标签:
二刷《高程》做的笔记,没什么技术含量就不发到首页啦!~
DOM1级主要定义HTML和XML文档底层结构,DOM2和DOM3在这个结构基础上引入更多交互能力,也支持更高级的XML特性。DOM2和DOM3级分为许多模块(模块之间具有某种关联),分别描述DOM的某个非常具体的子集。这些模块如下:
DOM变化
DOM2和DOM3级的目的是扩展DOM API,以满足操作XML的所有需求,同时提供更好的错误处理和特性检测能力,从某种意义上讲实现这一目的很大程度意味着对命名空间的支持。
DOM2级核心没有引入新类型,只是在DOM1级基础上通过增加新方法和新属性来增强既有类型。
DOM3级核心同样增强即有类型,但也引入一些新类型。
DOM2级视图和DOM2级HTML也增强了DOM接口,提供了新的属性和方法。
(1)针对XML命名空间的变化:有了XML命名空间,不同XML文档的元素就可以混合在一起使用,共同构成格式良好的文档,而不用担心发生命名冲突。从技术上讲,HTML不支持XML命名空间,但XHTML支持XML命名空间。命名空间要使用 xmlns 特性来指定,XHTML的命名空间是http://www.w3.org/1999/xhtml,在任何格式良好的XHTML页面中,都应该将其包含在<html>元素中
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Example XHTML Pages</title> </head> <body> Hello! </body> </html>
该例中其中所有元素默认都被视为XHTML命名空间中的元素,想为XML命名空间创建前缀可以 xmlns:前缀 ="http://www/w3/org/1999/xhtml"
<xhtml:html xmlns:xhtml="http://www.w3.org/1999/xhtml"> <xhtml:head> <xhtml:title>Example XHTML page</xhtml:title> </xhtml:head> <xhtml:body xhtml:class="home"> Hello </xhtml:body> </xhtml:html>
这里为XHTML的命名空间定义了一个名为xhtml的前缀,并要求所有XHTML元素都以该前缀开头,在避免不同语言间的冲突时需要使用命名空间来限定特性。例如混合了XHTML和SVG语言的文档:
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>Example XHTML Page</title> </head> <body> <s:svg xmlns:s="http://www.w3.org/2000/svg" version="1.1" viewBox="0 0 100 100" style="width:100%;height:100%"> <s:rect x="0" y="0" width="100" height="100" style="fill:red"/> </s:svg> </body> </html>
该例中设置命名空间将<svg>标识为了与包含文档无关的元素,此时svg元素的所有子元素以及这些元素的所有特性都被认为属于http://www.w3.org/2000/svg命名空间,即使这个文档从技术上说是一个XHTML文档,但因为有了命名空间,其中的SVG代码也仍然是有效的。对于这类文档最有意思的是调用方法操作文档节点,例如创建一个元素这个元素属于哪个命名空间呢?DOM2级核心通过为大多数DOM1级方法提供特定于命名空间的版本解决了这个问题。
(2)其他方面的变化:DOM的其他部分在DOM2级核心上中也发生了些变化,这些变化与XML命名无关,而是更倾向于确保API的可靠性及完整性。

var parentWindow = document.defaultView || document.parnetWindow;
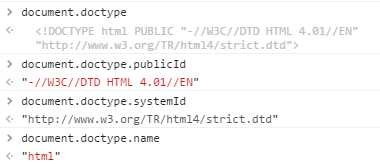
(3).DOM2级核心还为document.implementation对象规定了两个新方法:createDocumentType,createDocument,均继承自DOMImplementation.prototype。
createDocumentType(doctypename, publicId, systemId):创建一个新的DocumentType节点,三个参数文档类型名称,publicId,systemId。如下面代码会创建一个新的HTML4.01 Strict文档类型
var doctype = document.implementation.createDocumentType(‘html‘, "-//W3C//DTD HTML 4.01//EN", "http://www.w3.org/TR/html4/strict.dtd");
由于既有文档的文档类型不能改变因此createDocumentType只在创建新文档时有用。
createDocument(namespaceURI, tagName, doctype):创建新文档,三个参数:namespaceURI,文档元素的标签名,新文档的文档类型。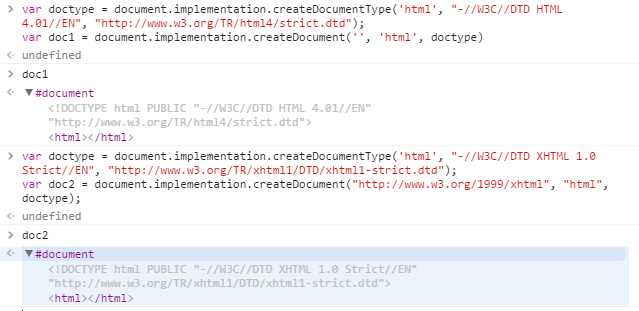
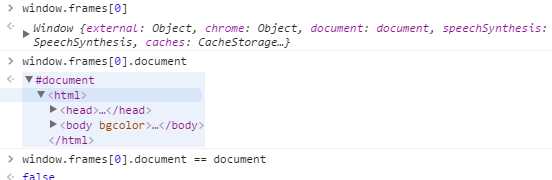
(4).DOM2级HTML模块也为document.implementation增加了一个方法,叫createHTMLDocument(title),它的用途是创建一个完整的HTML文档,包括<html>,<head>,<title>,<body>元素。参数为文档的标题(放在title元素中的字符串),返回新的HTML文档实例(原型为HTMLDocumetn.prototype,因而继承该原型链上的所有属性和方法,包括title和body,均在Document.prototype上):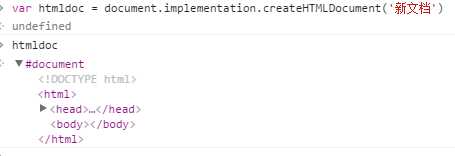
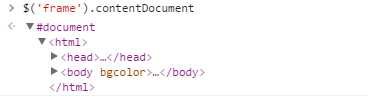
var iframe = document.getElementById(‘myIframe‘); var iframeDoc = iframe.contentDocument || iframe.contentWindow.document;
但要注意:访问框架或内嵌框架的文档对象要受到跨域安全策略的限制,如果某个框架中的页面来自其他域或不同域,或者使用了不同协议,那么要访问这个框架的文档对象就会导致错误。
样式
在HTML中定义样式方式有三种,通过link元素包含外部样式表文件,使用style元素定义嵌入样式表,使用style特性定义针对特定元素的样式。DOM2级样式模块围绕这三种应用样式的机制提供了一套API。
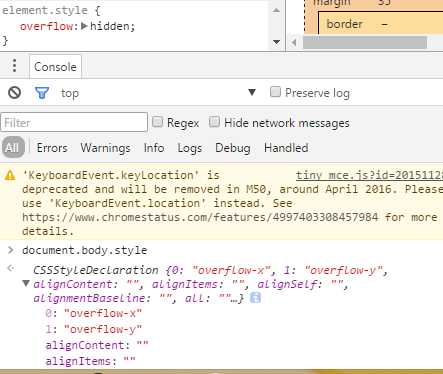
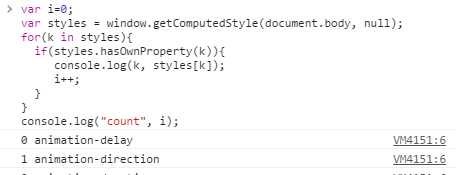
var i=0; var styles = document.body.style; for(k in styles){ if(styles.hasOwnProperty(k)){ console.log(k, styles[k]); i++; } } console.log("count", i); //控制台结果 0 overflow-x 1 overflow-y 2 font-size alignContent ‘‘ alignItems ‘‘ alignSelf ‘‘ alignmentBaseline ‘‘ all ‘‘ animation ‘‘ ...
