标签:
上一篇咱们讲到了七夜音乐台的需求和所需要的技术。咱们今天就讲一下爬虫,为什么要讲爬虫,因为音乐台的数据源需要通过爬虫来获取,不可能手动来下载。下图是一个网络爬虫的基本框架:
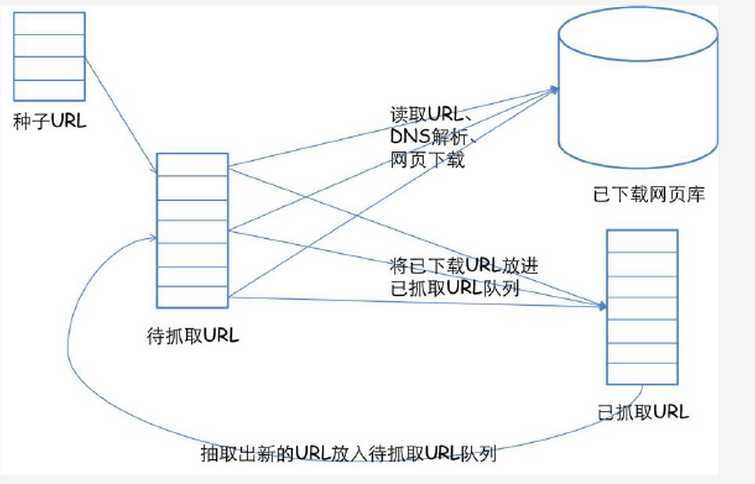
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
网络爬虫本质其实就是一些网络请求和响应,只不过爬虫把这些有效的整合起来做一些重复性劳动。
大家如果想切实的感受一下网络爬虫,看一下我之前写的python爬虫:爬取慕课网视频,大家会对爬虫的基本工作原理有比较深的了解。
说到爬虫,不得不提及一下Scrapy的爬虫架构。crapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。下面是Scrapy爬虫框架图:
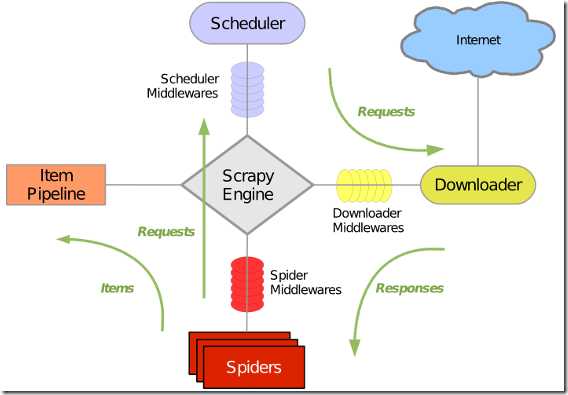
绿线是数据流向,首先从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
之后咱们就使用Scrapy框架来爬取音乐资源,下面给大家介绍一个Scrapy入门知识。我们假定您已经安装好Scrapy,如果不会安装,请百度一下scrapy安装,很多,咱们不详细说了。接下来以 Open Directory Project(dmoz) (dmoz) 为例来讲述爬取。
本篇教程中将带您完成下列任务:
在开始爬取之前,您必须创建一个新的Scrapy项目。 进入您打算存储代码的目录中,运行下列命令:
scrapy startproject tutorial
该命令将会创建包含下列内容的 tutorial 目录:
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
我推荐将生成的代码由pycharm打开,进行开发,IDE相对开发快一些。
Item 是保存爬取到的数据的容器;其使用方法和python字典类似。虽然您也可以在Scrapy中直接使用dict,但是 Item 提供了额外保护机制来避免拼写错误导致的未定义字段错误。
您可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个Item。
首先根据需要从dmoz.org获取到的数据对item进行建模。 我们需要从dmoz中获取名字,url,以及网站的描述。 对此,在item中定义相应的字段。编辑 tutorial 目录中的 items.py 文件:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
一开始这看起来可能有点复杂,但是通过定义item, 您可以很方便的使用Scrapy的其他方法。而这些方法需要知道您的item的定义。
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义一些属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。以下为我们的第一个Spider代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2] + ‘.html‘
with open(filename, ‘wb‘) as f:
f.write(response.body)
进入项目的根目录,执行下列命令启动spider:
scrapy crawl dmoz
该命令启动了我们刚刚添加的 dmoz spider, 向 dmoz.org 发送一些请求。 您将会得到类似的输出:
2014-01-23 18:13:07-0400 [scrapy] INFO: Scrapy started (bot: tutorial)
2014-01-23 18:13:07-0400 [scrapy] INFO: Optional features available: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Overridden settings: {}
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled extensions: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled downloader middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled spider middlewares: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Enabled item pipelines: ...
