标签:
标签(空格分隔): LDA DMM DP Dirichlet Dirichlet-Process
- 对于非参数化的机器学习模型,我之前研究的并不多。通过这几天的学习,简单总结一下我所了解到的非参数化的模型。
- 鉴于非参数化的学习模型涉及大量的概率计算,晦涩难懂,然而在这篇总结材料中,我并不细推每个公式,而是以一种感性的方式理解每个模型。有的时候,不,是所有时候,感性的认识比理解其中的公式推导更加深刻有效。
- 如果想了解具体某个模型原理,请大家下载相应论文。相信你如果仔细阅读完本教程,会让你在阅读相关论文时如虎添翼!!!
- 最后,感谢邵华师弟与我的学术交流,对我了解DP有很大帮助。
- Beta分布函数是一种定义在实数区间[0,1]的特殊函数。该分布包含两个参数:a,b,具体分布公式如下:
Beta(x;a,b)=Γ(a+b)Γ(a)Γ(b)xa?1(1?x)b?1(1.1) - 其中
Γ(a) 为gamma函数,是定义在实数区间上的阶乘运算,参数a ,b 又称为伪计数变量,分别代表二项分布中成功与失败的次数。类似于beta函数这类值域为[0,1]的函数又称概率度量函数(probability measure),可以作为其他分布参数的先验分布。如beta分布可以作为二项分布中参数p 的先验分布。二项分布公式为:
B(k;n,p)=(nk)pk(1?p)n?k(1.2)
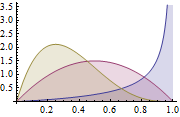
不同的 Beta(a,b) 函数
- 与Beta分布相同,Dirichlet分布也是定义在实数区间[0,1]的概率度量函数,只是Dirichlet分布的值域是Beta分布拓展到高维的情形,其中的参数为一个
K 维向量α ,分布公式如下:
Dir(x? ;α? )=Γ(∑Ki=1x? i)∏Ki=1Γ(x? i)∏i=1Kx? α? i?1i(1.3) - Dirichlet分布可以作为多项式分布中参数向量
p? 的先验分布,多项式分布公式为:
Multi(k? ;n,p? )=(nk? )∏i=1Kp? k? ii(1.4)
- 通过观察二项分布与Beta分布的公式,不难发现其中有很多相似的特点,下面我们来慢慢挖掘二项分布于beta分布的关系。在Bayes理论中,认为二项分布中的参数
p 并不是固定的一个值,而是一个未知的参数。因此,在求某个伯努利事件的时候,不能仅仅利用一个固定的概率值p 来计算,需要枚举所有可能取得的概率值。即:
P(x;n,a,b)=∫pB(x;n,p)Beta(p;a,b)dp(1.5) - 式1.5表示的是:
p 并不只是在取某一个值的时候才能发生事件x ,需要枚举所有可能发生事件x 时的p ,累和所有可能的p 的概率P(p) 及对应发生事件x 时的概率的乘积。在现实世界中,相比P(x) ,我们往往更关心P(p|x) ,因为我们并不关心已经发生的事件的概率,而是关心在已经发生事实的前提下,再发生某事件的概率。根据式子1.5及贝叶斯公式我们可以很容易得到:
P(p|x;n,a,b)=B(x;n,p)Beta(p;a,b)∫p′B(x;n,p′)Beta(p′;a,b)dp′(1.6) - 看到式子1.6,你可能会感到厌倦,因为貌似这个式子特别复杂。但是如果你继续阅读本讲义,你将会非常喜欢这个式子,因为其超级简单。这个式子表示的意思是:用某个特定的
p 计算事件x 发生的概率(分子)除以所有可能的p 发生事x 的累和(分母),相信你读到这里会感觉即使自己不懂贝叶斯公式也应该觉得这个式子是合理的。如果二项分布与Beta分布没有满足共轭关系,则式子1.6将会很难继续化简。但幸运的是二项分布与Bbeta分布相似的表达形式我们可以很快推出以下公式:
P(p|x;n,a,b)=Beta(p;a+x,b+n?x)(1.7) - 其中
x 表示的是某个事件成功地次数,n?x 表示的是某个事件失败的次数。式子1.7表示的意思是:当参数p 先验概率满足Beta分布的时候,并且发生了一系列伯努利事件,则p 的后验概率依旧满足Beta分布,变化的只是伪计数变量。不仅仅Beta分布与二项分布满足这样神奇的关系,dirichlet分布与多项式分布也满足这样的关系,我们称这类关系为两个分布的共轭关系。- 这类关系可以描述为:
先验分布(Beta/Dir)+数据事实(B/Multi)=后验分布(Beta/Dir)
- 虽然,我们假定二项分布中的参数
p 并不是固定,但是人们总希望其最有可能的值是多少。Beta分布与Dirichlet分布的期望如下:
E[Beta(a,b)]=aa+b(1.8)
E[Dir(α? )]=α? ∑Ki=1αi(1.9) - 我们并不打算推倒这个式子,有兴趣可以参考《LDA数学八卦》,我们这里想告诉大家的是:式子1.8与1.9就是将伪计数当做真实事件计数时的最大似然估计。也就是最简单的计数方法:某个事件发生的次数除以所有事件发生的总次数。
这个例子非常重要,它是我们之后学习LDA模型和DP模型的基础,建议大家仔细阅读。
- 假设一篇文档
D 由n 个不同单词组成,并且文档产生某个单词的概率符合Dirichlet分布D~Dirichlet(α? ) ,我们想知道在已经观察到该文档的前提下,计算产生每个单词的概率(期望)E[p? |D] 。- 令
x? 为n 维向量,每一维代表对应单词在文档D 中出现的次数,则:
P(p? │D)=Dir(α? +x? )(1.10) E[p? │D]=(α? +x? )∑Ki=1α? i+x? i(1.11) - 式1.11就是我们的答案,表示的意思是:单词i发生的概率为
α? i+x? i∑Kj=1α? j+x? j ,就是简单的伪计数所占的比例。如果参数α? 不是一个向量,而是一个常数,则代表向量中的每一维均等于α 。此时式子1.11变成:
E[p? │D]=α+x? ∑Ki=1(x? i+nα)(1.12) - 如果你了解LDA最后的采样公式,相信你对式子1.12并不陌生。如果你不了解它,请花费几分钟时间理解它的含义。
- LDA模型认为每篇文档由
K 个主题构成,每个主题由V 个单词构成,V 代表整个语料集单词的个数。因此,在产生某个单词的时候,先要确定所使用的topic,再计算该topic产生该词的概率。使用吉普斯采样的时候要把单词作为最小单元,遍历每个单词进行采样。- 假设语料集中一共有J篇文档,K个主题,则对应的LDA模型总共包括J+K个Dirichlet-Multinomial共轭关系。每篇文档与topic的关系对应一个Dirichlet-Multinomial共轭关系,每个topic与单词的关系对应一个Dirichlet-Multinomial共轭关系。因此论文中提到LDA时总说,文档与topic的关系是针对每篇文档的,topic与单词的对应关系则针对整个数据集,跨越文档的界限,或者说文档中的topic与word的关系是共享的。
- 如果以上两段都看不懂也可以忽略。我们下面以感性的方式来得出LDA的训练过程。
- LDA最终的目标是将每篇文档中的每个词赋予一个topic标签,采样的过程就是不断地按照某种策略将语料中的每个单词赋予新的标签,最终收敛,即所有赋予同一个topic的词的比例不在变化,所有文档topic的比例不在变化。
- 由于文档与topic的Dirichlet-Multinomial共轭关系,回忆1.5节的例子,文档产生某个topic的概率为:
E[t=k│D=d]=α? d,k+n? d,k∑Kj=1(α? d,j+n? d,j)(2.1) - 式子2.1分母就是文档
d 的长度,分子为其中属于主题k 词数。同理,某个主题产生某个单词的概率为:
E[w=i│t=k]=β? k,i+m? k,i∑Vj=1(β? k,j+m? k,j)(2.2) - 式子2.2分母就是真个语料集属于主题
k 的词数,分子表示为主题k 中单词i 发生的次数。文档使用主题t=k 产生的某个词w=i 的概率为:
P(t=k,w=i│D=d)=E[t=k│D=d]×E[w=i│t=k] =α? d,k+n? d,k∑Kj=1(α? d,j+n? d,j)β? k,i+m? k,i∑Vj=1(β? k,j+m? k,j)(2.3) - 其中,