overflow hidden
overflowWrap ‘‘
overflowX hidden
overflowY hidden
... zoom ‘‘ cssFloat ‘‘ count 358

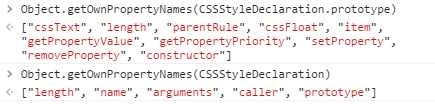
for(var i=0,len = document.body.style.length; i<len; i++){ console.log(document.body.style[i]); } // overflow-x overflow-y font-size
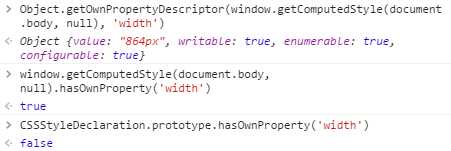
无论使用方括号语法还是item方法都可以取得被设置在style特性上的css属性名(是background-color不是backgroundColor)。然后可以在getPropertyValue()中使用取得的属性名进一步取得属性值。
var prop, value, i, len; for(i=0,len = document.body.style.length; i<len; i++){ prop = document.body.style[i]; value = document.body.style.getPropertyValue(prop); console.log(prop, value); } // overflow-x hidden overflow-y hidden font-size 16px




CSSStyleSheet更加通用些,它只表示样式表,而不管这些样式表在HTML中是如何定义的。上述两个针对元素的类型允许修改HTML特性,但CSSStyleSheet对象则是一个只读接口(个别属性除外)。
原型链继承关系:document.styleSheets.__proto__->StyleSheetList.prototype->Object.prototype
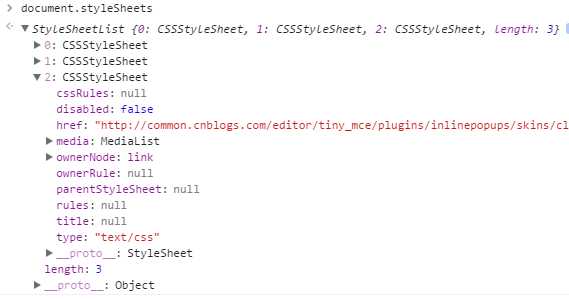
应用于文档的所有样式表是通过document.styleSheets集合来表示的,通过这个集合的length属性(继承自StyleSheetList.prototype)可以获知文档中样式表的数量。通过[]或item方法(继承自StyleSheetList.prototype)可以访问每一个样式表。styleSheets属性继承自Document.prototype。
var sheet =null; for(var i=0, len = document.styleSheets.length; i<len; i++){ sheet = document.styleSheets[i]; console.log(sheet.href); }
可以看出,document.styleSheet的实例里的每一项都是CSSStyleSheet的实例
document.styleSheet[0].__proto__->CSSStyleSheet.prototype->StyleSheet.prototype->Object.prototype。
(1).StyleSheet.prototype上的:
除了disabled属性外,其他属性都是只读的
disabled:表示样式表是否被禁用的布尔值。这个属性是可读写的(get/set)的,将这个值设置为true可以禁用样式表。
href:如果样式表是通过<link>包含的,则是样式表的url,否则是null。(undefined/get)
media:当前样式表支持的所有媒体类型的集合。它的值为MediaList的实例,原型链关系为
document.styleSheets[0].media.__proto__-> MediaList.prototype->Object.prototype
如果集合是空列表表示适用于所有媒体。在<=IE8中,media是一个反映<link>和<style>元素media特性值的字符串。
ownerNode:指向拥有当前样式表的节点的指针,样式表可能是在HTML中通过link或style元素引入的(在XML中可能是通过处理指令引入的)。如果当前样式表是其他样式表通过@import导入的,则这个属性值为null。<=IE8不支持这个属性。
parentStyleSheet:在当前样式表是通过@import导入情况下,这个属性是一个指向导入它的样式表的指针。
title:ownerNode中title特性的值。
type:表示样式表类型的字符串,对css样式表来说这个字符串是“type/css”
(2).CSSStyleSheet.prototype上的:
cssRules:规则们,样式表中包含的样式规则的集合。其中每一项都是CSSStyleRule的实例,
原型链继承关系为:document.styleSheets[0].cssRules[0].__proto__->CSSStyleRule.prototype->CSSRule.protoype->Object.prototype
<=IE8不支持该属性,但有一个类似的rules属性。
ownerRule:如果样式表是通过@import导入的,这个属性就是一个指针,指向表示导入的规则,否则值为null,<=IE8不支持该属性。
deleteRule(index):删除cssRules集合中指定位置的规则,<=IE8不支持这个规则,但支持类似的removeRule方法。
insertRule(rule, index):向cssRules集合中指定的位置插入rule字符串。<=IE8不支持这个规则,但支持一个类似的addRule()方法。
不同浏览器的document.styleSheets返回的样式表也不同,所有浏览器都会包含<style>元素和rel特性被设置为‘stylesheet’的<link>元素引入的样式表。IE和Opera也包含rel特性被设置为“alternate stylesheet”的<link>元素引入的样式表。
也可以通过<link>或<style>元素取得CSSStyleSheet对象。DOM中规定了一个包含CSSStyleSheet对象的属性,为sheet(在HTMLLinkElement.prototype和HTMLStyleElement.prototype上)。除了<=IE8其他浏览器都支持这个属性,但所有的IE有个styleSheet属性,兼容性代码:
function getStyleSheet(ele){ return ele.sheet || ele.styleSheet; } var link = document.getElementsByTagName(‘link‘)[0]; var sheet = getStyleSheet(link);
(1).css规则:CSSRule对象表示样式中每一条规则,实际上CSSRule是一个供其他多种类型继承的基类型,其中最常见的就是CSSStyleRule类型,表示样式信息。
CSSRule.prototype包含下列属性:
cssText:返回整条规则对应的文本。但浏览器对样式表的内部处理方式不同,返回的文本可能与样式表中实际的文本不一样。 Safari始终会将文本转换为全部小写,<=IE8不支持这个属性。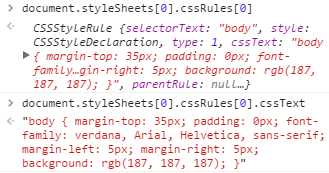
parentRule:如果当前规则是导入的规则,这个属性引用的就是导入规则;否则这个值为null。<=IE8不支持这个属性
parentStyleSheet:当前规则所属的样式表,<=IE8不支持这个属性。
type:表示规则类型的常量值,对于样式规则这个值是1,对于@import导入的规则这个值为3。<=IE8不支持这个属性。
