标签:
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。 应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。在大数据生态系统中,Alluxio介于计算框架(如Apache Spark,Apache MapReduce,Apache Flink)和现有的存储系统(如Amazon S3,OpenStack Swift,GlusterFS,HDFS, Ceph,OSS)之间。 Alluxio为大数据软件栈带来了显著的性能提升。例如,百度采用Alluxio使他们数据分析流水线的吞吐量提升了30倍。 巴克莱银行使用Alluxio将他们的作业分析的耗时从小时级降到秒级。 除性能外,Alluxio为新型大数据应用作用于传统存储系统的数据建立了桥梁。 用户可以以独立集群方式(如Amazon EC2)运行Alluxio,也可以从Apache Mesos或Apache YARN上启动Alluxio。Alluxio与Hadoop是兼容的。这意味着已有的Spark和MapReduce程序可以不修改代码直接在Alluxio上运行。Alluxio是一个已在多家公司部署的开源项目(Apache License 2.0)。 Alluxio是发展最快的开源大数据项目之一。自2013年4月开源以来, 已有超过50个组织机构的 200多贡献者参与到Alluxio的开发中。包括 阿里巴巴, Alluxio, 百度, CMU,IBM,Intel, Red Hat,UC Berkeley和 Yahoo。Alluxio处于伯克利数据分析栈( BDAS)的存储层,也是Fedora发行版的一部分。
以上这段概要从官网摘下,自己再总结一下:
1.首先,它是和Hadoop兼容的,所以很多Spark,MapReduce程序可以直接跑,那为什么还要用到Alluxio呢?
答:因为它是基于内存的,可以把中间结果文件,或者一些文件缓存起来,可以选择刷到磁盘上或者其他很多读写方式,简化了分布式系统中内存的管理,减少读写磁盘.
2.第二,该文件系统对于一个文件只能写一次,就是在你创建的时候可以写,之后你就只能读了.(在官方的文档上有)
3.第三,该文件系统可以和zookeeper整合起来,(虽然笔者没有试),但是Alluxio自身是无法加分布式锁的,所以他的应用场景可能比较特殊,我认为比较适合只读的情况比较好,当并发的写入同一个文件时,可能无法得到保证.
架构部分
在明确了他的特点后,就和看病一样总得理解它有哪些部位,所以架构还是有必要了解,自己学习的时候开始总不好好看官方文档会浪费时间.架构主要分为三个角色,master,worker,client.master与worker构成服务端,而我们的程序只和client端打交道.这里提供官方网站--架构部分(中文版)非常好理解才一页.http://alluxio.org/documentation/v1.0.1/cn/Architecture.html.我就不敖述了.
开始动手搭建.
需要1.java运行环境 2.hdfs搭建 3.搭建Alluxio4.操作系统为centos7
本文java版本为1.7.0_71 HDFS版本为hadoop-2.7.1 Alluxio版本为当前最新alluxio-1.0.1 (可能是版本问题,Tachyon 0.8无法连接hdfs.走了很多弯路)
我在两台机器暂且称为A B. A作为MASTER B作为SLAVE2.在此前已经配置完HDFS.
可以访问Master端的50070确认HDFS是否正常也可以 用jps命令.该命令可以看到所有的JAVA运行程序的PID.
此时A机器上会有一个SecondaryNameNode,NameNode. B机器上会有DataNode 进程.
搭建步骤:
1.在master机器上运行
wget http://alluxio.org/downloads/files/1.0.1/alluxio-1.0.1-bin.tar.gz tar xvfz alluxio-1.0.1-bin.tar.gz
2.安装完毕后
将alluxio-1.0.1/conf 中的alluxio-env.sh.template 拷贝一份命名为alluxio-env.sh.该脚本其实就是配置文件.
主要配置几个地方(仅贴上修改处 其他都没有变动)
export ALLUXIO_MASTER_ADDRESS=${ALLUXIO_MASTER_ADDRESS:-master}
export ALLUXIO_UNDERFS_ADDRESS=${ALLUXIO_UNDERFS_ADDRESS:-hdfs://master:9000/alluxio}
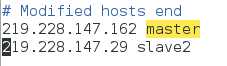
这里"/alluxio"是我已经在HDFS中创建的文件夹.也可以不写. 还有一个问题这里的-master是什么意思? 此前我并没有配置master.他怎么会知道呢.