n? 与m? 分别代表文档中各个topic的数量与主题t中各个单词的出现次数。这个式子是不是很像吉普斯采样的采样公式?吉普斯采样的过程中要求,采样的转移概率为固定其它维坐标的值,该维变量在各个取值下的条件概率。LDA采样过程中将每一个单词(可重复)当作一维坐标,其不同的topic代表不同的取值,因此采样的转移概率如2.4所示:
P(t=k│w=i,D=d)∝P(t=k,w=i│D=d) =α? d,k+n? d,k,┐w∑Kj=1(α? d,j+n? d,j,┐w)β? k,i+m? k,i,┐w∑Vj=1(β? k,j+m? k,j,┐w)(2.4) - 式子2.4与2.3形式完全相同只是参数
n? ,m? 意义稍微有点改变,2.4中的┐w 代表除去w 这个词所统计的所有变量。- 因此,LDA具体过程如下:
- 随机初始化各个单词的topic,并统计变量
nd,k,┐w 与mk,i,┐w 的值。- 遍历每篇文档的每个单词
w ,按照公式2.4采样w 对应的新的topic,并更新nd,k,┐w 与mk,i,┐w 。- 重复步骤2,直至收敛。
- 小孩计数的方式求出每篇文档的topic分布与topic的单词分布。
- LDA模型假设文档由多个topic共同生成,然而在处理短文本的时候效果并不理想。短文本往往长度较短,只能表达单一的一个主题,因此LDA的假设显然不合理。DMM模型思想与LDA相同,但它认为每篇文档只由一个主题生成,因此,我们采样topic的时候不能再像LDA一样对每个单词采样,而是对整个文档采样,即把文档作为采样的最小单元。
- 我们下面以感性的方式来分析DMM模型的训练过程。
- 假设语料集
C 中一共有J 篇文档,K 个主题,则对应的DMM模型总共包括1+K 个Dirichlet-Multinomial共轭关系。1 代表的是语料集与主题的Dirichlet-Multinomial共轭关系,K 表示的是每个主题与单词对应的Dirichlet-Multinomial共轭关系。- 依旧回忆1.5小节的例子,我们可以求出语料集产生某个主题的概率为:
E[t=k│C]=α? k+n? k∑Kj=1(α? j+n? j)(3.1) - 然而,由于
K 代表的是主题与单词的共轭关系,对于文档我们不能直接套用1.5小节的例子。但我们知道文档的生成概率为文档中所有单词的条件概率的乘积。所以我们有:
wd,<j={wd1,wd2,…,wd(j?1)} E[d│t=k,C?d]=∏jP(wdj|t=k,C?d,wd,<j)(3.2) P(wdj=i|t=k,C?d,wd,<j)=β? k,i+m? k,i,┐≥wdj∑Vl=1(β? k,l+m? k,l,┐≥wdj)(3.3) - 其中
ml,┐≥wdj 表示除去wdj 以及文档中wdj 之后的所有词。式子3.2就是我们要求的式子,而3.3表示的是:当求w 所对应的概率的时候,我们把文档中出现在w 之前的均为已经发生的事实,而词w 与w 之后的所有词需要从中除去。我们再简单的对3.2与3.3变个形式。设N┐d,k 表示主题k 中除去文档d 的所有词数;N┐d,k,i 表示主题k 中除去文档d后,单词i 所出现次数;Nd,k,i,<j 表示文档d中主题k ,在第j 个单词之前出现单词i 的次数。则:
P(wdj=i|t=k,C?d,wd,<j)=β? k,i+N┐d,k,i+Nd,k,i,<j∑Vl=1(β? k,l+N┐d,k,l)+j?1(3.4) E[d│t=k,C?d]=∏Vl=1{(β? k,l+N┐d,k,l)×(β? k,l+N┐d,k,l+1)×...×(β? k,l+N┐d,k,l+Nd,k,l?1)}{∑Vl=1(β? k,l+N┐d,k,l)}×{∑Vl=1(β? k,l+N┐d,k,l)+1}×...×{∑Vl=1(β? k,l+N┐d,k,l)+|d|?1}(3.5) - 仔细阅读,你会发现公式3.4是公式3.3的另一种写法而已,结合式子3.2与3.4便可以很容易得到式子3.5。如果将式子3.5用人类语言去描述将会非常容易理解,用数学语言太难写而且不容易被人接受。式子3.5分母表示的是文档长度个连乘操作,分子表示的是每个单词在文档中出现次数的连乘操作的乘积。观察式子3.5,我们发现分子分母都是连乘操作,如果把