CSSStyleRule.prototype上的:
selectorText:返回当前规则的选择符文本,由于浏览器对样式表的内部处理方式不同,返回的文本可能会与样式表中实际的文本不一样(Safari3之前的版本始终会将文本转换成全部小写)。<=IE8不支持这个属性。
style:一个CSSStyleDeclaration对象,可以通过它设置和取得规则中特定的样式值。
最常用的三个属性是cssText,selectorText,style。这里document.styleSheets[0].cssRules[0].cssText和document.getElementsByTagName(‘body‘)[0].style.cssText不一样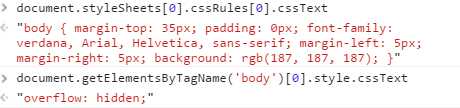
前者包含选择符文本和围绕样式信息的花括号,后者只包含样式信息。大多数情况下仅使用style属性就可以满足所有操作样式规则的需求了。
通过样式规则也可修改样式,但以这种方式修改规则会影响页面中适用于该规则的所有元素。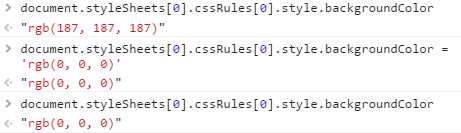
(2).创建规则:DOM规定要向现有样式表中添加新规则,需要使用insertRule(rule, idx)方法,两个参数:规则文本和表示在哪里插入规则的索引,插入的规则将成为第idx条规则。IE早期版本支持addRule(selectorstr, styleinfo, idx)方法:三个参数,选择符文本,css样式信息,插入规则的位置(可选)。跨浏览器代码:
/* sheet: 样式表 selectorText:选择符文本 cssText:css样式信息 position:插入规则的位置 */ function insertRule(sheet, selectorText, cssText, position){ if(sheet.insertRule){ sheet.insertRule(selectorText + ‘{‘ + cssText + ‘}‘, position); }else if(sheet.addRule){ sheet.addRule(selectorText, cssText, position); } }
虽然这样可以动态添加规则但要添加的规则若是多还是建议使用动态加载样式表的技术。
(3).删除规则:从样式表中删除规则的方法,deleteRule(idx),参数为要删除规则的位置,IE支持一个removeRule(idx)。跨浏览器代码
function deleteRule(sheet, idx){ if(sheet.deleteRule){ sheet.deleteRule(idx); }else if(sheet.removeRule){ sheet.removeRule(idx); } }
考虑到删除规则可能会影响CSS层叠的效果,不推荐使用。
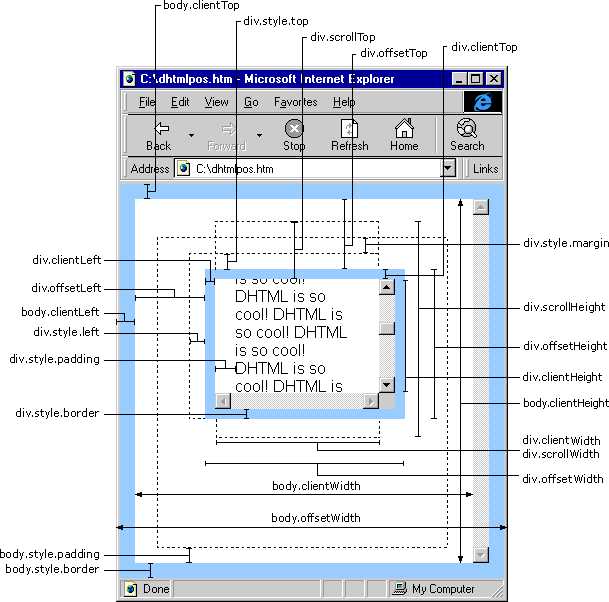
function getElementLeft(ele){ var actualLeft = ele.offsetLeft; var current = ele.offsetParent; while(current !== null ){ actualLeft += current.offsetLeft; current = current.offsetParent; } return actualLeft; } function getElementTop(ele){ var actualTop = ele.offsetTop; var current = ele.offsetParent; while(current !== null){ actualTop += current.offsetTop; current = current.offsetParent; } return actualTop; }
这两个函数利用offsetParent属性在DOM层次中逐级向上回溯,将每个层次中的偏移量属性合计到一块,对于简单的css页面这两个函数可以得到精确结果,对于表格和内嵌框架布局的页面,由于不同浏览器实现这些元素的方式不同因此得到的值不太精准。
所有这些偏移量属性都是只读的,而且每次访问它们都需要重新计算。因此该尽量避免重复访问这些属性。如果需要重复使用其中某些属性的值,可以将它们保存在局部变量中,以提高性能。
function getView(){ if(document.compatMode == ‘BackCompat‘){ //<IE7之前版本document.documentElement.clientWidth会返回0 return { width : document.body.clientWidth, height : document.body.clientHeight } }else{ return { width : document.documentElement.clientWidth, height : document.documentElement.clientHeight } }
}
与偏移量相似,客户区的大小也是只读的,每次访问得重新计算。
(3).滚动大小:包含滚动内容的元素的大小。有些元素(例如html元素,我对高程上这块说的html有点异议,在Chrome下测试document.documentElement.scrollTop = 20;并没有什么卵用,但给body元素设置就可以),即使没有执行任何代码也能自动地添加滚动条,但另外一些元素,则需要通过css的overflow属性进行设置才能滚动。下面四个均继承自Element.protptype
var docHeight = Math.max(document.documentElement.scrollHeight, document.documentElement.clientHeight); var docWidth = Math.max(document.documentElement.scrollWidth, document.documentElement.clientWidth);
就算这样我觉得也还是不精准,万一碰上像上图那样html元素高度为0,这获取文档高度就成clientHeight视口高度了,所以页面中一定要注意html元高度是否为0,高程上给的html这个元素太绝对了,我觉得应该是给包裹整个文档的元素才能由scrollHeight正确得到当前文档实际的高度。
(4).确定元素大小:多数浏览器提供了getBoundingClientRect()方法(继承自Element.prototype),这个方法返回一个ClientRect实例对象,这个对象包含四个属性:left,top,right,bottom,给出了元素在页面中相对于视口的位置。原型链继承关系为:document.body.getBoundingClientRect().__proto__->ClientRect.prototype->Object.prototype。
function getBoundingClientRect(ele){ if(typeof arguments.callee.offset != ‘number‘){ var scrollTop = document.documentElement.scrollTop; var temp = document.createElement(‘div‘); temp.style.cssText = "position:absolute; left:0; top:0"; document.body.appendChild(temp); arguments.callee.offset = -temp.getBoundingClientRect().top - scrollTop; document.body.removeChild(temp); temp = null; } var rect = ele.getBoundingClientRect(); var offset = arguments.callee.offset; return { left: rect.left + offset, right: rect.right + offset, top: rect.top + offset, bottom: rect.bottom + offset }; }