答:alluxio会从/etc/hosts 中去寻找映射,所以你必须给master 和slave配上对应的ip地址.(图为我自己的hosts配置)
此时最后还需要修改conf/workers(之前tachyon 一致没搞懂 居然又有slave 文件又有workder.)在里面把localhost注释,加上你集群中的节点.

到这里配置全部结束.
cd到alluxio目录下执行(该命令会把该目录scp到所有的节点上)
./bin/alluxio copyDir .
此时执行(官网推荐是all Mount 不过我没关系.)
$ ./bin/alluxio format $ ./bin/alluxio-start.sh all NoMount
(期间会要你输入很多密码,原理就是它会ssh到各个机器上去启动worker 不过没关系,我们可以百度ssh免密码登陆,这个帖子太多,但是有两个小细节 第一就是 authoried_keys权限必须是600 而且你的用户比如我是imdb 那么 /home/imdb的权限必须是700 网上博客都没说!!!!!)
之后可以jps一下 发现master端多了AlluxioWorker和AlluxioMaster slave端多了AlluxioWorker. 可以用去测试.应该是通过的.
$ ./bin/alluxio runTests
打开浏览器输入http://master:19999/home
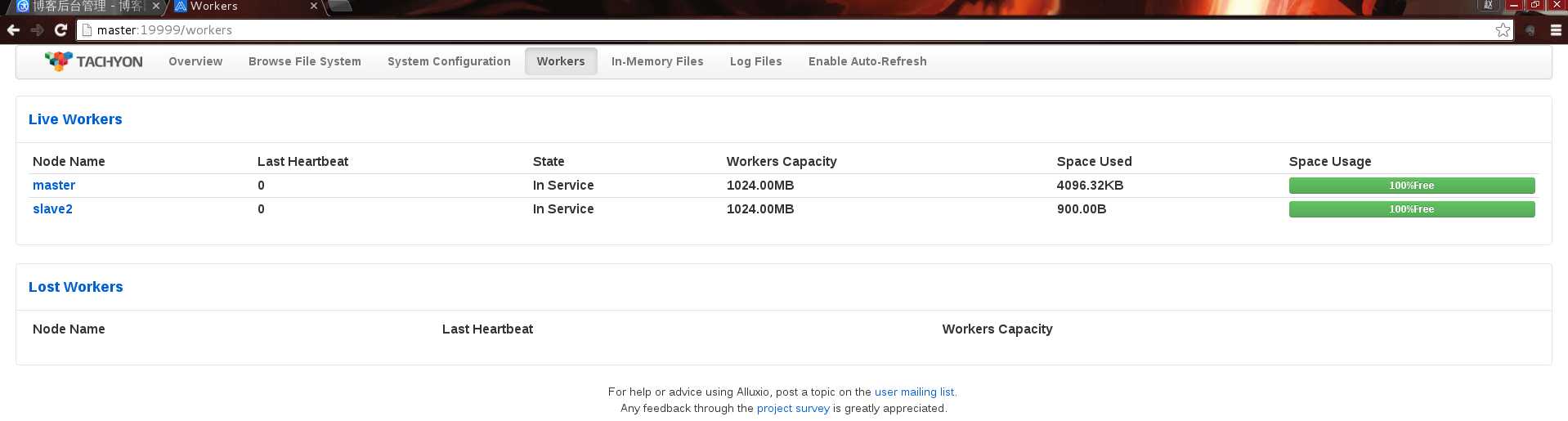
就搞定了.在本地模式的API官网上有,只需把 alluxio中assembly/target/alluxio-assemblies-1.0.1-jar-with-dependencies.jar加到eclipse里面API官网有就不多讲.
但是,不得不说,分布式的读写API我官网上没有找到文档,博客也都是非常老旧.唯一办法是从它文件夹里的Test案例自己摸索...网上的文章太少,所以特此写一下,有错误请大家纠正.
Alluxio1.0.1最新版(Tachyon为其前身)介绍,+HDFS分布式环境搭建
标签:
原文地址:http://www.cnblogs.com/zhejiangxiaomai/p/5483908.html