标签:
一、前言
前一段时间,小小的写了一个爬虫,是关于电商网站的。今天,把它分享出来,供大家参考,如有不足之处,请见谅!(抱拳)
二、准备工作
我们实现的这个爬虫是Java编写的。所用到的框架或者技术如下:
Redis:分布式的Key-Value数据库,用来作存储临时的页面URL的仓库。
HttpClient:Apache旗下的一款软件,用来下载页面。
HtmlCleaner&xPath:网页分析软件,解析出相关的需要的信息。
MySQL数据库:用于存储爬取过来的商品的详细信息。
ZooKeeper:分布式协调工具,用于后期监控各个爬虫的运行状态。
三、业务需求
抓取某电商商品详细信息,需要的相关字段为:商品ID、商品名称、商品价格、商品详细信息。
四、整体架构布局
首先是我们的核心部分——爬虫程序。爬虫的过程为:从Redis数据仓库中取出URL,利用HttpClient进行下载,下载后的页面内容,我们使用HtmlCleaner和xPath进行页面解析,这时,我们解析的页面可能是商品的列表页面,也有可能是商品的详细页面。如果是商品列表页面,则需要解析出页面中的商品详细页面的URL,并放入Redis数据仓库,进行后期解析;如果是商品的详细页面,则存入我们的MySQL数据。具体的架构图如下:
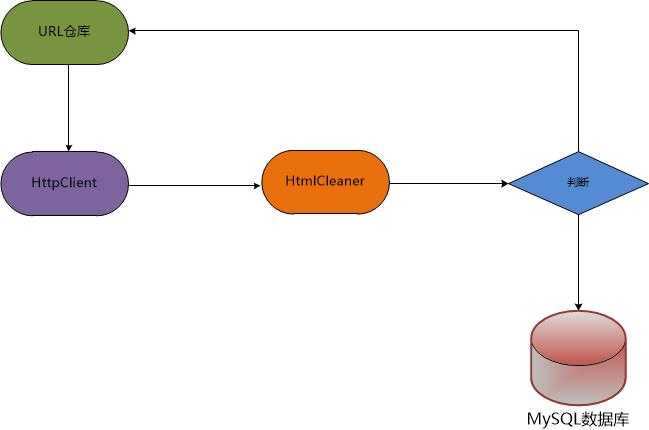
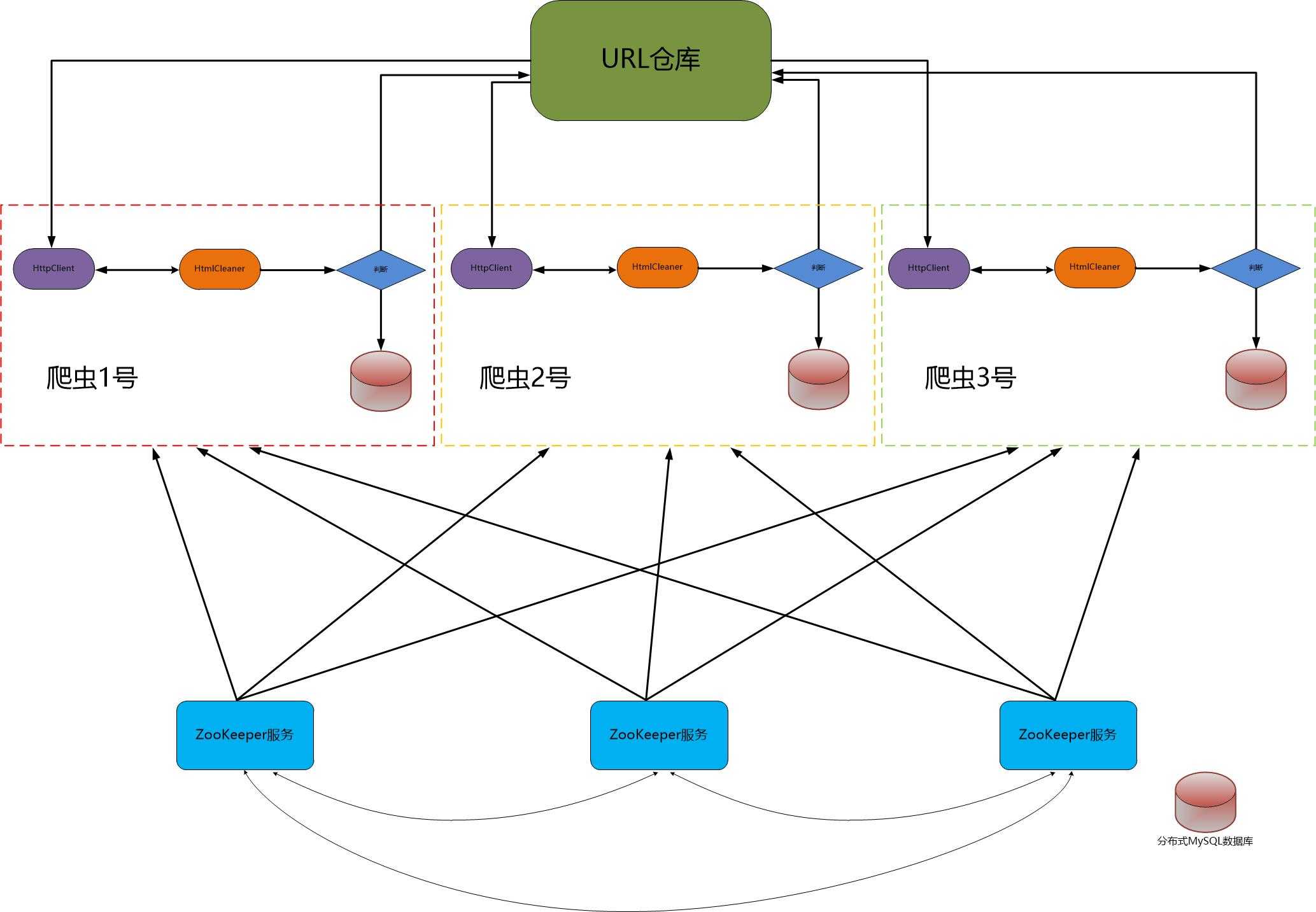
当核心程序爬虫编写完后,为了加快页面抓取效率,我们需要对爬虫进行改进:一是对爬虫程序进行多线程改造;二是将爬虫部署到多台服务器,进一步加快爬虫的抓取效率。以下是整个爬虫项目的架构图:
标签:
原文地址:http://www.cnblogs.com/cstzhou/p/5513816.html