对于不支持getBoundingClientRect的浏览器可以通过其他手段取得相同信息,一般来说right和left的差值与offsetWidth值相等,bottom和top的差值与offsetHeight值相等。而且left和top属性大致等于前面的getElementLeft和getElementTop():综上创建下面这个跨浏览器函数(在某些情况下这个函数返回的值可能会有所不同,例如使用表格布局或使用滚动元素情况下,由于这里使用了argument.callee,所以这个方法不能在严格模式下使用)
function getBoundingClientRect(ele){ var scrollTop = document.documentElement.scrollTop; var scrollLeft = document.documentElement.scrollLeft; if(ele.getBoundingClientRect){ if(typeof arguments.callee.offset != ‘number‘){ var temp = document.createElement(‘div‘); temp.style.cssText = "position:absolute; left:0; top:0"; document.body.appendChild(temp); arguments.callee.offset = -temp.getBoundingClientRect().top - scrollTop; document.body.removeChild(temp); temp = null; } var rect = ele.getBoundingClientRect(); var offset = arguments.callee.offset; return { left: rect.left + offset, right: rect.right + offset, top: rect.top + offset, bottom: rect.bottom + offset }; }else { var actualLeft = getElementLeft(ele); var actualTop = getElementTop(ele); return { left : actualLeft - scrollLeft, right : actualLeft - scrollLeft + ele.offsetWidth, top: actualTop - scrollTop, bottom: actualTop- scrollTop +ele.offsetHeight } } }
遍历
DOM2级遍历和规范模块定义了两个用于辅助完成顺序遍历DOM结构的类型:NodeIterator和TreeWalker。这两个类型能够基于给定的起点对DOM结构执行深度优先的的遍历操作。<=IE8不支持DOM遍历,且在>IE8中 typeof NodeIterator == ‘object‘; typeof TreeWalker == ‘object‘; Chrome下是‘function‘。任何节点都可作为遍历的根节点,如果假设以html元素作为根节点,那么遍历的第一步就是访问head元素,第二部就是title节点...以document为根节点的遍历可以访问到文档中的全部节点,从document节点开始依序向前,访问的第一个节点是document,从文档最后节点开始,遍历可以反向移动到DOM树的顶端,NodeIterator和TreeWalker都以这种方式遍历
(1).NodeIterator:原型链继承关系为:document.createNodeIterator().__proto__->NodeIterator.prototypr->Object.prototype
NodeFilter.prototype->Object.prototype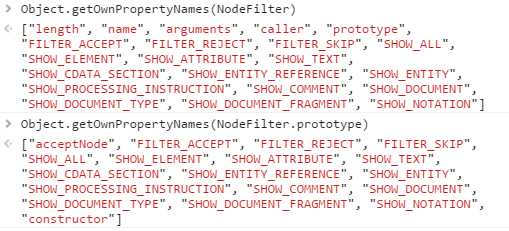
可以通过document.createNodeIterator(root, whatToShow, filter, entityReferenceExpansion)方法创建NodeIterator的实例,四个参数
root:想要作为搜索起点的树中的节点
whatToShow:表示想要访问哪些节点的数字代码,是一个位掩码,通过应用一个或多个过滤器来确定要访问哪些节点。这个参数值以常量形式在NodeFilter类型中定义,如下:
NodeFilter.SHOW_ALL:显示所有类型节点,4294967295
NodeFilter.SHOW_ELEMENT:显示元素节点,1
NodeFilter.SHOW_ATTRIBUTE:显示特性节点,由于DOM结构原因,实际上不能使用这个值,2
NodeFilter.SHOW_TEXT:显示文本节点,4
NodeFilter.SHOW_CDATA_SECTION:显示CDATA节点,对HTML页面没有用,8
NodeFilter.SHOW_ENTITY_REFERENCE:显示实体引用节点,对HTML页面没有用,16
NodeFilter.SHOW_ENTITY:显示实体节点,对HTML页面没有用,32
NodeFilter.SHOW_PROCESSING_INSTRUCTION:显示处理指令节点,对HTML页面没有用,64
NodeFilter.SHOW_COMMENT:显示注释节点,128
NodeFilter.SHOW_DOCUMENT:显示文档节点,256
NodeFilter.SHOW_DOCUMENT_TYPE:显示文档类型节点,512
NodeFilter.SHOW_DOCUMENT_FRAGMENT:显示文档片段节点,对HTML页面没有用,1024
NodeFilter.SHOW_NOTATION:显示符号节点,对HTML页面没有用,2048
除了NodeFilter.SHOW_ALL外,可以使用按位或操作符组合多个选项,如 var whatToShow = NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT;
filter:是一个NodeFilter实例,或者一个表示应该接受还是拒绝某种特定节点的函数。如果不指定过滤器应该在第三个参数的位置传入null
1.每个NodeFilter实例对象上继承acceptNode方法,如果应该访问该节点该方法返回NodeFilter.FILTER_ACCEPT(1),如果不应该访问给定节点该方法返回NodeFIlter.FILTERT_SKIP(3),由于NodeFilter是一个抽象类型因此不能直接创建它的实例,在必要时只要创建一个包含acceptNode方法的对象,然后将这个对象传入createNodeIterator()中即可。
