标签:
topology代码 | |
conf.setNumWorkers(2)//进程 topologyBuilder.setSpout("blue-spout",new Blue(),2)//线程 topologyBuilder.setBolt("green-spot",new Green(),2) .setNumTasks(4) .shuffleGrouping("blue-sqout")//线程、对象 topologyBuilder.serBolt("yellow-sqout",new Yellow(),6) .shuffleGrouping("green-bolt") | 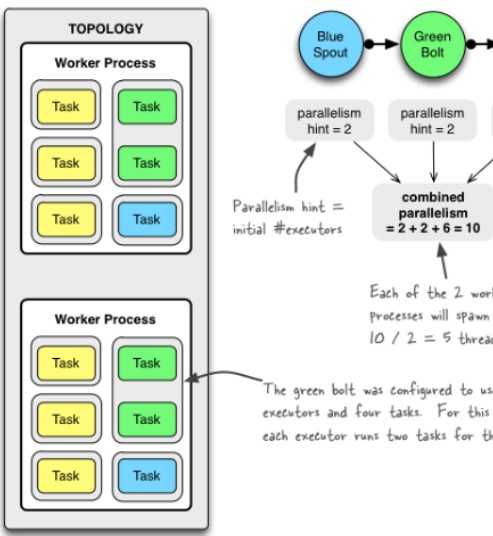 |
标签:
原文地址:http://www.cnblogs.com/my-cup/p/5507084.html