标签:
1、Dom4j是当下比较流行的用来帮助解析xml文件的jar。
下载地址: http://www.dom4j.org/dom4j-1.6.1/ 点击download now就可以下载了。
2、使用概览:
首先,在下载的文件中 docs/index.html中有详细的解释说明,可以参考学习。
2.1 XML File -> document (Read the XML File)
SAXReader saxReader = new SAXReader(); Document document = saxReader.read(new File("four.xml"));
2.2 Using Iterators
// iterate through child elements of root for ( Iterator i = root.elementIterator(); i.hasNext(); ) { Element element = (Element) i.next(); // do something } // iterate through child elements of root with element name "foo" for ( Iterator i = root.elementIterator( "foo" ); i.hasNext(); ) { Element foo = (Element) i.next(); // do something } // iterate through attributes of root for ( Iterator i = root.attributeIterator(); i.hasNext(); ) { Attribute attribute = (Attribute) i.next(); // do something }
2.3 递归遍历:
public void treeWalk(Element element) { for ( int i = 0, size = element.nodeCount(); i < size; i++ ) { Node node = element.node(i); if ( node instanceof Element ) { treeWalk( (Element) node ); } else { // do something.... } } }
2.4 创建document:
1.读取XML文件,获得document对象 AXReader reader = new SAXReader(); Document document = reader.read(new File("csdn.xml")); 2.解析XML形式的文本,得到document对象. String text = "<csdn></csdn>"; Document document = DocumentHelper.parseText(text); 3.主动创建document对象. Document document = DocumentHelper.createDocument(); Element root = document.addElement("csdn");
2.5 document/element/node转换为String(其实都用到一个函数,就是asXML)
String text = document.asXML();
2.6 写XML文件:(两种方式)
第一种:简易格式:(不考虑编码,不考虑格式) XMLWriter xmlWriter = new XMLWriter(new FileWriter("four.xml"); xmlWriter.write(document); xmlWriter.close(); 第二种:精确格式:(考虑编码,考虑格式) OutputFormat of = OutputFormat.createPrettyPrint(); //OutputFormat of = new OutputFormat(); of.setEncoding("utf-8"); XMLWriter xmlWriter = new XMLWriter(new FileWriter("four.xml"), of); xmlWriter.write(document); xmlWriter.close();
注意:通常我们设置了输出文件的字符格式,仍要主要java文件的字符格式是什么,如果两者不一致,依然会产生中文乱码错误。
java文件的编码通常为GBK,调整在window->preference下:
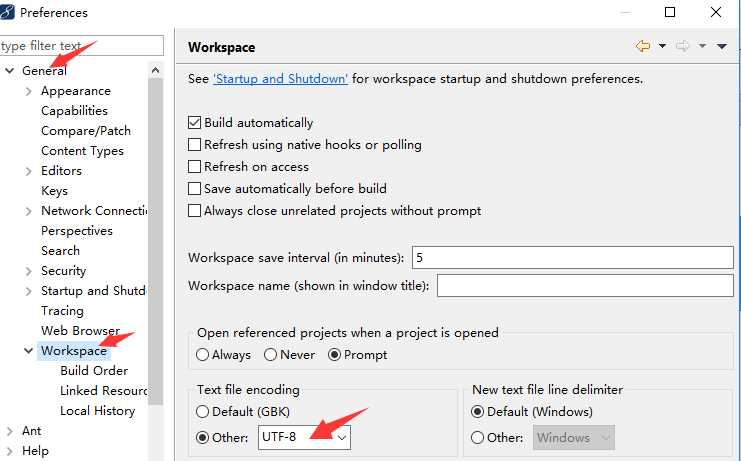
2.7:节点操作对象方法:转自: http://blog.csdn.net/redarmy_chen/article/details/12969219
1.获取文档的根节点. Element root = document.getRootElement(); 2.取得某个节点的子节点. Element element=node.element(“四大名著"); 3.取得节点的文字 String text=node.getText(); 4.取得某节点下所有名为“csdn”的子节点,并进行遍历. List nodes = rootElm.elements("csdn"); for (Iterator it = nodes.iterator(); it.hasNext();) { Element elm = (Element) it.next(); // do something } 5.对某节点下的所有子节点进行遍历. for(Iterator it=root.elementIterator();it.hasNext();){ Element element = (Element) it.next(); // do something } 6.在某节点下添加子节点 Element elm = newElm.addElement("朝代"); 7.设置节点文字. elm.setText("明朝"); 8.删除某节点.//childElement是待删除的节点,parentElement是其父节点 parentElement.remove(childElment); 9.添加一个CDATA节点. Element contentElm = infoElm.addElement("content"); contentElm.addCDATA(“cdata区域”); 来自 <http://blog.csdn.net/redarmy_chen/article/details/12969219>
2.8:节点对象属性操作:转自: http://blog.csdn.net/redarmy_chen/article/details/12969219
1.取得某节点下的某属性 Element root=document.getRootElement(); //属性名name Attribute attribute=root.attribute("id"); 2.取得属性的文字 String text=attribute.getText(); 3.删除某属性 Attribute attribute=root.attribute("size"); root.remove(attribute); 4.遍历某节点的所有属性 Element root=document.getRootElement(); for(Iterator it=root.attributeIterator();it.hasNext();){ Attribute attribute = (Attribute) it.next(); String text=attribute.getText(); System.out.println(text); } 5.设置某节点的属性和文字. newMemberElm.addAttribute("name", "sitinspring"); 6.设置属性的文字 Attribute attribute=root.attribute("name"); attribute.setText("csdn"); 来自 <http://blog.csdn.net/redarmy_chen/article/details/12969219>
标签:
原文地址:http://www.cnblogs.com/yanwenxiong/p/5493192.html