var filter = { accpectNode : function(node){ return node.tagName.toLowerCase() == ‘p‘? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; } }; var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
2.这个参数也可以是一个与accpectNode方法类型的函数
var filter = function(node){ return node.tagName.toLowerCase() == ‘p‘ ? NodeFilter.FILTER_ACCEPT : NodeFIlter.FILTER_SKIP; }; var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
entityReferenceExpansion:布尔值,表示是否要扩展实体引用,这个参数在HTML页面中没有用,因为其中实体引用不能扩展。
创建一个能够访问所有类型节点的NodeIterator:
var iterator = document.createNodeIterator(document, NodeFilter.SHOW_ALL, null, false);
iterator继承了NodeIterator.prototype上的nextNode和previousNode,这两方法都是基于NodeIterator在DOM结构中的内部指针工作,所以DOM结构的变化会反映在遍历结果中。
nextNode方法先返回遍历器的内部指针所在的节点,然后会将指针移向下一个节点。所有成员遍历完成后,返回null。previousNode方法则是先将指针移向上一个节点,然后返回该节点。所以
var nodeIterator = document.createNodeIterator( document.body, NodeFilter.SHOW_ELEMENT ); var currentNode = nodeIterator.nextNode(); var previousNode = nodeIterator.previousNode(); currentNode === previousNode // true是相等的
在深度优先的DOM子树遍历中,nextNode方法用于前进一步(不是绝对的一步,而是找到filter里限定条件的那个节点为止,又可能走了好多步,所以是执行了多次过滤filter,每次过滤都会选择跳过还是接受)返回找到的那个节点,previousNode用于同理向后后退。在刚刚创建的NodeIterator对象中,有一个内部指针指向根节点,因此第一次调用nextNode会返回根节点,当遍历到DOM子树最后一个节点时nextNode返回null。previousNode工作机制类似。当遍历到DOM子树最后一个节点,且previousNode返回根节点后,再次调用它就会返回null。以下面为例:
<div id="div1">
<p><b>Hello </b> world</p>
<ul>
<li>List 1</li>
<li>List 2</li>
<li>List 3</li>
</ul>
</div>
//遍历div中所有元素 var div = document.getElementById(‘div1‘); var iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false); var node = iterator.nextNode(); // 返回根节点 while(node !== null ){ console.log(node.tagName); node = iterator.nextNode(); }
//返回li元素 var div = document.getElementById(‘div1‘); var filter = function(node){ return node.tagName.toLowerCase() == ‘li‘ ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; }; var iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, filter, false); var node = iterator.nextNode();//返回第一个li while(node !== null){ console.log(node.tagName); node = iterator.nextNode(); }
(2).TreeWalker:原型链继承关系为:document.createTreeWalker().__proto__->TreeWalker.prototype->Object.prototype

除了nextNode和previousNode外(和NodeIterator功能相同),还包括下列用于在不同方向上遍历DOM结构的方法
parentNode():遍历到当前节点的父节点
firstChild():遍历到当前节点的第一个子节点
lastChild():遍历到当前节点的最后一个子节点
nextSibling():遍历到当前节点的下一个同辈节点
previousSibling():遍历到当前节点上一个同辈节点
创建TreeWalker对象使用document.createTreeWalker()方法,四个参数同上,作为遍历起点的根节点,要显示的节点类型,过滤器,表示是否扩展实体引用的布尔值。
//替换上面的NodeIterator var div = document.getElementById(‘div1‘); var filter = function(node){ return node.tagName.toLowerCase() == ‘li‘ ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP; }; var walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, filter, false); var node = walker.nextNode(); while( node!== null){ console.log(node.tagName); node = walker.nextNode(); }
在这里filter的值可以有所不同,除了NodeFilter.FILTER_ACCEPT和NodeFilter.FILTER_SKIP之外,还可以有NodeFilter.FILTER_REJECT。在使用NodeIterator对象时,NodeFilter.FILTER_SKIP和NodeFilter.FILTER_REJECT作用相同,跳过指定节点,但在使用TreeWalker对象时,NodeFilter.FILTER_SKIP会跳过相应节点继续前进到子树中下一个节点,而NodeFilter.FILTER_REJECT则会跳过相应节点及该节点的整个子树。若将上面例子的NodeFilter.FILTER_SKIP改为NodeFilter.FILTER_REJECT,结果就是不会访问任何节点,因为当filter第一个节点div时判断是应该REJECT的,这一REJECT可把div和在其子树都跳过,而li就是在div子树中啊。所以就会停止遍历。
TreeWalker真正强大的地方在于能够在DOM结构中沿任何方向移动,使用TreeWalker遍历DOM树,即使不定义过滤器,也可以取得所有<li>元素,
