标签:
投影三维点到图像平面
void cvProjectPoints2( const CvMat* object_points, const CvMat* rotation_vector,
const CvMat* translation_vector, const CvMat* intrinsic_matrix,
const CvMat* distortion_coeffs, CvMat* image_points,
CvMat* dpdrot=NULL, CvMat* dpdt=NULL, CvMat* dpdf=NULL,
CvMat* dpdc=NULL, CvMat* dpddist=NULL );

函数cvProjectPoints2通过给定的内参数和外参数计算三维点投影到二维图像平面上的坐标。另外,这个函数可以计算关于投影参数的图像点偏导数的雅可比矩阵。雅可比矩阵可以用在cvCalibrateCamera2和cvFindExtrinsicCameraPar
计算两个平面之间的透视变换
void cvFindHomography( const CvMat* src_points,
const CvMat* dst_points,
CvMat* homography );
函数cvFindHomography计算源平面和目标平面之间的透视变换 .
.

使得反投影错误最小:

这个函数可以用来计算初始的内参数和外参数矩阵。由于Homography矩阵的尺度可变,所以它被规一化使得h33
利用定标来计算摄像机的内参数和外参数
void cvCalibrateCamera2( const CvMat* object_points, const CvMat* image_points,
const CvMat* point_counts, CvSize image_size,
CvMat* intrinsic_matrix, CvMat* distortion_coeffs,
CvMat* rotation_vectors=NULL,
CvMat* translation_vectors=NULL,
int flags=0 );
,如果指定CV_CALIB_USE_INTRINSIC_GUESS和(或)CV_CALIB_FIX_ASPECT_RATION,fx、fy、
cx和cy部分或者全部必须被初始化。函数cvCalibrateCamera2从每个视图中估计相机的内参数和外参数。3维物体上的点和它们对应的在每个视图的2维投影必须被指定。这些可以通过使用一个已知几何形状且具有容易检测的特征点的物体来实现。这样的一个物体被称作定标设备或者定标模式,OpenCV有内建的把棋盘当作定标设备方法(参考cvFindChessboardCorners)。目前,传入初始化的内参数(当CV_CALIB_USE_INTRINSIC_GUESS不被设置时)只支持平面定标设备(物体点的Z坐标必须为全0或者全1)。不过3维定标设备依然可以用在提供初始内参数矩阵情况。在内参数和外参数矩阵的初始值都计算出之后,它们会被优化用来减小反投影误差(图像上的实际坐标跟cvProjectPoints2计算出的图像坐标的差的平方和)。
计算指定视图的摄像机外参数
void cvFindExtrinsicCameraParams2( const CvMat* object_points, const CvMat* image_points, const CvMat* intrinsic_matrix, const CvMat* distortion_coeffs, CvMat* rotation_vector, CvMat* translation_vector );
。
函数cvFindExtrinsicCameraPar
进行旋转矩阵和旋转向量间的转换
int cvRodrigues2( const CvMat* src, CvMat* dst, CvMat* jacobian=0 );
函数转换旋转向量到旋转矩阵,或者相反。旋转向量是旋转矩阵的紧凑表示形式。旋转向量的方向是旋转轴,向量的长度是围绕旋转轴的旋转角。旋转矩阵R,与其对应的旋转向量r,通过下面公式转换:



反变换也可以很容易的通过如下公式实现:

旋转向量是只有3个自由度的旋转矩阵一个方便的表示,这种表示方式被用在函数cvFindExtrinsicCameraPar
校正图像因相机镜头引起的变形
void cvUndistort2( const CvArr* src, CvArr* dst,
const CvMat* intrinsic_matrix,
const CvMat* distortion_coeffs );
。函数cvUndistort2对图像进行变换来抵消径向和切向镜头变形。相机参数和变形参数可以通过函数cvCalibrateCamera2取得。使用本节开始时提到的公式,对每个输出图像像素计算其在输入图像中的位置,然后输出图像的像素值通过双线性插值来计算。如果图像得分辨率跟定标时用得图像分辨率不一样,fx、fy、cx和cy需要相应调整,因为形变并没有变化。
计算形变和非形变图像的对应(map)
void cvInitUndistortMap( const CvMat* intrinsic_matrix,
const CvMat* distortion_coeffs,
CvArr* mapx, CvArr* mapy );
函数cvInitUndistortMap预先计算非形变对应-正确图像的每个像素在形变图像里的坐标。这个对应可以传递给cvRemap函数(跟输入和输出图像一起)。
寻找棋盘图的内角点位置
int cvFindChessboardCorners( const void* image, CvSize pattern_size,
CvPoint2D32f* corners, int* corner_count=NULL,
int flags=CV_CALIB_CB_ADAPTIVE_THRESH );
函数cvFindChessboardCorners试图确定输入图像是否是棋盘模式,并确定角点的位置。如果所有角点都被检测到且它们都被以一定顺序排布(一行一行地,每行从左到右),函数返回非零值,否则在函数不能发现所有角点或者记录它们地情况下,函数返回0。例如一个正常地棋盘图右8x8个方块和7x7个内角点,内角点是黑色方块相互联通地位置。这个函数检测到地坐标只是一个大约地值,如果要精确地确定它们的位置,可以使用函数cvFindCornerSubPix。
绘制检测到的棋盘角点
void cvDrawChessboardCorners( CvArr* image, CvSize pattern_size,
CvPoint2D32f* corners, int count,
int pattern_was_found );
当棋盘没有完全检测出时,函数cvDrawChessboardCorners以红色圆圈绘制检测到的棋盘角点;如果整个棋盘都检测到,则用直线连接所有的角点。
初始化包含对象信息的结构
CvPOSITObject* cvCreatePOSITObject( CvPoint3D32f* points, int point_count );
函数 cvCreatePOSITObject 为对象结构分配内存并计算对象的逆矩阵。
预处理的对象数据存储在结构CvPOSITObject中,只能在OpenCV内部被调用,即用户不能直接读写数据结构。用户只可以创建这个结构并将指针传递给函数。
对象是在某坐标系内的一系列点的集合,函数 cvPOSIT计算从照相机坐标系中心到目标点points[0] 之间的向量。
一旦完成对给定对象的所有操作,必须使用函数cvReleasePOSITObject释放内存。
执行POSIT算法
void cvPOSIT( CvPOSITObject* posit_object, CvPoint2D32f* image_points,
double focal_length,
CvTermCriteria criteria, CvMatr32f rotation_matrix,
CvVect32f translation_vector );
函数 cvPOSIT执行POSIT算法。图像坐标在摄像机坐标系统中给出。焦距可以通过摄像机标定得到。算法每一次迭代都会重新计算在估计位置的透视投影。
两次投影之间的范式差值是对应点中的最大距离。如果差值过小,参数criteria.epsilon就会终止程序。
释放3D对象结构
void cvReleasePOSITObject( CvPOSITObject** posit_object );
函数 cvReleasePOSITObject 释放函数 cvCreatePOSITObject分配的内存。
计算长方形或椭圆形平面对象(例如胳膊)的Homography矩阵
void cvCalcImageHomography( float* line, CvPoint3D32f* center,
float* intrinsic, float* homography );
函数 cvCalcImageHomography 为从图像平面到图像平面的初始图像变化(defined by 3D oblongobject line)计算Homography矩阵。
由两幅图像中对应点计算出基本矩阵
int cvFindFundamentalMat( const CvMat* points1,
const CvMat* points2,
CvMat* fundamental_matrix,
int method=CV_FM_RANSAC,
double param1=1.,
double param2=0.99,
CvMat* status=NULL);
对极几何可以用下面的等式描述:

其中 F 是基本矩阵,p1
函数 FindFundamentalMat利用上面列出的四种方法之一计算基本矩阵,并返回基本矩阵的值:没有找到矩阵,返回0,找到一个矩阵返回1,多个矩阵返回3。计算出的基本矩阵可以传递给函数cvComputeCorrespondEpili
例子1:使用 RANSAC 算法估算基本矩阵。
int numPoints = 100;
CvMat* points1;
CvMat* points2;
CvMat* status;
CvMat* fundMatr;
points1 = cvCreateMat(2,numPoints,CV_32F);
points2 = cvCreateMat(2,numPoints,CV_32F);
status = cvCreateMat(1,numPoints,CV_32F);
fundMatr = cvCreateMat(3,3,CV_32F);
int num = cvFindFundamentalMat(points1,points2,fundMatr,CV_FM_RANSAC,1.0,0.99,status);
if( num == 1 )
printf("Fundamental matrix was found\n");
else
printf("Fundamental matrix was not found\n");
例子2:7点算法(3个矩阵)的情况。
CvMat* points1;
CvMat* points2;
CvMat* fundMatr;
points1 = cvCreateMat(2,7,CV_32F);
points2 = cvCreateMat(2,7,CV_32F);
fundMatr = cvCreateMat(9,3,CV_32F);
int num = cvFindFundamentalMat(points1,points2,fundMatr,CV_FM_7POINT,0,0,0);
printf("Found %d matrixes\n",num);
为一幅图像中的点计算其在另一幅图像中对应的对极线。
void cvComputeCorrespondEpilines( const CvMat* points, int which_image, const CvMat* fundamental_matrix, CvMat* correspondent_lines);
函数 ComputeCorrespondEpiline

其中F是基本矩阵,p1

其中p2

归一化后的对极线系数存储在correspondent_lines 中。
Convert points to/from homogenious coordinates
void cvConvertPointsHomogenious( const CvMat* src, CvMat* dst );
The function cvConvertPointsHomogenio
If the output array dimensionality is larger, an extra 1 isappended to each point.
(x,y[,z]) -> (x,y[,z],1)
Otherwise, the input array is simply copied (with optionaltranposition) to the output. Note that, because the functionaccepts a large variety of array layouts, it may report an errorwhen input/output array dimensionality is ambiguous. It is alwayssafe to use the function with number of points N>=5, or to usemulti-channel Nx1 or 1xN arrays.
分享:


k1和k2是径向形变系数,p1和p1是切向形变系数。OpenCV中没有考虑高阶系数。形变系数跟拍摄的场景无关,因此它们是内参数,而且与拍摄图像的分辨率无关。
后面的函数使用上面提到的模型来做如下事情:
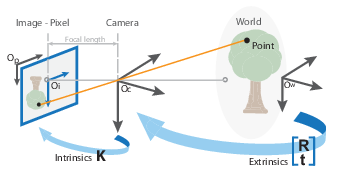
如上图表示的三个坐标系分别为世界坐标系,摄像机坐标系,图像坐标系
1:世界坐标系(Xw
2:摄像机坐标系(Xc
以相机的光心作为原点,Zc轴与光轴重合,并垂直于成像平面,且取摄影方向为正方向,Xc、Yc轴与图像物理坐标系的x,y轴平行,且OcO为摄像机的焦距f
3:图像坐标系
是以图像的左上方为原点,的图像坐标系(uv)(此坐标以像素为单位),这里我们建立了图像物理坐标系(x y)为xoy坐标系(此坐标系以毫米为单位)。
标签:
原文地址:http://blog.csdn.net/q123456789098/article/details/51451723