1 到(β? k,l+N┐d,k,l?1) 之间的数字补全,就是阶乘操作伽马函数的形式。
E[d│t=k,C┐d]=∏Vl=1Γ(β? k,l+N┐d,k,l+Nd,k,l)Γ(β? k,l+N┐d,k,l)Γ(∑Vl=1(β? k,l+N┐d,k,l)+|d|)Γ(∑Vl=1(β? k,l+N┐d,k,l)) =Γ(∑Vl=1(β? k,l+N┐d,k,l))∏Vl=1Γ(β? k,l+N┐d,k,l+Nd,k,l)Γ(∑Vl=1(β? k,l+N┐d,k,l)+|d|)∏Vl=1Γ(β? k,l+N┐d,k,l)(3.6) - 式子3.6就是论文中提到的最终的式子,但是3.6已经很难以感性进行认识,反而由多个3.4乘积组成的3.5更容易被人理解。
- 最后语料集中由主题
k 产生文档d 的概率为:
P(t=k,d│C┐d)=E[t=k│C┐d]×E[d│t=k,C┐d](3.7) - 因此DMM具体过程如下:
- 随机初始化各个文档的topic,并统计变量
nk,┐w 与mk,i,┐w≥dj 的值。- 遍历每篇文档d,按照公式3.6采样d对应的新的topic,并更新
nk,┐w 与mk,i,┐w≥dj 。- 重复步骤2,直至收敛。
- 小孩计数的方式求出语料集的topic分布与topic的单词分布。
- Dirichlet process可以用来确定聚类的个数,或者说topic的个数。Dirichlet process分布的正式定义比较抽象,比如在概率函数空间下的一种分布。其实通俗来讲很简单。普通的dirichlet分布需要提供变量的维数K,比如topic个数,之后dirichlet分布表示的是各个概率分布的概率有多大。而Dirichlet process分布无需为之提供变量的维数,而是把变量维数变成一种随机变量,对于每一种K都提供对应的每一种概率分布的概率。如果只考虑Dirichlet process分布中K取某一个固定值的情况时,Dirichlet process与Dirichlet分布相同,因此,文献中总说,Dirichlet process是Dirichlet分布的一种无穷划分,换句话说,对Dirichlet process分布求出变量维数的边缘概率要符合Dirichlet分布。
- Dirichlet process是比较抽象的,我们很难通过定义理解其中的分布含义。那么,现实世界中有哪些例子,是符合Dirichlet process分布的呢?最经典的三个例子已经被人们广为流传:中国餐馆过程(Chinese Restaurant Process),罐子里抽球(Blackwell-MacQueen Urn Scheme)的过程,拆木棍(Stick-breaking)过程。
- 由于中国餐馆过程与罐子里抽球的过程本质上是一致的,因此,本文主要讲中国餐馆过程和拆木棍过程。
中国餐馆过程算法如下:
刚开始的时候餐馆里没有人;
第一个客人坐到第1 个桌子;
第n+1 个客人有两种选择:以
α/(n+α) 的概率坐在一个新桌子上,α 为Dirichlet process 参数
以ck/(n+α) 的概率坐在第k 个旧桌子上,其中ck 为目前第k 个桌子上的人数由上述过程,我们可以发现这个过程需要一个参数
α ,代表产生一个新类(桌子)的可能性,越大越容易产生新的桌子。聚在一个桌子上的客人会共享桌子上的菜,因此同一个桌子上的人应该有某种共性,这样才有意义。事实上,每一张桌子都具有一种概率分布,正是因为这种概率分布才使得这一桌子的人聚在一起。如果最后有K 张桌子,则对应K 个概率分布F1 ,F2 ,… ,Fk 。