var div = document.getElementById(‘div1‘); var walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false); walker.firstChild(); //返回当前节点div的第一个子节点p walker.nextSibling();// 返回当前节点下一个同辈节点 ul var node = walker.firstChild();// 转到第一个<li> while(node !== null){ console.log(node.tagName); node = walker.nextSibling(); }
因为我们知道<li>元素在文档中的位置,所以可以直接定位到那里,因为使用了NodeFilter.SHOW_ELEMENT,所以只会返回元素不必担心使用nextSibling返回文本节点,nextSibling最终会返回null。
TreeWalker类型还有个currentNode属性,表示任何遍历方法在上一次遍历中返回的节点,通过设置这个属性也可以修改遍历继续进行的起点。
还可以修改起点,下次过滤就是从body的第一个子元素过滤了。
范围
1.DOM中的范围:
DOM2级遍历和范围模块定义了范围接口,通过范围可以选择文档中一个区域,不必考虑节点的界限(选择在后台完成,对用户是不可见的)。在常规的DOM操作不能有效的修改文档时,使用范围往往可达到目的。
多数浏览器均支持DOM范围,<=IE8以专有方式实现了自己的范围特性。
DOM中的范围:DOM2级在Document.prototype上定义了createRange方法,原型链继承关系为:document.createRange().__proto__->Range.prototype->Object.prototype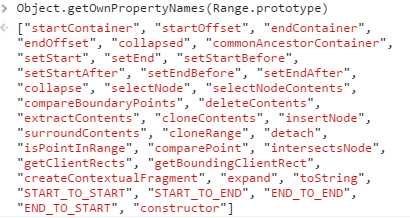
新创建的范围直接与创建它的文档关联在一起,不能用于其他文档。创建了范围后就可以使用它在后台选择文档中特定部分。创建了范围并设置了其位置之后还可以针对范围的内容执行很多种操作,从而实现对底层DOM树的更精细的控制。
startContainer:包含范围起点的节点(选中区第一个节点的父节点)
startOffset:范围在startContainer中起点的偏移量,如果startContainer是文本节点,注释节点,CDATA节点,那么startOffset就是范围起点之前跳过的字符数量。否则startOffset就是范围中第一个子节点的索引。
endContainer:包含范围终点的节点(选区中最后一个节点的父节点)
endOffset:范围在endContainer中终点的偏移量(与startOffset遵循相同的取值规则),可以理解为选区之外的第几个,看情况是否加一
commonAncestorContainer:startContainer和endContainer共同的祖先节点在文档树中位置最深的那个。
当把范围放到文档中特定位置时,这些属性都会被赋值。
<div> ->startContainer包含范围起点的节点 <!--注释节点--> ->范围开始,起点 <p>...</p> ->startOffset(范围在startContainer中起点的偏移量) <span>...</span> ->endOffset (范围在endContainer中终点的偏移量) <!-- 注释节点--> ->范围结束,重点 </div> ->endContainer包含范围终点的节点
(1).用DOM范围实现简单选择:
selectNode(node):选择整个节点包括其子节点
selectNodeContents(node):只选择节点的子节点
//HTML <html> <body> <p id="p1"><b>Hello</b> world!</p> </body> </html> //JS var p = document.getElementById(‘p1‘); var range1 = document.createRange(), range2 = document.createRange(); range1.selectNode(p); range2.selectNodeContents(p);

可以看到在调用selectNode时候startContainer和endContainer和commonAncestorContainer都等于传入节点的父节点,即document.body。startOffset属性等于给定节点在其父节点的childNodes集合中的索引(这个例子是1——因为兼容DOM的浏览器将空格算作一个文本节点),endOffset等于startOffset加1(因为只选择了一个节点)
在调用selectNodeContents()时候,startContainer,endContainer和commonAncestorContainer等于传入的节点,即<p>元素,startOffset等于0因为范围从给定节点的第一个子节点开始,最后endOffset等于子节点数量(node.childNodes.length)这个例子中是2。
为了更精细地控制将哪些节点包含在范围内,还可使用下列方法:
setStartBefore(refNode):将范围的起点设置在refNode之前,因此refNode也就是范围选中区第一个子节点。同时会将startContainer属性设置为refNode.parentNode,将startOffset属性设置为refNode在其父节点的childNodes中的索引。
setStartAfter(refNode):将范围的起点设置在refNode之后,因此refNode也就不在范围之内了,其下一个同辈节点才是范围选区中第一个子节点,同时会将startContainer属性设置为refNode.parentNode,将startOffset属性设置为refNode在其父节点的childNodes集合中的索引加1.(??为甚不是索引而要加1)
setEndBefore(refNode):将范围的终点设置在refNode之前,因此refNode也就不在范围之内了。其上一个同辈节点才是范围选区中最后一个子节点,同时会将endContainer属性设置为refNode.parentNode,将endOffset属性设置为ref在其父节点的childNodes集合中的索引。
setEndAfter(refNode):将范围的终点设置在refNode之后,refNode也就是范围选区中最后一个子节点。同时会将endContainer属性设置为refNode.parentNode,将endOffset属性设置为refNode节点在其父节点的childNodes集合中的索引加1。
(2).用DOM范围实现复杂选择:创建复杂的范围,使用下面两个方法,参数为参照节点和偏移量值
setStart(refNode, offset):refNode会变成startContainer,偏移量值会变成startOffset。
setEnd(refNode, offset):refNode会变成endContainer,偏移量值会变成endoffset
可以使用这两个方法来模拟selectNode和selectNodeContents()
var range1 = document.createRange(), range2 = document.createRange(); var p1 = document.getElementById(‘p1‘), p1Index = -1, i, len; for(i = 0, len = p1.parentNode.childNodes.length; i<len; i++ ){ if(p1.parentNode.childNodes[i] == p1){ p1Index = i; break; } } range1.setStart(p1.parentNode, p1Index); range1.setEnd(p1.parentNode, p1Index+1); range2.setStart(p1, 0); range2.setEnd(p1, p1.childNodes.length);
