:一个电商系统,统计某个手机号的用户的上行和下行流量。
如果通过一个节点的计算机,对各个datanode上的文件进行扫描,将结果统计到一个hashmap中,这样的
方式存在受网络IO限制、执行速度慢、耗时、单台计算机存储容量瓶颈等问题。
2.2、解决方法
既然挪动数据到一台计算机进行统计走不通,那么可以考虑在各个节点都运行mapreduce的统计程序,首
先对每个节点进行map操作(单独统计),然后将map进行reduce(数据汇总),这里map阶段比较容易且
运行速度快,而red,这里这里暂时不做研究。
2.3、基本思想

3、mapreduce、storm、spark三者的关系
这三者都是分布式计算框架,都可用于hadoop的分布式计算。但三者之间有明显的差异。具体如下:
mapreduce是离线批处理的计算,storm、spark做实时计算。storm是完全的实时,不间断,而spark还是
有延迟的。
mapreduce是通过磁盘处理数据的,spark是通过内存处理数据的。
标签:
原文地址:http://www.cnblogs.com/hzhtracy/p/5482324.html