那么这K 个概率分布是怎么产生的呢?它是由一个新的分布H 产生的K 个样本,而这个H 是Dirichlet process的一个参数,只不过这个参数是以分布的形式存在着,并且通常情况是Dirichlet 分布。或许这个时候,你有一些迷茫,不要慌张,我们重新审视一下中国餐馆过程。中国的餐馆有很多种,比如川菜馆,东北菜馆,湘菜馆等等,分布 H 就对应其中的一个餐馆,比如说是川菜馆。那么当你来到一个川菜馆的时候,你可能会因为喜欢和某一桌子上的人一起吃饭,也有可能坐在新桌子上。假设最后一共坐满了K 个桌子,虽然都是川菜馆,但是每个桌子点的菜都不一样,每个桌子就对应不同的K 个分布之一。但是,这K 个桌子又不能说完全没有联系,因为毕竟他们点的必须都是川菜。概率分布F 并不属于Dirichlet process的范围,通常它是多项式分布,这个多项式分布的参数的先验分布服从Dirichlet process分布。由于每天餐馆的生意不同,来的人数及桌子的个数,客人的分配方式都不同,因此每天的生意,或者说每一次中国餐馆过程只是最终的Dirichlet process与F 分布共同作用产生的样本而已。综上,Dirichlet process应该包含两个参数: α (标量)与H (概率分布)。Dirichlet Process主要贡献主要有以下几种(自己的感受而已,并不一定准确):
- 按照权重
α 以某种策略对样本进行分类,每一类具有相同的概率分布,分类个数一般在αlog2n 级别。- 虽然Dirichlet Process是一种概率分布的分布(measure distribution),但是其并没有自己的分布函数,而是依赖概率分布函数
H 产生的样本分布(一种概率的分布),Dirichlet Process的作用只是在现有的样本分布中做手脚,控制每个概率分布(H 产生的样本分布)所包含的现实中的样本比例而已。- 通常情况下
H 是一个连续的函数,如果产生N 个样本分布,往往这N个样本分布是不同的,但是Dirichlet Process是离散函数,虽然离散点的个数可以是无穷的(桌子的个数)。但是,一旦桌子的个数K 最终确定,所有的样本的概率分布只能符合K 个概率分布中的一个,因此,Dirichlet Process某种意义上可以缩小H 分布的样本空间范围。后面要讲的HDP就是利用这种特性达到的Topic文档共享。- 期望与方差满足:
E(DP(α,H))=H,Var(DP(α,H))=H×(1?H)α+1 。
- 相信,如果你认真读完中国餐馆过程应该已经对Dirichlet process有了初步的认识。然而,有一个问题很难从中国餐馆过程中找到答案。这个问题就是:当所有客人都已经就位后,到底人数第一多的桌子做了多少人,第二多的坐了多少人…?
这木棍过程可以告诉你这个答案,即每一桌子上的人数占所有人数的比例。
具体算法如下:
- 刚开始有一根长度为
1 的木棍。- 在木棍的
β1 处将它折断,从头到β1 处的长度为π1 。- 将剩下的
1?π1 的木棍按照步骤2继续折断,得到π2 。将剩下的木棍,长度为
1?∑j<iπj ,重复步骤2的过程,得到πi 。显然,木棍的折断过程是无穷多次的,对应了无穷个类别。
πi 就代表第i 个类别所包含的样本比例。上述过程中πk=βk∏k?1i=1(1?βi) ,βk~Beta(1,α) 。
了解完Dirichlet process分布后,我们需要根据已有的事实来推断Dirichlet Process的参数
α (标量)与H (概率分布)。回忆1.5小节的例子与DMM模型的过程,因为DP模型处理文本时就是DMM模型+自动确定topic个数。当把H 分布设定为Dirichlet分布时,H~Dir(β) ,使用中国餐馆过程,把文档当作一个客人,计算一个新的文档d 由主题k 产生的概率为:
p(td=k│C,α,β)=???ck|C|?1+αfold(k)α|C|?1+αfnew(k)if k existsif k not exists(4.1)
*fold(k) 非常简单,因为它完全退化成由DMM模型中某个主题单词的Dirichlet-Multinomial共轭关系产生一个文档的生成概率,见公式3.5或3.6;fnew(k) 则更简单,它是公式3.5或3.6中∑Vl=1N┐d,k,l=0 的情况。
本文主要介绍了常用的beta函数与Dirichlet函数,并且介绍了对应的共轭关系。以感性的方式讲解了LDA DMM DP模型。还有一个比较重要的模型叫做HDP,是LDA+自动确定主题个数的方法,请待下回分解!
标签:
原文地址:http://blog.csdn.net/yongheng5871/article/details/51405817