要选择这个节点(使用range1),就必须确定当前节点p1在其父节点的childNodes集合中的索引,要选择这个节点的内容(使用range2),也就不必计算什么,只要通过setStart和setEnd设置默认值即可。这两方法更胜一筹的地方在于能够选择节点的一部分。
假设你只想选择前面HTML示例代码中从“Hello”的“llo”到“world!”的“o”:
先取得所有节点的引用:
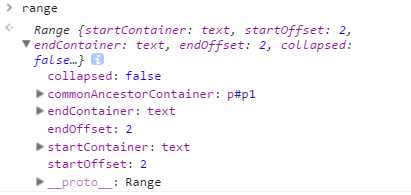
var p1 = document.getElementById(‘p1‘), helloNode = p1.firstChild.firstChild, worldNode = p1.lastChild;
然后在创建范围时指定相应的起点和终点:
var range = document.createRange(); range.setStart(helloNode, 2); range.setEnd(worldNode, 3);//3表示选区之外的第一个字符的位置
(3).操作DOM范围中的内容:在创建范围时,内部会为这个范围创建一个文档片段,范围所属的全部节点都被添加到了这个文档片段中。为了创建这个文档片段,范围内容的格式必须正确有效,在前面例子中我们创建的选区分别开始和结束两个文本节点的内部,因此不能算作是格式良好的DOM结构,也就无法通过DOM来表示,但是范围知道自身缺少哪些开标签和闭标签,它能够重新构建有效的DOM结构以便我们对其进行操作。对于这个例子,范围经过计算知道选区中缺少一个开始<b>标签,就会在后台动态加入一个该标签,同时还会在前面加入一个表示结束的</b>标签以结束“He”。于是修改后的DOM如下:
<p><b>He</b><b>llo</b> world!</p>
另外文本节点world也被拆分为两个文本节点,一个包含“wo”,一个包含“rld”。
创建了范围后就可以使用各种方法对范围的内容进行操作,例如从文档中删除范围所包含的内容:
var p1 = document.getElementById(‘p1‘), helloNode = p1.firstChild.firstChild, worldNode = p1.lastChild; var range = document.createRange(); range.setStart(helloNode, 2); range.setEnd(worldNode, 3); range.deleteContents();
执行后HTML变为:
<p><b>He</b>rld!</p>
由于范围选区在修改底层DOM结构时能保证格式良好,因此即使内容被删除了最终的DOM结构依旧良好。
与deleteContents()相似,extractContents()也会从文档中移除范围选区,但这两个方法区别在于extractContents()会返回范围的文档片段对象,利用这个返回值可以将范围的内容插入到文档中其他地方。
var p1 = document.getELementById(‘p1‘), helloNode = p1.firstChild.firstChild; worldNode = p1.lastChild; var range = document.createRange(); range.setStart(helloNode, 2); range.setEnd(worldNode, 3); var fragment = range.extractContents(); p1.parentNode.appendChild(fragment);
HTML结果为:
<p><b>He</b>rld!</p> <b>llo</b> wo
cloneContents():创建范围对象的一个副本,然后在文档的其他地方插入该副本
var p1 = document.getELementById(‘p1‘), helloNode = p1.firstChild.firstChild, worldNode = p1.lastChild; var range = document.createRange(); range.setStart(helloNode, 2); range.setEnd(worldNode, 3); var fragment = range.cloneContents();//返回范围的文档片段,但是是副本,原来的实际文档片段还在 p1.parentNode.appendChild(fragment);
现在HTML为:
<p><b>Hello</b> World!</p> <b>llo</b> wo
(4).插入DOM范围中的内容:
insertNode():向范围选区的开始处插入一个节点,假设想为前面例子中的HTML前面插入以下HTML代码:
<span style="color: red">Inserted text</span>
var p1 = document.getElementById(‘p1‘), helloNode = p1.firstChild.firstChild, worldNode = p1.lastChild; var range = document.createRange(); range.setStart(helloNode, 2); range.setEnd(worldNode, 3); var span = document.createElement(‘span‘); span.style.color = ‘red‘; span.appendChild(document.createTextNode("Inserted text")); range.insertNode(span);
得到的HTML代码为:
<p id="p1"><b>He<span style="color:red">Inserted text</span>llo</b> World!</p>
surroundContents(node):环绕范围插入内容,node为环绕范围内容的节点。在环绕范围插入内容时,后台会执行下列操作:
提取出范围中的内容(类似执行extractContent())
将给定节点插入到文档原来范围所在的位置上
将文档片段的内容添加到给定节点中
可以使用这种技术来突出显示网页中某些词句:
var p1 = document.getElementById(‘p1‘), helloNode = p1.firstChild.firstChild, lastNode = p1.lastChild; var range = document.createRange(); range.selectNode(helloNode); //选中Hello文本节点 var span = document.createElement(‘span‘); span.style.backgroundColor = "yellow"; range.surroundContents(span);
这样会给范围选区加上一个黄色背景HTML代码如下:
<p id="p1"><b><span style="background-color:yellow">Hello</span></b> World!</p>
(5).折叠DOM范围:范围中未选择文档的任何部分,折叠范围时其位置会落在文档中的两个部分之间,可能是范围选区的开始位置也可能是结束位置
collapse(flag):布尔值表示要折叠到范围的哪一端,参数true表示要折叠到范围的起点,参数false表示要折叠到范围的终点。要确定范围已经折叠完毕可以检查collapsed属性。
