标签:
先声明一下DOM2中NodeIterator和TreeWalker这两类型真的只是用来玩玩的,因为性能不行遍历起来超级慢,在JS中基本用不到它们,除了《高程》上有两三页对它的讲解外,谷歌的学习资料也是甚少(倒是有挺多国外文章)...由于本着不放过任何知识的态度,结合着自己的理解学习了下这两玩意,你们对这两东西了解了解就好~
DOM2级遍历和范围模块定义了两个用于完成顺序遍历DOM结构的类型:NodeIterator和TreeWalker。这两类型基于给定起点对DOM结构执行深度优先先序遍历,兼容性>IE8和高版本其他浏览器可访问。
NodeIterator:
使用document.createNodeIterator(root, whatShow, filter, entityReferenceExpansion)创建NoedIterator类型实例iterator,所以原型链关系为:
iterator.__proto__->NodeIterator.prototype->Object.prototye
TreeWalker:
使用document.createTreeWalker(root, whatShow, filter, entityReferenceExpansion)创建TreeWalker类型实例walker,所以原型链关系为:
walker.__proto__->TreeWalker.prototype->Object.prototype
对比下来,其实就两个方法常用,nextNode()和previousNode()。TreeWalker.prototype比NodeIterator.prototype多了一些在不同方向上遍历的方法也就没什么了。
(1).在每个iterator中有一个内部指针指向根节点,nextNode方法是返回遍历器内部指针所在节点,然后会将指针移向下一个节点。previousNode()方法是先将指针移向上一个节点,然后返回该节点。所以nextNode()==previousNode()
(2).在每个walker中也有一个内部指针,但是指向根节点的第一个子节点,nextNode方法是返回遍历器所在节点然后并不移动指针(就是说指针和节点在同一处),previous()方法是先将指针移向上一个节点,然后返回该节点,所以这里nextNode() != previous()
所以TreeWalker.prototype就有一个currentNode属性,表示在上一次遍历中返回的节点: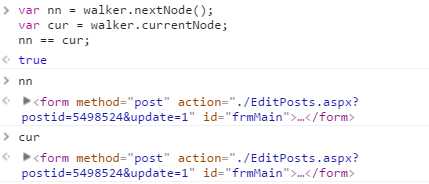
(3).区别说完,说说它两的参数都是相同的:
root:想要作为搜索起点的树中的节点
whatToShow:表示要访问哪些节点的数字代码,来自NodeFilter.prototype还是NodeFilter自身上中的这些大写常量...
filter:是NodeFilter类型实例对象,或者是一个表示应该接受还是拒绝某种特定节点的函数。作用是当调用nextNode或previousNode时候要经过这个过滤器来删选想要的节点,如果说文档中任何一个节点走一步,那么根据筛选节点类型不同每次返回的节点实际上可能走了好几步。
entityReferenceExpansion:表示是否要扩展实体引用,false就好。
对了,NodeIterator和TreeWalker还有一点区别就是在使用NodeIterator对象时,NodeFilter.FILTER_SKIP和NodeFilter.FILTER_REJECT作用相同跳过指定节点。在使用TreeWalker对象时,NodeFilter.FILTER_SKIP会跳过相应节点继续前进到子树中下一个节点,NodeFilter.FILTER_REJECT会相应节点及该节点的整个子树。
OK!说完了上面的,也不知道大家有没有懂~不懂没关系反正这两类型也不常用,效率也差~
通过DOM遍历的这两类型很容易让人想到我们常用的document.getElementById,document.getElementsByTagName,document.getElementsByNames...系列方法不是也是在DOM中搜寻指定节点的么...这里用NodeIterator来实现一下
Document.prototype.getElementById = function(id){ var filter = function(node){ return node.id == id ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; } var iterator = document.createNodeIterator(document, NodeFilter.SHOW_ELEMENT, filter, false); var node = iterator.nextNode(); return node; } Document.prototype.getElementsByTagName = function(tagname){ var filter = function(node){ return node.tagName.toLowerCase() == tagname ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; } var htmlcollection = []; var iterator = document.createNodeIterator(document, NodeFilter.SHOW_ELEMENT, filter, false); var node = iterator.nextNode(); while(node!=null){ htmlcollection.push(node); node = iterator.nextNode(); } htmlcollection.__proto__ = HTMLCollection.prototype; return htmlcollection; }

成功!其他的方法类似的,感兴趣可以自行实现~
stackoverflow里有人提出了When to use NodeIterator? 把querySelector和filter过滤进行比较,这谁快谁慢光看名字就显而易见嘛,感兴趣可以看看啊~我粗略测试下
也不知道人家JS引擎中getElementById真正是怎么实现的,改天抽空看看~
参考
《JavaScript高级程序设计》
玩转DOM遍历——用NodeIterator实现getElementById,getElementsByTagName方法
标签:
原文地址:http://www.cnblogs.com/venoral/p/5499358.html