2014-01-23 18:13:07-0400 [scrapy] INFO: Spider opened
2014-01-23 18:13:08-0400 [scrapy] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/> (referer: None)
2014-01-23 18:13:09-0400 [scrapy] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
2014-01-23 18:13:09-0400 [scrapy] INFO: Closing spider (finished)
现在,查看当前目录,您将会注意到有两个包含url所对应的内容的文件被创建了: Book , Resources,正如我们的 parse 方法里做的一样。
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors。 关于selector和其他提取机制的信息请参考 Selector文档 。
这里给出XPath表达式的例子及对应的含义:
/html/head/title: 选择HTML文档中 <head> 标签内的 <title> 元素/html/head/title/text(): 选择上面提到的 <title> 元素的文字//td: 选择所有的 <td> 元素//div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素上边仅仅是几个简单的XPath例子,XPath实际上要比这远远强大的多。如果想学习Xpath,请到W3CSchool
为了配合CSS与XPath,Scrapy除了提供了 Selector 之外,还提供了方法来避免每次从response中提取数据时生成selector的麻烦。
Selector有四个基本的方法(点击相应的方法可以看到详细的API文档):
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
为了介绍Selector的使用方法,接下来我们将要使用内置的 Scrapy shell 。Scrapy Shell需要您预装好IPython (一个扩展的Python终端)。
您需要进入项目的根目录,执行下列命令来启动shell:
scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"
shell的输出类似:
[ ... Scrapy log here ... ]
2014-01-23 17:11:42-0400 [scrapy] DEBUG: Crawled (200) <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/> (referer: None)
[s] Available Scrapy objects:
[s] crawler <scrapy.crawler.Crawler object at 0x3636b50>
[s] item {}
[s] request <GET http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[s] response <200 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
[s] settings <scrapy.settings.Settings object at 0x3fadc50>
[s] spider <Spider ‘default‘ at 0x3cebf50>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
In [1]:
当shell载入后,您将得到一个包含response数据的本地 response 变量。输入 response.body 将输出response的包体, 输出 response.headers 可以看到response的包头。
#TODO.. 更为重要的是, response 拥有一个 selector 属性, 该属性是以该特定 response 初始化的类Selector 的对象。 您可以通过使用 response.selector.xpath() 或 response.selector.css() 来对response 进行查询。 此外,scrapy也对 response.selector.xpath() 及 response.selector.css() 提供了一些快捷方式, 例如 response.xpath() 或 response.css() ,
同时,shell根据response提前初始化了变量 sel 。该selector根据response的类型自动选择最合适的分析规则(XML vs HTML)。
让我们来试试:
In [1]: response.xpath(‘//title‘)
Out[1]: [<Selector xpath=‘//title‘ data=u‘<title>Open Directory - Computers: Progr‘>]
In [2]: response.xpath(‘//title‘).extract()
Out[2]: [u‘<title>Open Directory - Computers: Programming: Languages: Python: Books</title>‘]
In [3]: response.xpath(‘//title/text()‘)
Out[3]: [<Selector xpath=‘//title/text()‘ data=u‘Open Directory - Computers: Programming:‘>]
In [4]: response.xpath(‘//title/text()‘).extract()
Out[4]: [u‘Open Directory - Computers: Programming: Languages: Python: Books‘]
In [5]: response.xpath(‘//title/text()‘).re(‘(\w+):‘)
Out[5]: [u‘Computers‘, u‘Programming‘, u‘Languages‘, u‘Python‘]
现在,我们来尝试从这些页面中提取些有用的数据。
您可以在终端中输入 response.body 来观察HTML源码并确定合适的XPath表达式。不过,这任务非常无聊且不易。您可以考虑使用Firefox的Firebug扩展来使得工作更为轻松。详情请参考 使用Firebug进行爬取 和 借助Firefox来爬取 。
在查看了网页的源码后,您会发现网站的信息是被包含在 第二个 <ul> 元素中。
我们可以通过这段代码选择该页面中网站列表里所有 <li> 元素:
response.xpath(‘//ul/li‘)
网站的描述:
response.xpath(‘//ul/li/text()‘).extract()
网站的标题:
response.xpath(‘//ul/li/a/text()‘).extract()
以及网站的链接:
response.xpath(‘//ul/li/a/@href‘).extract()
之前提到过,每个 .xpath() 调用返回selector组成的list,因此我们可以拼接更多的 .xpath() 来进一步获取某个节点。我们将在下边使用这样的特性:
for sel in response.xpath(‘//ul/li‘):
title = sel.xpath(‘a/text()‘).extract()
link = sel.xpath(‘a/@href‘).extract()
desc = sel.xpath(‘text()‘).extract()
print title, link, desc
在我们的spider中加入这段代码:
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath(‘//ul/li‘):
title = sel.xpath(‘a/text()‘).extract()
link = sel.xpath(‘a/@href‘).extract()
desc = sel.xpath(‘text()‘).extract()
print title, link, desc
现在尝试再次爬取dmoz.org,您将看到爬取到的网站信息被成功输出:
scrapy crawl dmoz
Item 对象是自定义的python字典。 您可以使用标准的字典语法来获取到其每个字段的值。(字段即是我们之前用Field赋值的属性):
>>> item = DmozItem()
>>> item[‘title‘] = ‘Example title‘
>>> item[‘title‘]
‘Example title‘
为了将爬取的数据返回,我们最终的代码将是:
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
for sel in response.xpath(‘//ul/li‘):
item = DmozItem()
item[‘title‘] = sel.xpath(‘a/text()‘).extract()
item[‘link‘] = sel.xpath(‘a/@href‘).extract()
item[‘desc‘] = sel.xpath(‘text()‘).extract()
yield item
现在对dmoz.org进行爬取将会产生 DmozItem 对象:
[scrapy] DEBUG: Scraped from <200 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
{‘desc‘: [u‘ - By David Mertz; Addison Wesley. Book in progress, full text, ASCII format. Asks for feedback. [author website, Gnosis Software, Inc.\n],
‘link‘: [u‘http://gnosis.cx/TPiP/‘],
‘title‘: [u‘Text Processing in Python‘]}
[scrapy] DEBUG: Scraped from <200 http://www.dmoz.org/Computers/Programming/Languages/Python/Books/>
{‘desc‘: [u‘ - By Sean McGrath; Prentice Hall PTR, 2000, ISBN 0130211192, has CD-ROM. Methods to build XML applications fast, Python tutorial, DOM and SAX, new Pyxie open source XML processing library. [Prentice Hall PTR]\n‘],
‘link‘: [u‘http://www.informit.com/store/product.aspx?isbn=0130211192‘],
‘title‘: [u‘XML Processing with Python‘]}
接下来, 不仅仅满足于爬取 Books 及 Resources 页面, 您想要获取获取所有 Python directory 的内容。
既然已经能从页面上爬取数据了,为什么不提取您感兴趣的页面的链接,追踪他们, 读取这些链接的数据呢?
下面是实现这个功能的改进版spider:
import scrapy
from tutorial.items import DmozItem
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/",
]
def parse(self, response):
for href in response.css("ul.directory.dir-col > li > a::attr(‘href‘)"):
url = response.urljoin(response.url, href.extract())
yield scrapy.Request(url, callback=self.parse_dir_contents)
def parse_dir_contents(self, response):
for sel in response.xpath(‘//ul/li‘):
item = DmozItem()
item[‘title‘] = sel.xpath(‘a/text()‘).extract()
item[‘link‘] = sel.xpath(‘a/@href‘).extract()
item[‘desc‘] = sel.xpath(‘text()‘).extract()
yield item
现在, parse() 仅仅从页面中提取我们感兴趣的链接,使用 response.urljoin 方法构造一个绝对路径的URL(页面上的链接都是相对路径的), 产生(yield)一个请求, 该请求使用 parse_dir_contents() 方法作为回调函数, 用于最终产生我们想要的数据.。
这里展现的即是Scrpay的追踪链接的机制: 当您在回调函数中yield一个Request后, Scrpay将会调度,发送该请求,并且在该请求完成时,调用所注册的回调函数。
基于此方法,您可以根据您所定义的跟进链接的规则,创建复杂的crawler,并且, 根据所访问的页面,提取不同的数据.
一种常见的方法是,回调函数负责提取一些item,查找能跟进的页面的链接, 并且使用相同的回调函数yield一个 Request:
def parse_articles_follow_next_page(self, response):
for article in response.xpath("//article"):
item = ArticleItem()
... extract article data here
yield item
next_page = response.css("ul.navigation > li.next-page > a::attr(‘href‘)")
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse_articles_follow_next_page)
上述代码将创建一个循环,跟进所有下一页的链接,直到找不到为止 – 对于爬取博客、论坛以及其他做了分页的网站十分有效。
最简单存储爬取的数据的方式是使用 Feed exports:
scrapy crawl dmoz -o items.json
该命令将采用 JSON 格式对爬取的数据进行序列化,生成 items.json 文件。
在类似本篇教程里这样小规模的项目中,这种存储方式已经足够。 如果需要对爬取到的item做更多更为复杂的操作,您可以编写 Item Pipeline 。 类似于我们在创建项目时对Item做的,用于您编写自己的 tutorial/pipelines.py 也被创建。 不过如果您仅仅想要保存item,您不需要实现任何的pipeline。
大家可以看看我写的Scrapy爬取美女图片 (原创)和Scrapy爬取美女图片续集 (原创),肯定能实现Scrapy的入门。
代码上传到github上了-- https://github.com/qiyeboy/
今天的分享就到这里,如果大家觉得还可以呀,记得打赏呦。

欢迎大家支持我公众号:

本文章属于原创作品,欢迎大家转载分享。尊重原创,转载请注明来自:七夜的故事 http://www.cnblogs.com/qiyeboy/
标签:
原文地址:http://www.cnblogs.com/qiyeboy/p/5487556.html