range.collapse(true); //折叠到起点 console.log(range.collapsed); //输出true
检测某个范围是否处于折叠状态,可以帮我们确定范围中的两个节点是否紧密相邻,比如下面HTML代码:
<p id="p1">Paragraph 1</p><p>Paragraph 2</p>
如果我们不知道其实际构成(比如说这段代码是动态生成的),那么可以像下面这样创建一个范围: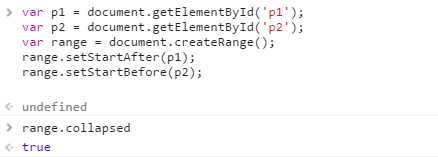
这个例子中新创建的范围是折叠的,因为p1后面和p2前面什么也没有。
(6).比较DOM范围:在有多个范围情况下,可以使用compareBoundaryPoints()方法来确定这些范围是否有公共的边界(起点或终点),两个参数:比较方式的常量值和要比较的范围。常量值如下:
Range.START_TO_START(0):比较第一个范围和第二个范围的起点
Range.START_TO_END(1):比较第一个范围的起点和第二个范围的终点
Range.END_TO_END(2):比较第一个范围和第二个范围的终点
Range.END_TO_START(3):比较第一个范围的终点和第二个范围的起点
该函数返回值为如果第一个范围中的点位于第二个范围中的点之前,返回-1。如果两个点相等返回0,如果第一个范围中的点位于第二个范围中的点之后返回1。
var range1 = document.createRange(); var range2 = document.createRange(); var p1 = document.getElementById(‘p1‘); range1.selectNodeContents(p1); range2.selectNodeContents(p1); range2.setEndBefore(p1.lastChild); range1.compareBoundaryPoints(Range.START_TO_START, range2); // 0 range1.compareBoundaryPoints(Range.END_TO_END, range2); // 1
(7).复制DOM范围:cloneRange()创建调用它的范围的一个副本。新创建的范围和原来的范围包含相同的属性,修改它的端点不会影响原来的范围
(8).清理DOM范围:在使用完范围后,最好调用detach()方法,以便从创建范围的文档中分离出该范围,调用detach之后,就可以放心地解除对范围的引用,从而让垃圾回收机制回收其内存。一旦分离范围就不能再恢复使用了。
range.detach(); //从文档中分离 range = null; //解除引用
2.IE8及更早版本中的范围
即文本范围,文本范围是IE专有特性其他浏览器都不支持,文本范围处理的主要是文本(不一定是DOM节点),通过<body>,<button>,<input>,<textarea>等这几个元素,可以调用createTextRange()方法来创建文本范围。这个方法分别在HTMLBodyElement.prototype,HTMLButtonElement.prototype,HTMLInputElement.prototype,HTMLTextAreaElement.prototype
var range = document.body.createTextRange();
像这样通过document创建的范围可以在页面中的任何地方使用(通过其他元素创建的范围则只能在相应的元素中使用)
(1).用IE范围实现简单的选择:使用findText(str)选择页面中某一区域,这个方法会找到第一次出现的给定文本,并将范围移过来以环绕该文本。如果没有找到文本这个方法返回false,否则返回true。这里的文本不区分大小写。range.text属性返回范围中包含的文本,或者也可以检查findText()返回值(在找到文本情况下返回true)。还可以为findText()传入另一个参数,即一个表示向哪个方向继续搜索的数值。负值表示应该从当前位置向后搜索,正值表示应该从当前位置向前搜索。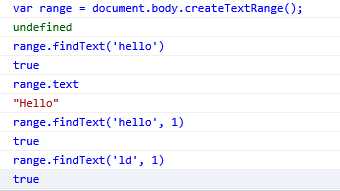
IE中与DOM中selectNode方法最接近的方法是moveToElementText(),这个方法接受一个DOM元素,并且选择该元素所有文本,包括HTML标签。在文本范围中包含HTML情况下,可以使用htmlText属性取得范围的全部内容,包括HTML和文本。
IE的范围没有任何属性可以随着范围选区的变化而动态更新。不过其parentElement()方法倒是与DOM的cummonAncestorContainer属性类似,这样得到的父元素始终都可以反映文本选区的父节点。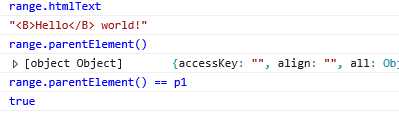
(2).使用IE范围实现复杂的选择:以特定的增量向四周移动范围,这四个方法都接受两个参数:移动单位和移动单位的数量。移动单位是下列一种字符串值:
character:逐个字符地移动
word:逐个单词(一系列非空格字符)地移动
sentence:逐个句子(一系列以句号,问号,叹号结尾的字符)地移动
textedit:移动到当前范围选区的开始或结束位置
move():首先会折叠当前范围(让起点和终点相等),然后再将范围移动指定的单位数量, range.move("character", 5); //移动5个字符 。调用move后范围的起点和终点相同,因此必须再使用moveStart或moveEnd创建新的选区
moveStart():移动范围的起点
moveEnd():移动范围的终点,移动的幅度由单位数量决定
expand():范围规范化,将任何部分选择的文本全部选中,例如假设当前选择的是一个单词中间的两个字符,调用expand("word")可以将整个单词都包含在范围之内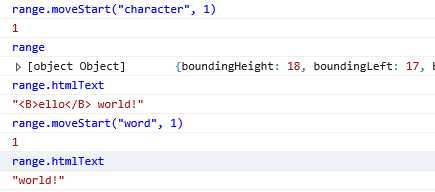
(3).操作IE范围中的内容:操作范围中的内容可以使用text属性或pasteHTML()方法。通过text属性可以取得范围中内容文本,也可通过这个属性设置范围中的内容文本。
向范围中插入HTML代码,使用pasteHTML(str)方法,会用str替换range.text,此时原来的htmlText和text属性均为空字符串,因为被替换了啊。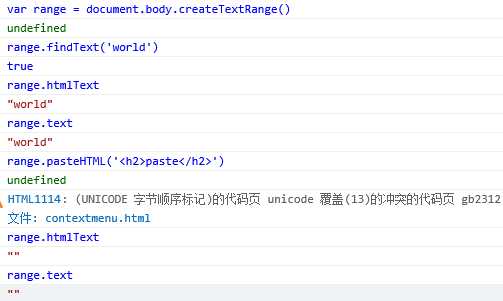
不过在范围中包含HTML代码时不应该使用pasteHTML(),因为这样很容易导致不可预料的结果即很可能是格式不正确的HTML。
(4).折叠IE范围:IE为范围提供的collapse()方法与相应的DOM方法用法一样,传入true把范围折叠到起点,传入false把范围折叠到终点。但没有对应的collapsed属性让我们知道范围是否已经折叠完毕,为此必须使用boundingWidth属性,该属性范围范围的宽度(以像素为单位)。如果等于0说明范围已经折叠了。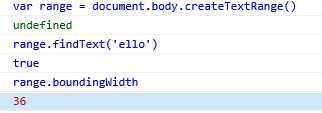
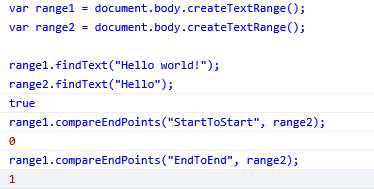
isEqual():用于确定两个范围是否相等
isRange():用于确定一个范围是否包含另一个范围
(6).复制IE范围:duplicate()复制文本范围,结果会创建原范围的一个副本,新创建的范围会带有与原范围完全相同的属性。
参考
《JavaScript高级程序设计》
标签:
原文地址:http://www.cnblogs.com/venoral/p/5471638.html